Introduction to FATE - Longitudinal SecureBoost Model
0, demo description
Hetero_secureboost cases used, roles and data: (1) guest: breast_hetero_guest.csv (2) host: breast_hetero_host.csv.
Reference source: https://github.com/FederatedAI/FATE/tree/master/examples/dsl/v2/hetero_secureboost
1. Model training
1. Submit the job for model training using the following command:
flow job submit -c ${runtime_config} -d ${dsl}
#配置文件为:
Binary-Class:
example-data: (1) guest: breast_hetero_guest.csv (2) host: breast_hetero_host.csv
dsl: test_secureboost_train_dsl.json
runtime_config: test_secureboost_train_binary_conf.json
2. Analysis of training details:
Reference source: https://github.com/FederatedAI/FATE/blob/master/examples/experiment_template/user_usage/pipeline_predict_tutorial.md )
https://github.com/FederatedAI/FATE/blob/master/python/fate_client/flow_client/README_zh.rst
The training consists of the following stages, which are performed by the corresponding components:
- reader: read raw data;
- dateio: convert data to instance samples;
- Intersection: Find the intersection of the host and the guest;
- HeteroSecureBoost: tree model;
- evaluation: Evaluation metrics.
You can view modeling information from http://hostip:8080/ fateboard panel:
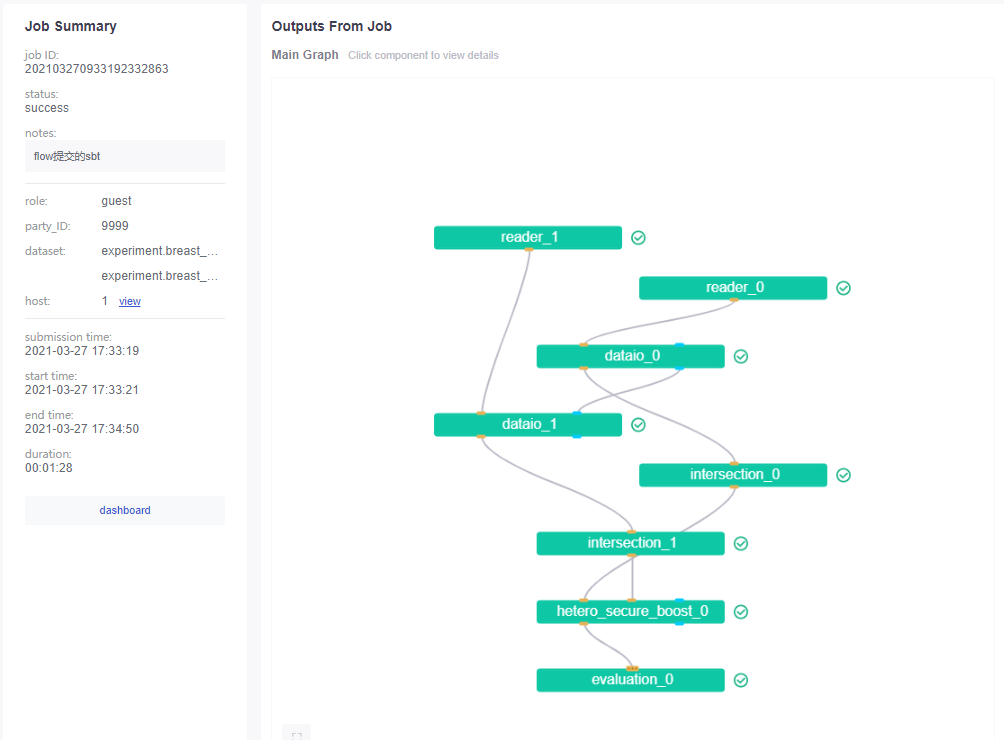
Here _0_1 refers to the training and validation datasets, but the examples in the example are all the same data, so they will have the same dataouput.
