Related Book Recommendations
Principles of reading:不求甚解,观其大略
- Coding: The Language Hidden Behind Computer Software and Hardware
- "Understanding Computer Systems"
- Data Structures and Algorithms
- "java data structure and algorithm" "algorithm"
- "Introduction to Algorithms" "The Art of Computer Programming"
- Operating system: Linux kernel source code analysis Linux kernel design and implementation 30-day self-made operating system
- Network: Mechanic's "TCP/IP Detailed Explanation" Volume 1 is recommended to read the original version
- Compilation principle: the implementation mode of the programming language of the mechanical dragon book
- Database: SQLite source Derby
CPU Basics
The production process of CPU
Essence: a pile of sand + a pile of copper + a pile of glue + specific metal addition + special process
Sand deoxidation->quartz->silica->purification->silicon ingot->cutting->wafer->applying photoresist->lithography->etching->removing photoresist->plating->polishing- > Copper Layer -> Test -> Slice -> Package
The production process of Intel cpu (video description)
How cpu is made (text description)
Inside the cpu: silicon -> adding special elements -> P semiconductor N semiconductor -> PN junction -> diode -> field effect transistor -> logic switch
Basic logic circuits: AND gate OR gate NOT gate NOR gate (exclusive OR) Adder Accumulator Latch…
Realize manual calculation (read memory instruction each time, (high power low power))
Recommended Books: Chapter 17 of Coding
For cpu operation, it is through high frequency, low frequency -> converted into logic, it is a binary number: 0, 1 -> tell the computer which pin should be turned on and off