In fact, the training of the first tree is to use their respective labels.(to be verified)
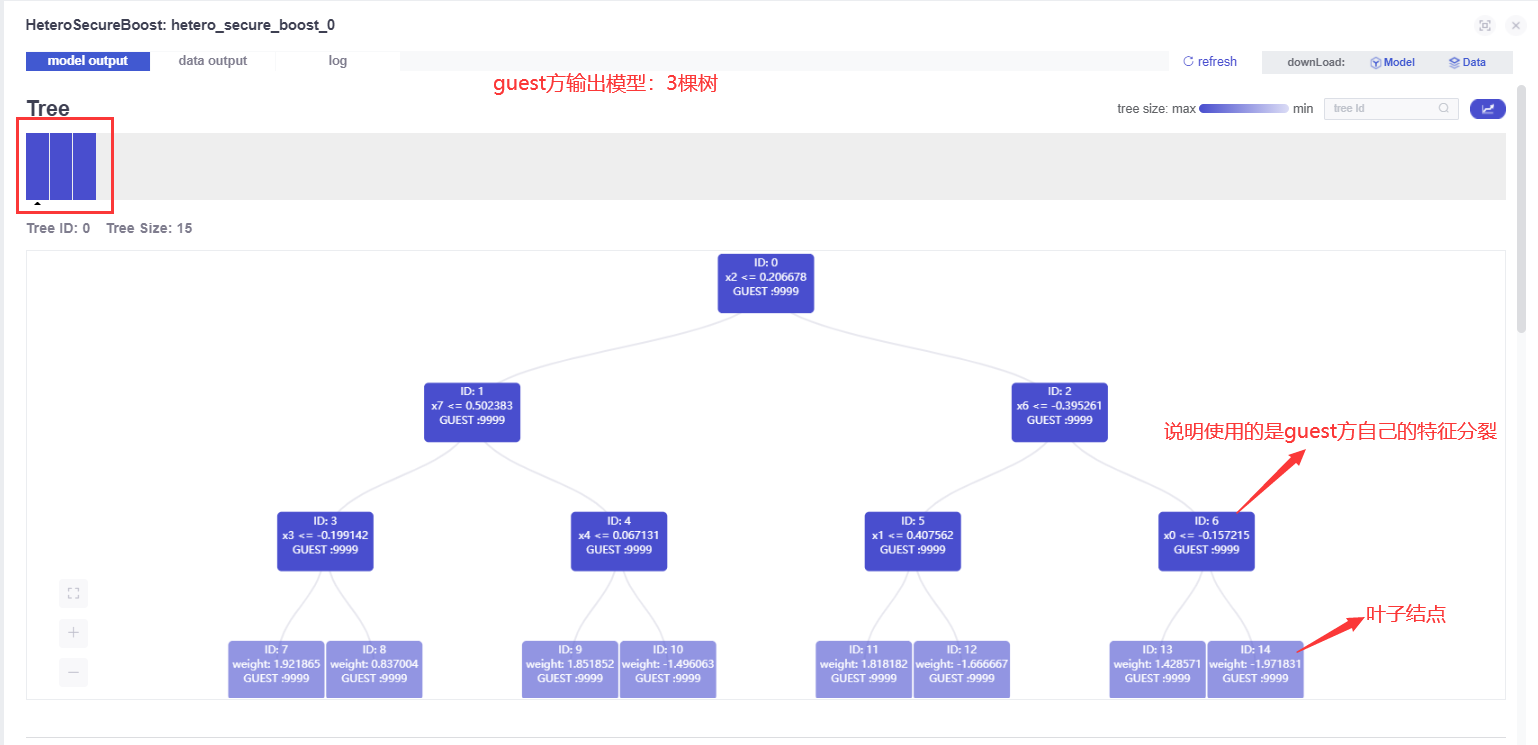
model output
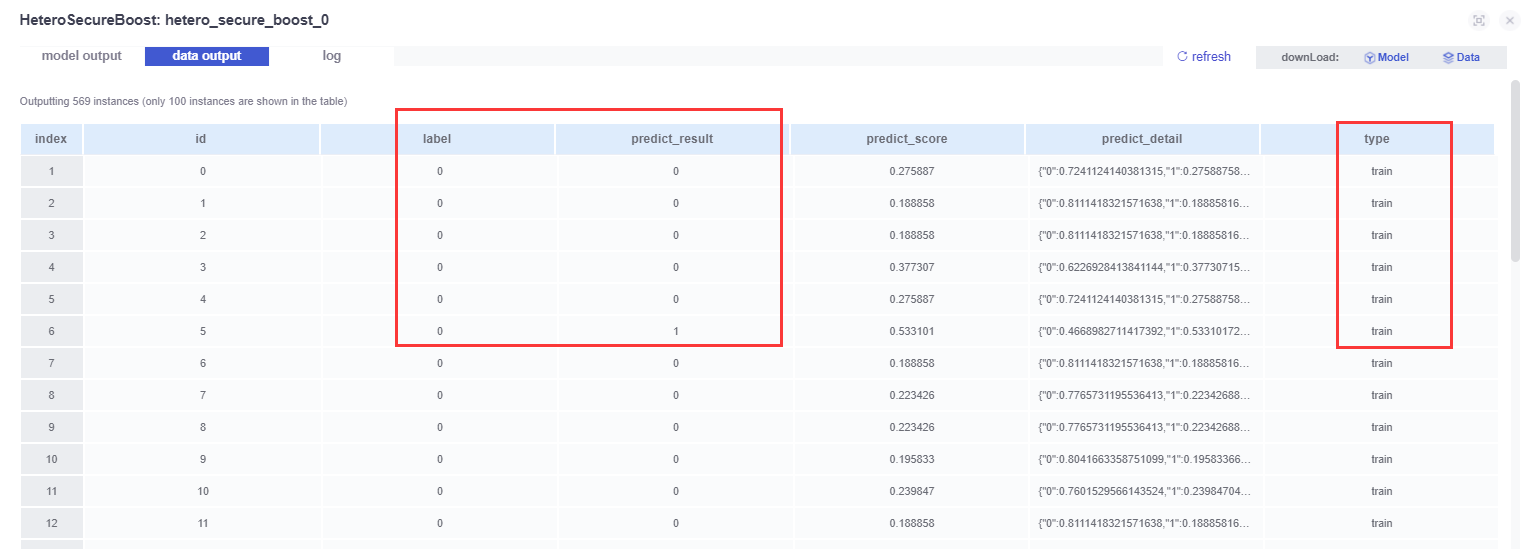
Data output:
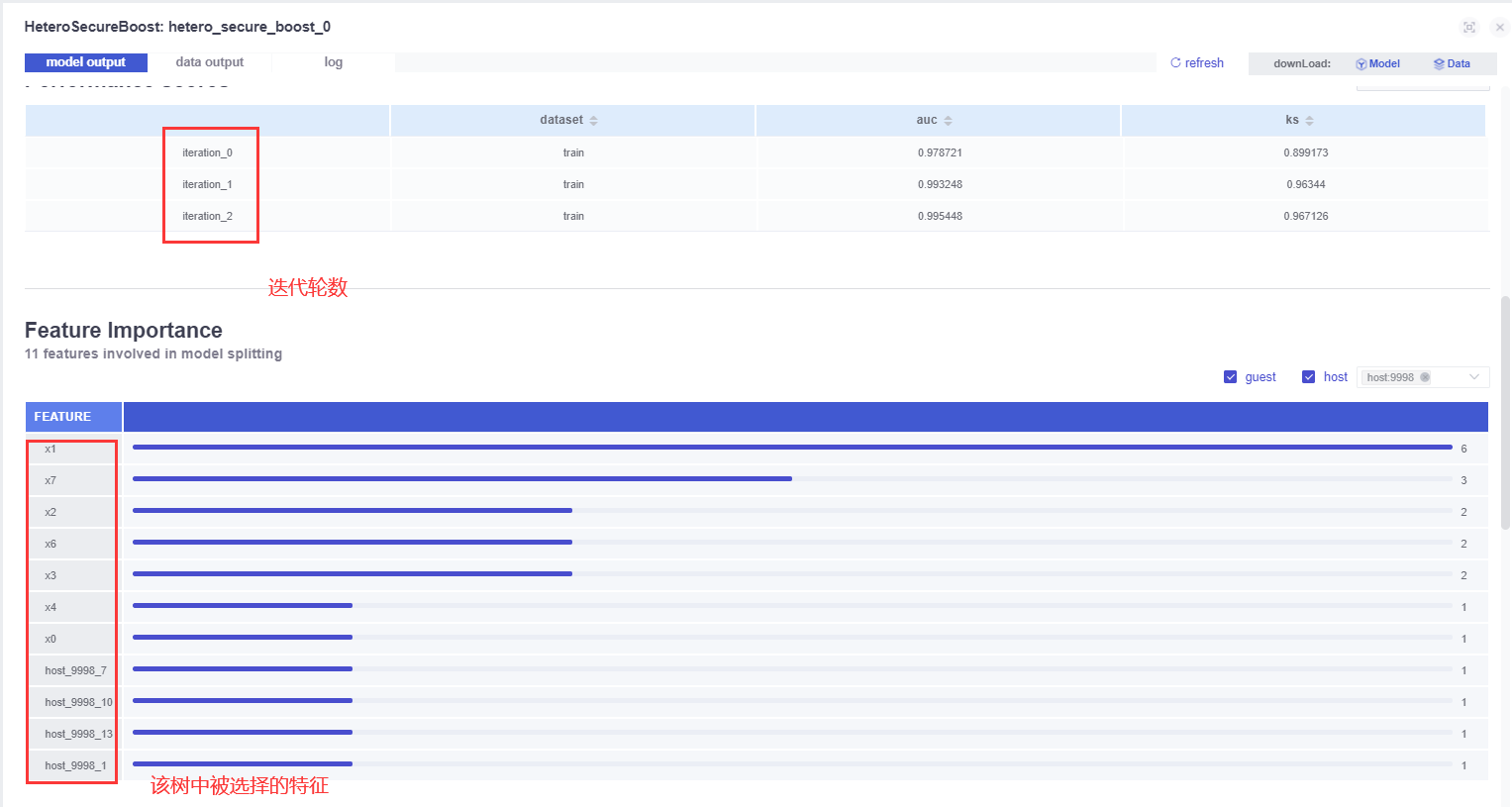
Various indicators of the model:
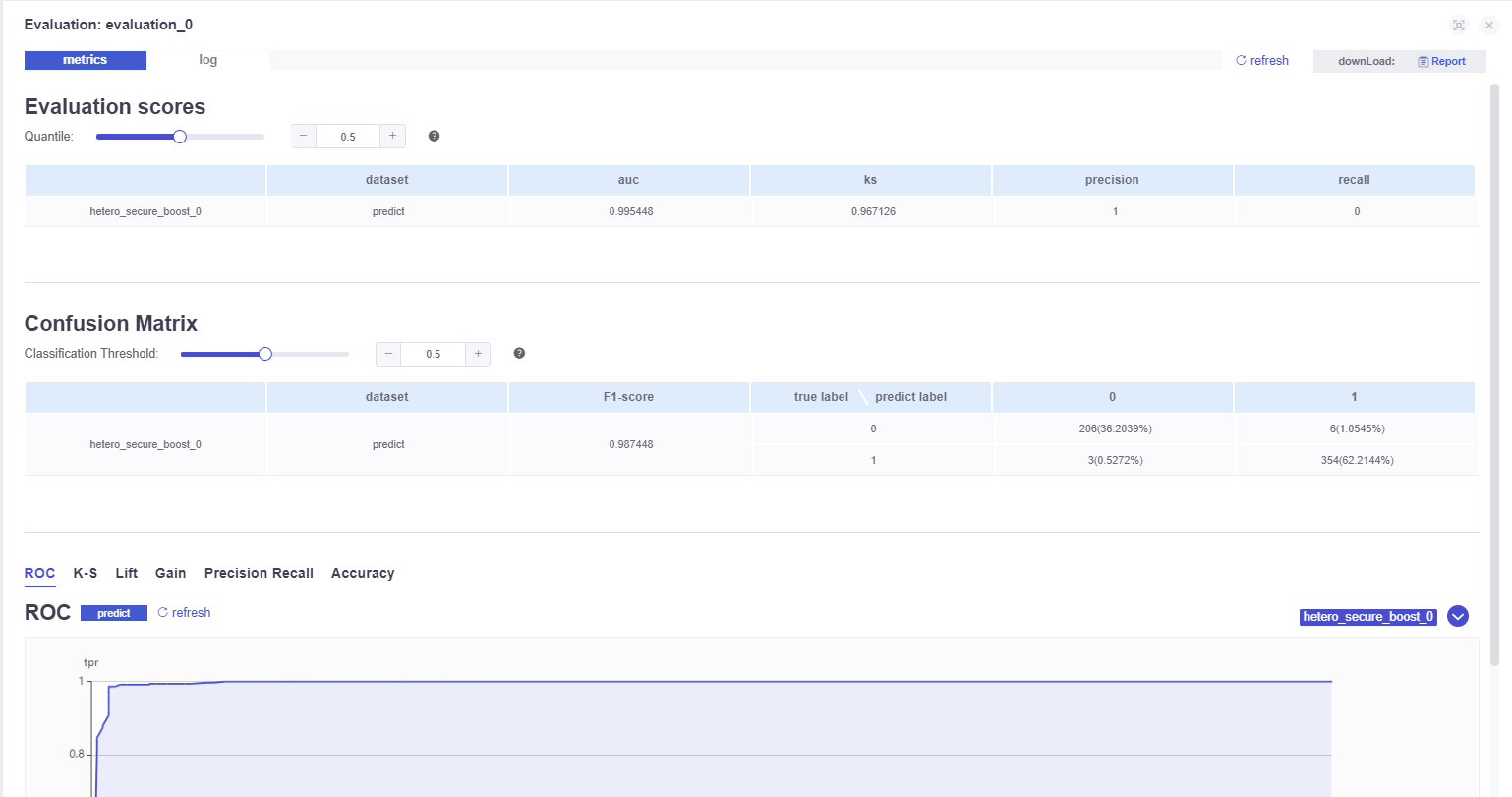
Model output on the host side:
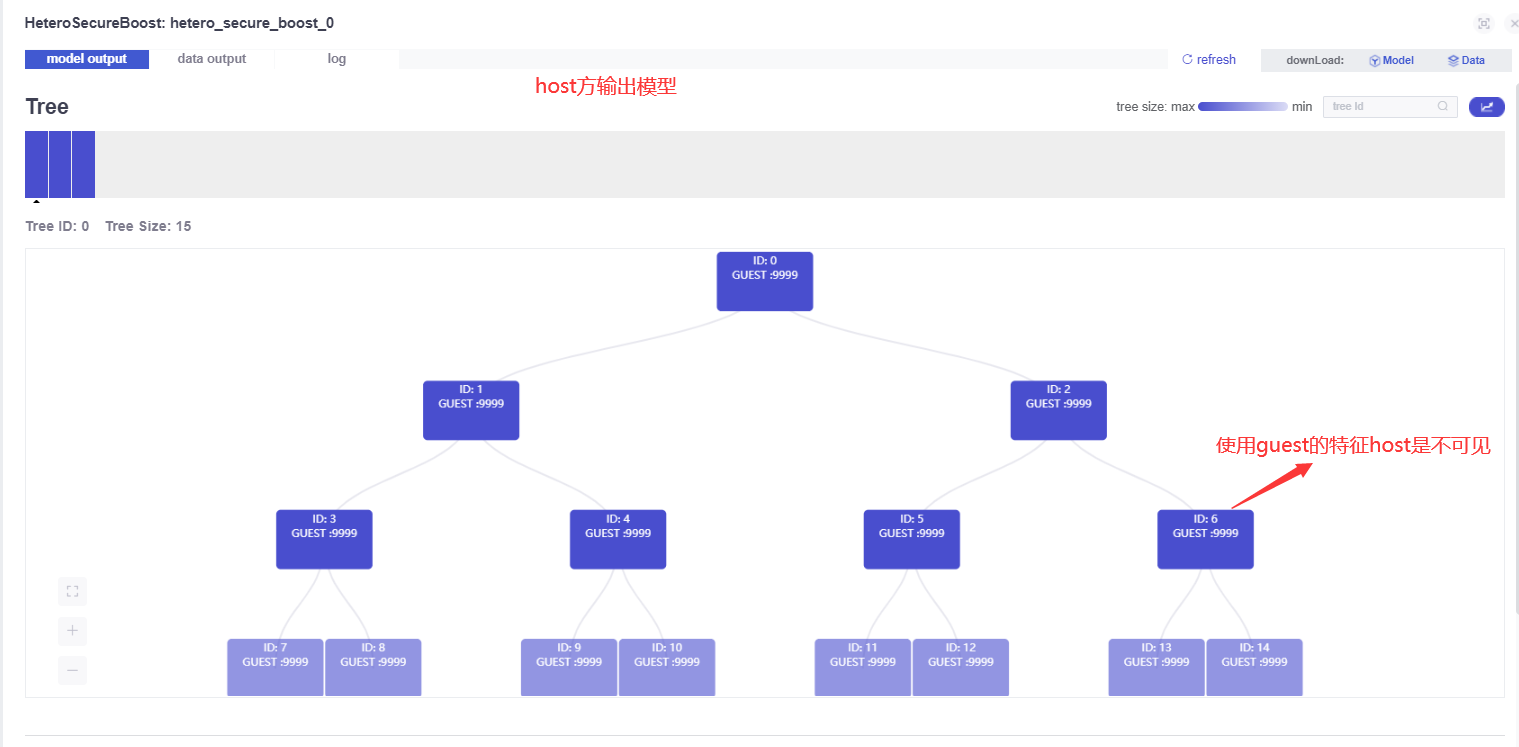
The host tag is anonymized at the guest.

There is no data output on the host side.