Manual Entry: Paper Tape Computer
Mnemonic: 01000010->mov sub...
High Level Language -> Compiler -> Machine Language
The principle of CPU
The most fundamental problem that computers need to solve: how to represent numbers
Assembly language execution process
The essence of assembly: the mnemonic of machine language, in fact, it is machine language: mov sub add represents binary data
Process: power on the computer -> CPU reads the program in memory (electrical signal input) -> the clock generator continuously oscillates on and off -> pushes the CPU to execute step by step (how many steps are executed depends on the clock cycle required by the instruction) -> calculation Done -> write back (electrical signal) -> write to graphics card output (sout, or graphics)
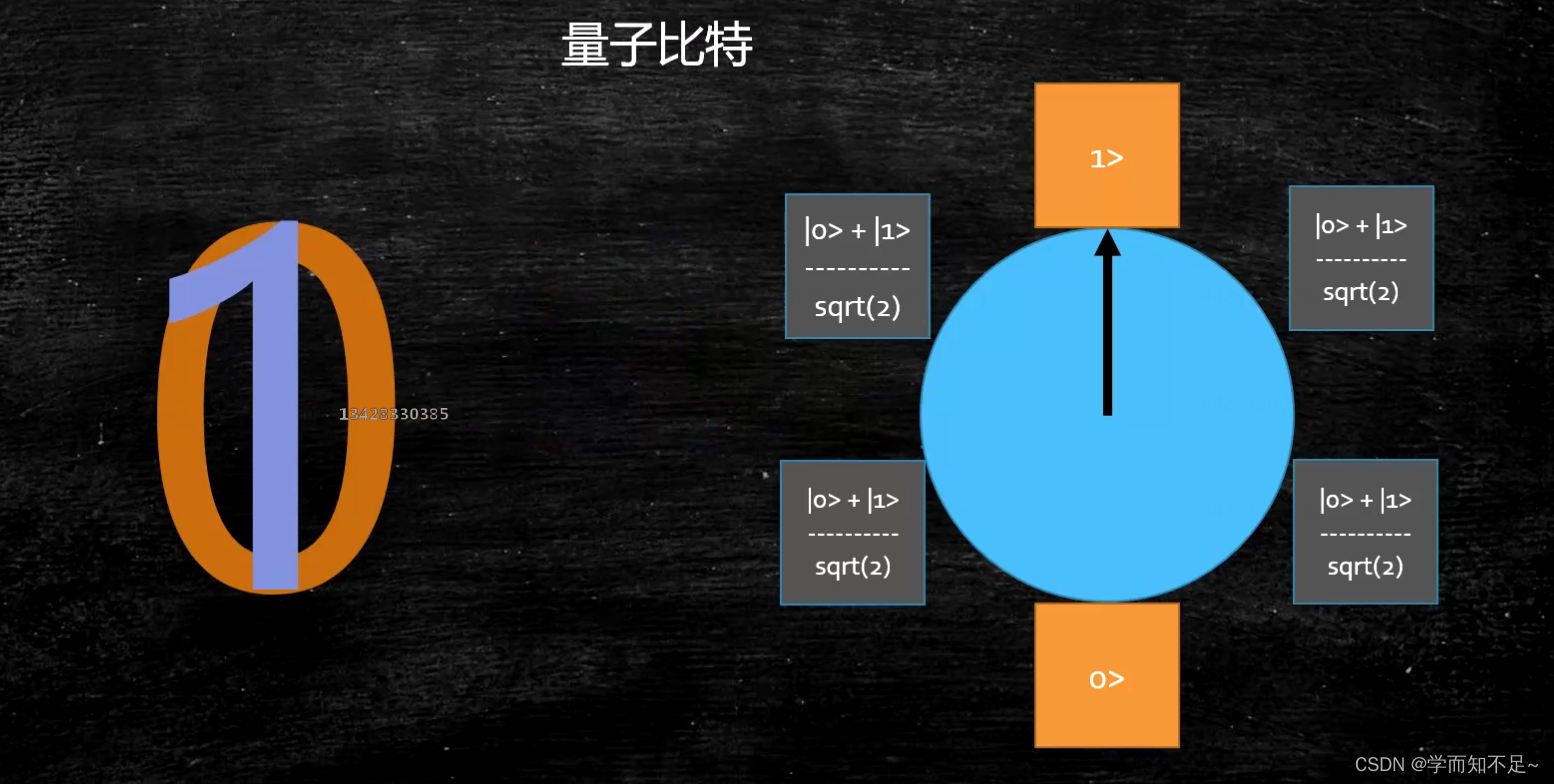
Quantum computer (just understand)
qubit

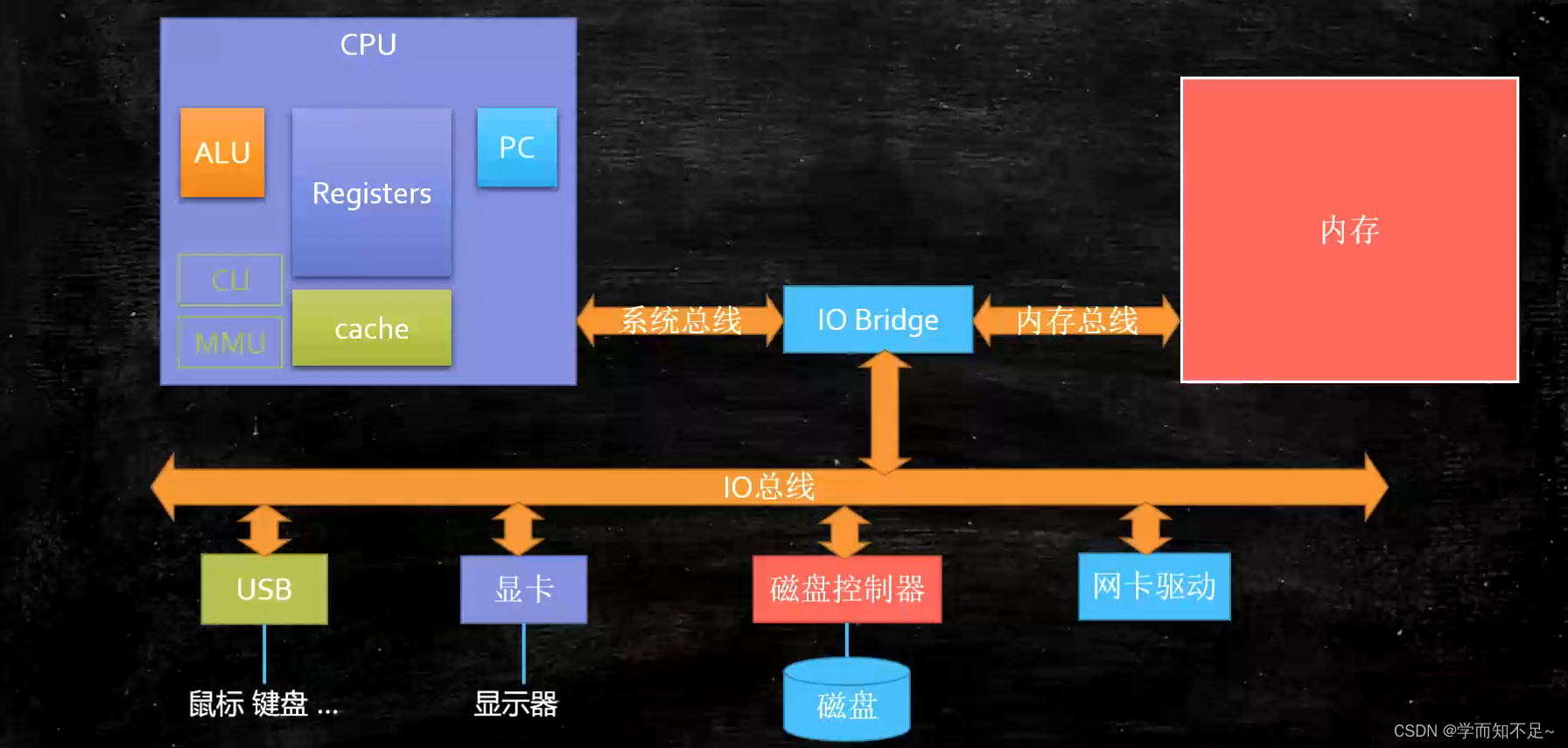
The composition of the computer
CPU和内存,是计算机的核心
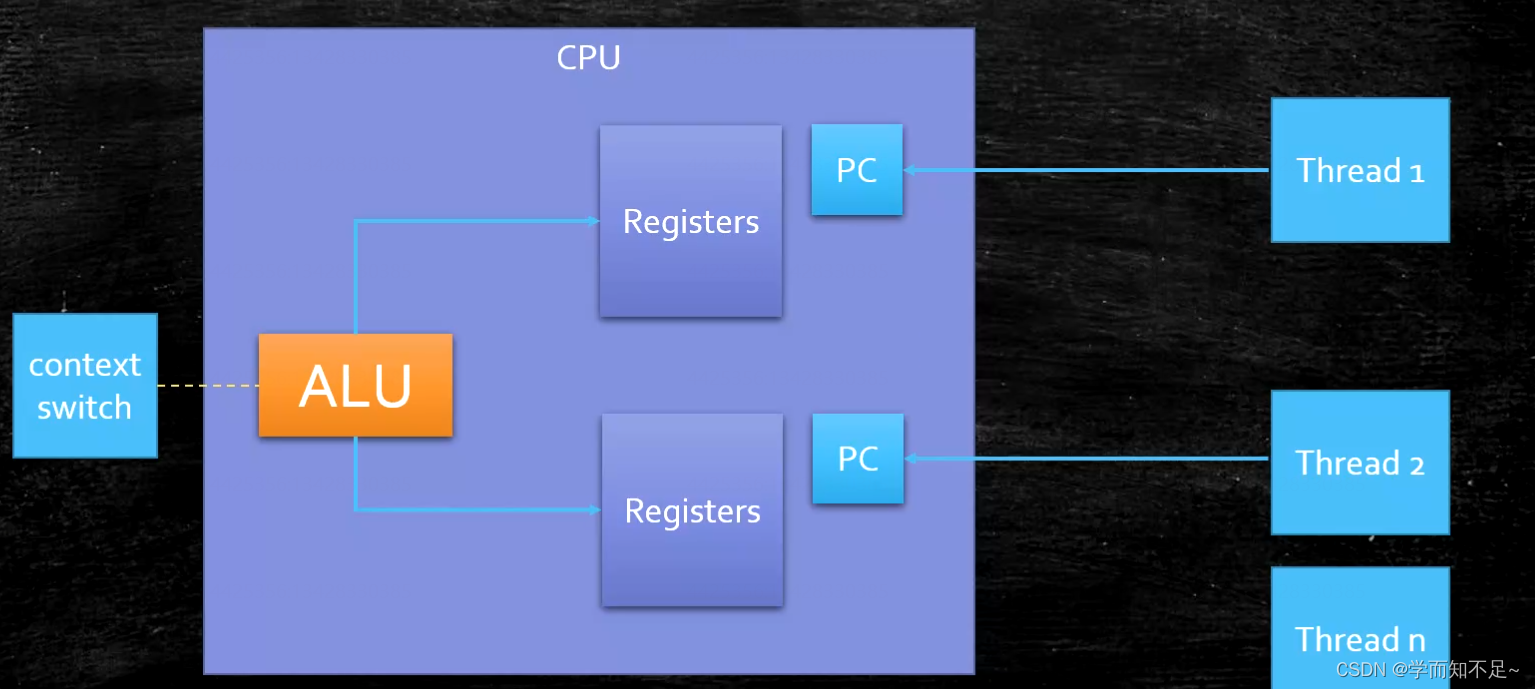
Basic composition of CPU
PC -> Program Counter program counter (records the current instruction address)
Registers -> Register: Temporarily store the data needed for CPU calculation
ALU -> Arithmetic & Logic Unit
CU -> Control Unit Control unit interrupt signal control
MMU -> Memory Management Unit memory management unit – hardware + os implementation
Hyperthreading: One ALU corresponds to multiple PC|Register
so-called four cores and eight threads as shown in the figure:
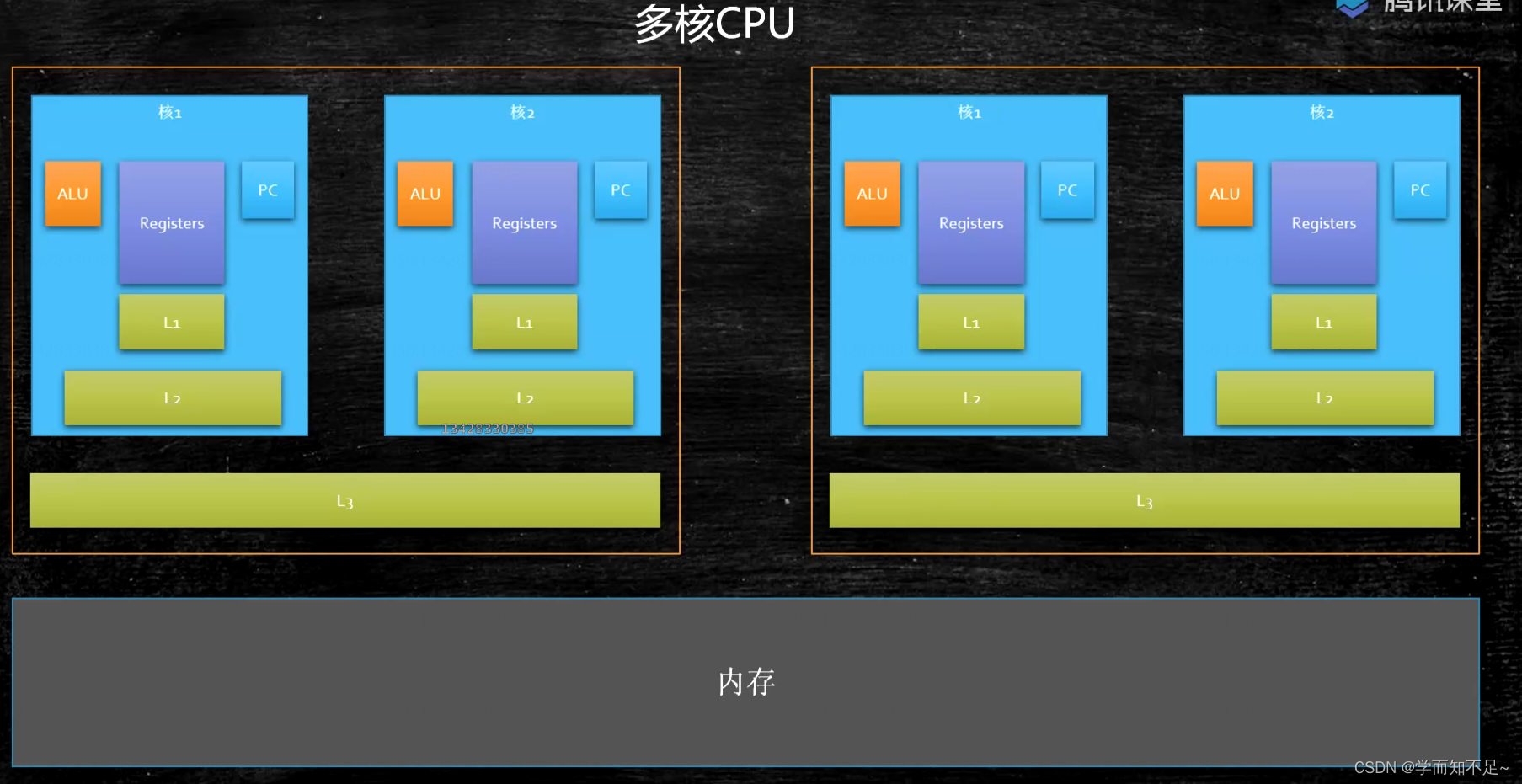
memory hierarchy

Why have a cache?