There is no model indicator on the host side.
2. Model prediction
So how do we make predictions with our already trained model?
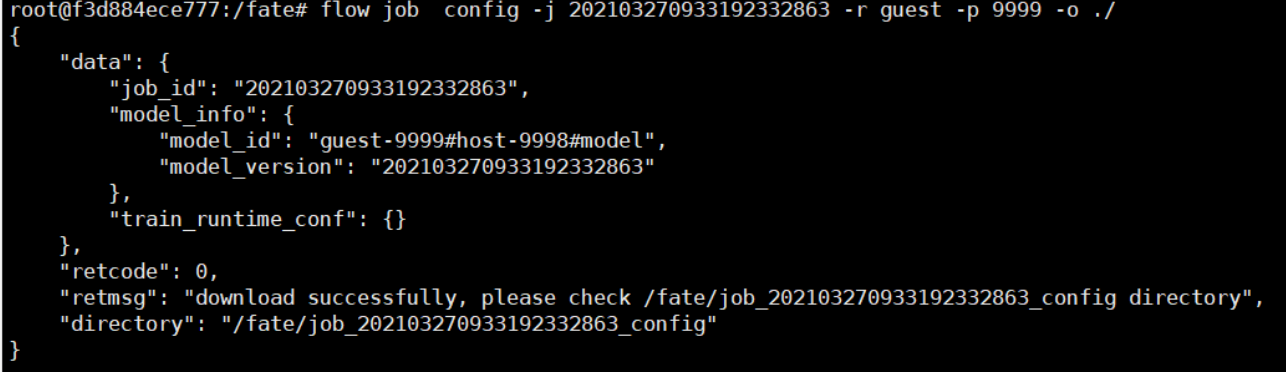
1. Find the corresponding model_id and model_version through the jobid we just submitted:
flow job config -j 202103270933192332863 -r guest -p 9999 -o ./
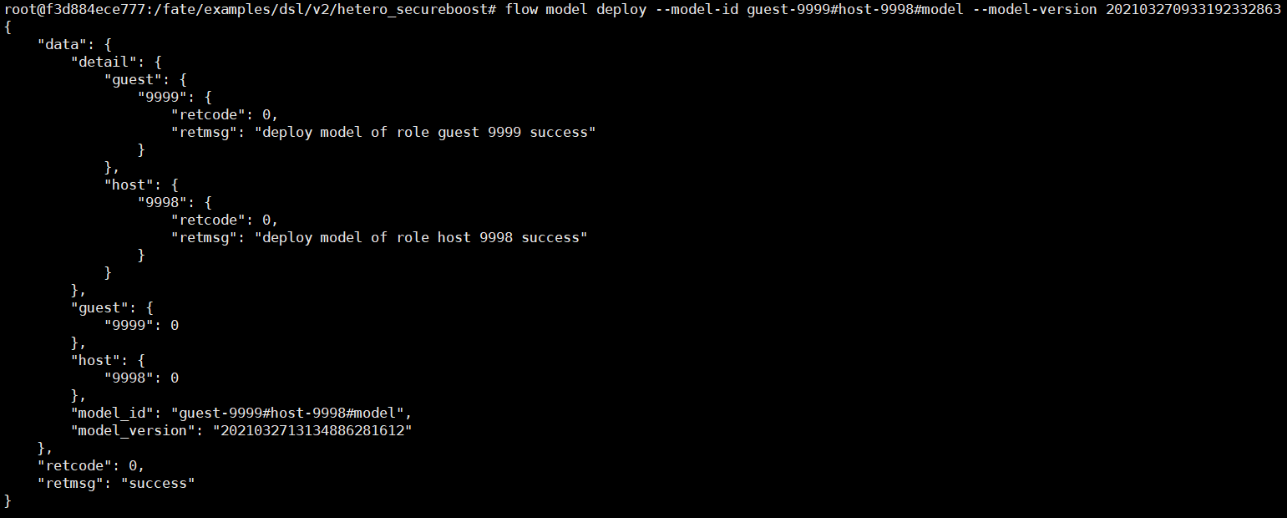
2. Deploy the model
flow model deploy --model-id guest-9999#host-9998#model --model-version 202103270933192332863
3. Modify the model_id and model_id of the test_predict_conf.json configuration file, including part_id and role.
4. Use the modified configuration file to submit the task for prediction:
You can see that the DAG predicted by the model seems to be somewhat different:
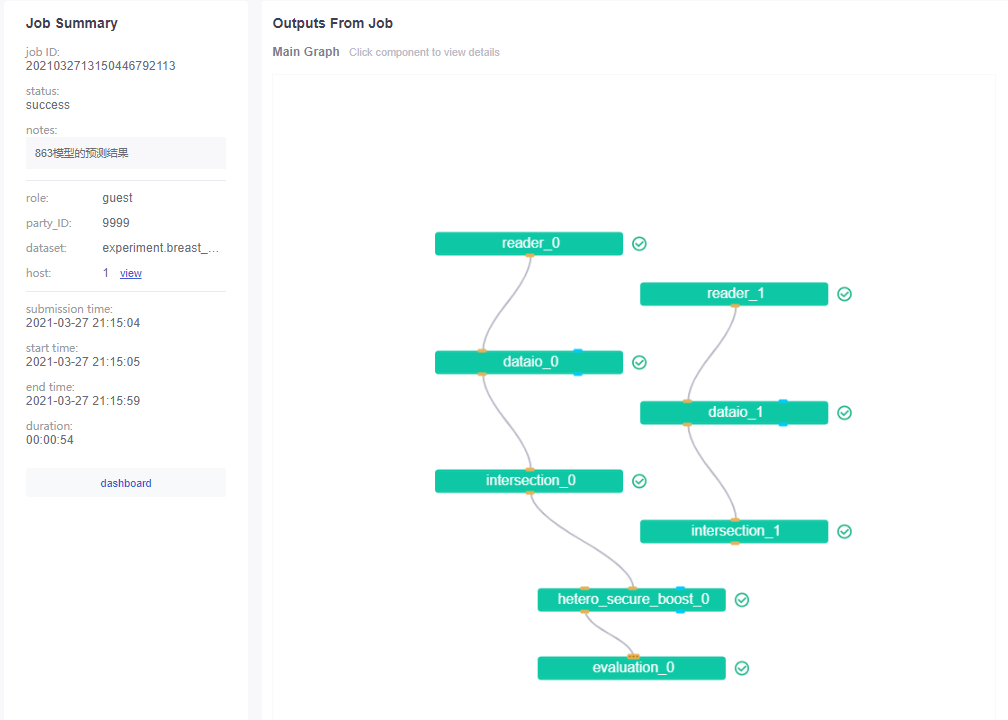
As mentioned above, read and dataio here are almost the same, of course, this also includes intersection.