Because the speed of the CPU to different registers and main memory is not the same

cache physical structure
按块读取
The most basic principle of caching: the principle of program locality, which can improve efficiency and
give full play to the ability of bus CPU pins to read more data at one time
cache
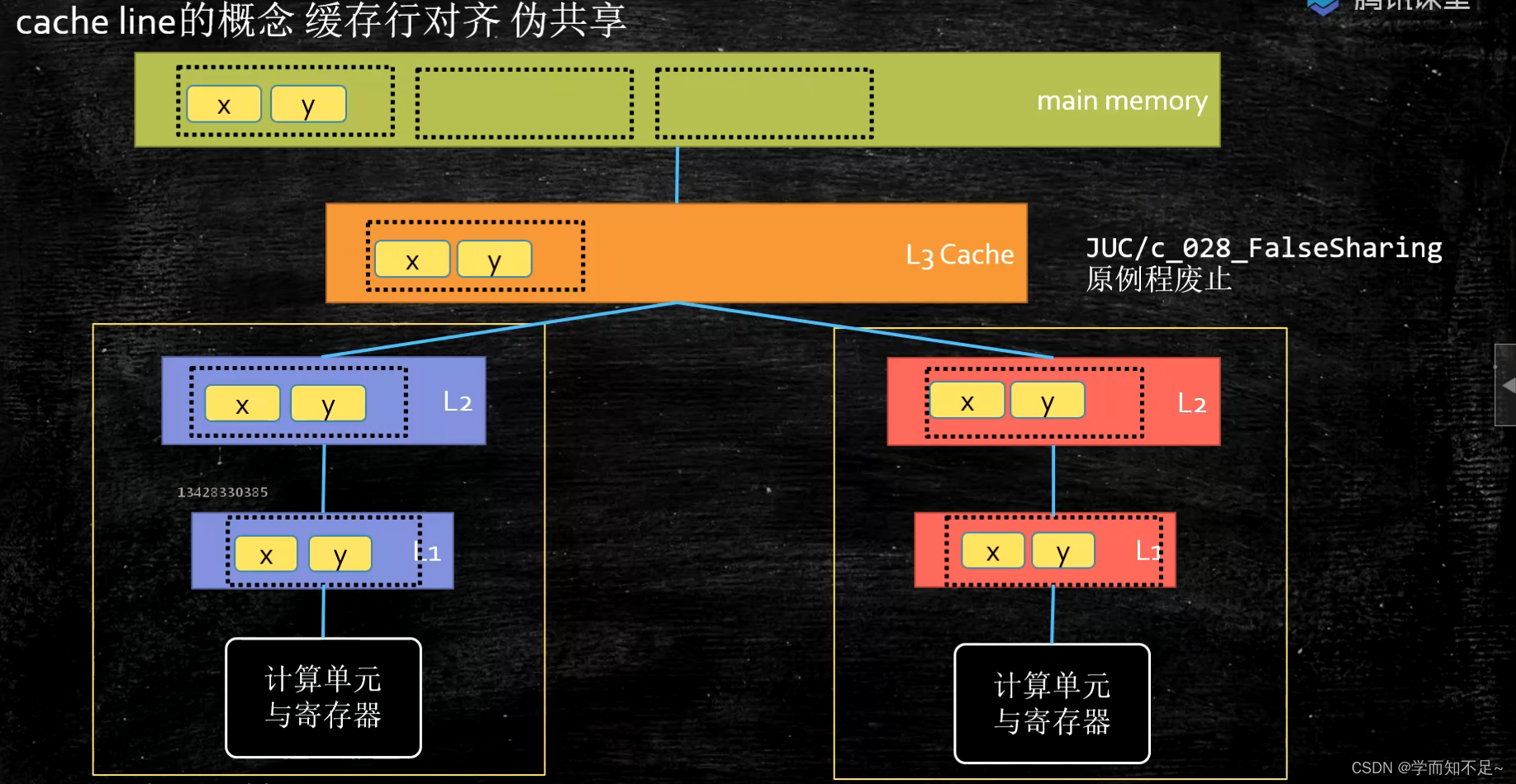
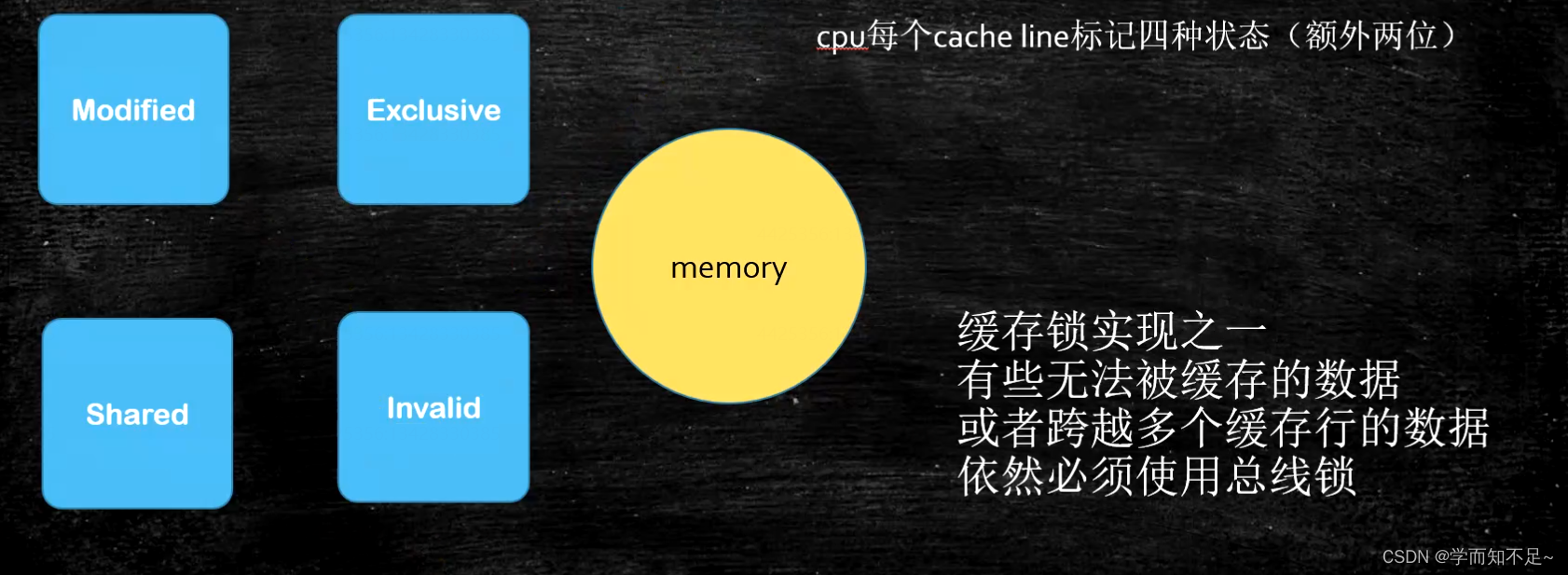
In order to ensure data consistency: in the unit of cache behavior, four cache line state
consistency protocols are defined
cache line size
Cache line: Currently, L3 cache is the most suitable for the industry. The
larger the cache line, the higher the local space efficiency, but the slower the read time
. The smaller the
cache Value, currently mostly used: 64 bytes
100 million assignment execution efficiency of the same cache line volatile ensures visibility between threads
package com.mashibing.juc.c_028_FalseSharing;
public class T03_CacheLinePadding {
public static volatile long[] arr = new long[2];
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 10000_0000L; i++) {
arr[0] = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 10000_0000L; i++) {
arr[1] = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}
100 million assignment execution efficiency of different cache lines
package com.mashibing.juc.c_028_FalseSharing;
public class T04_CacheLinePadding {
public static volatile long[] arr = new long[16];
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 10000_0000L; i++) {
arr[0] = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 10000_0000L; i++) {
arr[8] = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}
The results clearly show that the execution is faster with different cache lines
Therefore, a programming pattern was born - cache line alignment
Cache line alignment: For some particularly sensitive numbers, there will be high thread contention access. To ensure that false sharing does not occur, cache line alignment programming can be used.
For example, 7 long data are filled before and after the disruptor to ensure independent cache lines:

In JDK7, many use long padding to improve efficiency
JDK8, added @Contended annotation (experimental) need to add: JVM -XX:-RestrictContended
package com.mashibing.juc.c_028_FalseSharing;
import sun.misc.Contended;
/**
* T05_Contended
* Description
*
* @date 2020/5/26 - 23:38
*/
public class T05_Contended {
@Contended
volatile long x;
@Contended
volatile long y;
public static void main(String[] args) throws InterruptedException {
T05_Contended t = new T05_Contended();
Thread t1 = new Thread(()->{
for (long i=0;i<1_0000_0000L;i++){
t.x=i;
}
});
Thread t2 = new Thread(()->{
for (long i=0;i<1_0000_0000L;i++){
t.y=i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}