The module output of the guest side is also the same as above.
The predictions here are almost the same as seen above, or because the same samples are used in the example cases.

Without loss of generality, let's look at the second tree output by the model:
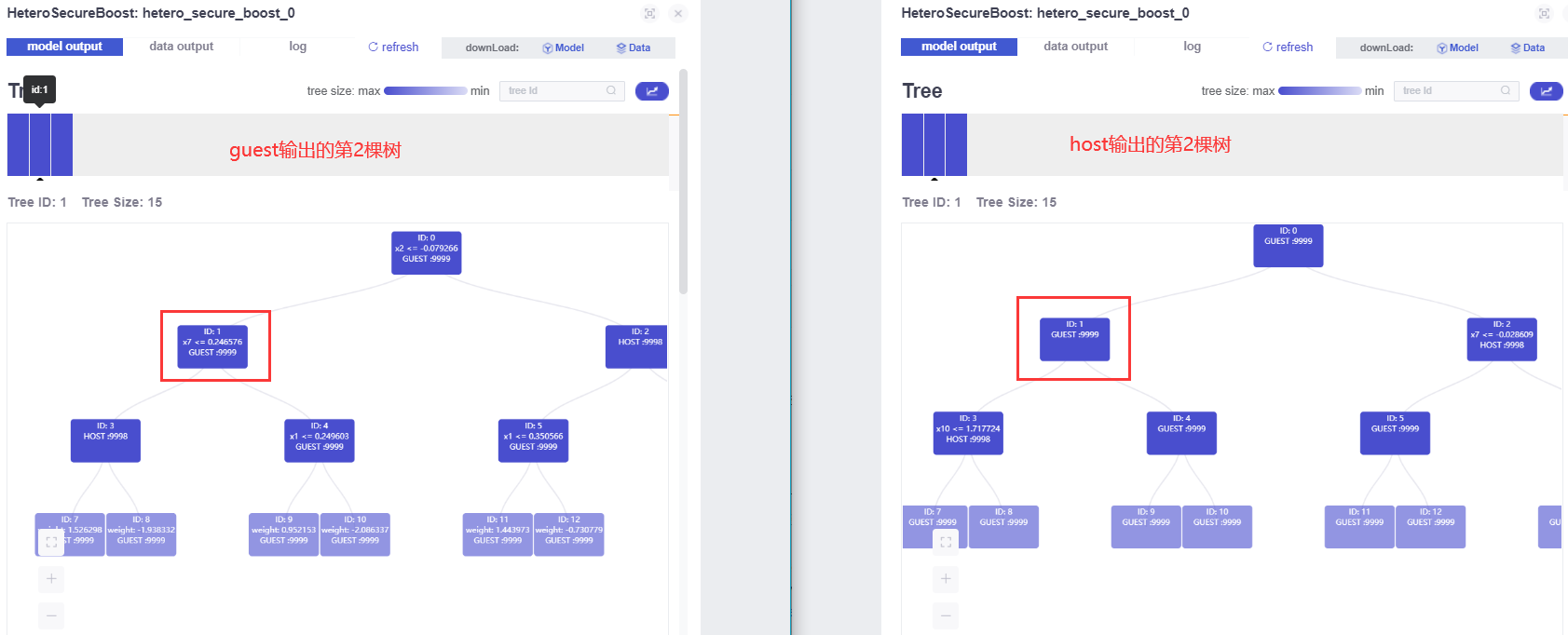
It can be known that the tree models of the guest side and the host side have the characteristics of each other (in fact, the two trees themselves should be like this, and they are also complementary). Therefore, when the model is used, both trees need to be used at the same time.