Process thread fiber (interview high frequency)
Interview high frequency: What is the difference between a process and a thread?
Unprofessional: A process is the state in which a program is running, and a thread is a different execution path in a process.
Professional: Process is the basic unit of OS allocation of resources, and thread is the basic unit of execution scheduling.
The most important thing to allocate resources is: independent memory space . Thread scheduling and execution (threads share the memory space of the process and do not have their own independent memory space)
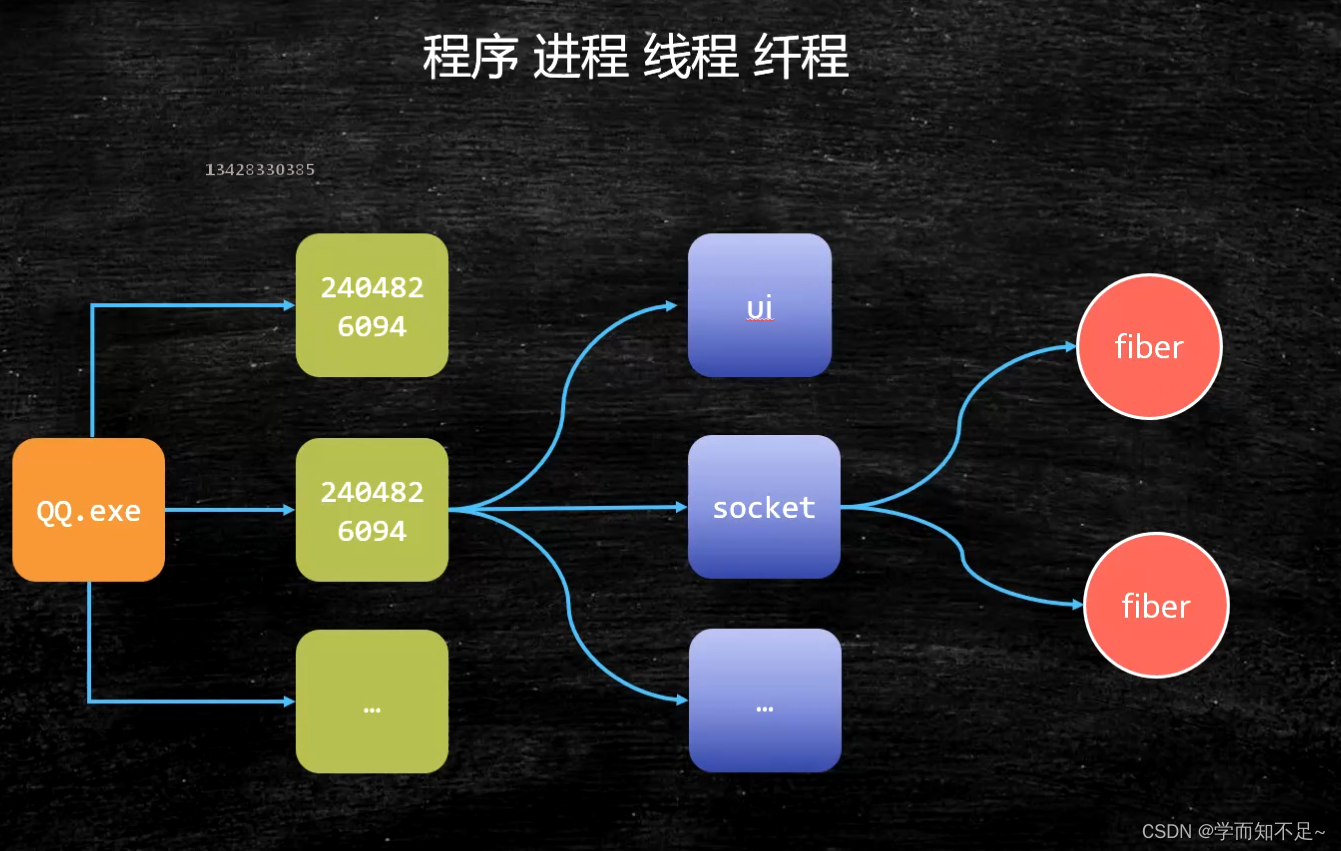
process

thread

fiber
Fiber: User-mode threads, threads in threads, switching and scheduling do not need to go through the OS
Advantages:
1: Occupy very few resources OS: Thread needs 1M Fiber and only needs 4K space
2: Switching is relatively simple
3: Start a lot of 10W+
2020-3-22 Languages that support built-in fibers: Kotlin Scala Go Python(lib)… Java? (open jdk : loom)
Hotspot's current thread needs to deal with the operating system every time it applies. The application through the kernel is called a heavyweight thread
. The role of the fiber is to directly deal with the JVM thread. One JVM thread can apply for multiple fibers, and the efficiency will be improved. faster
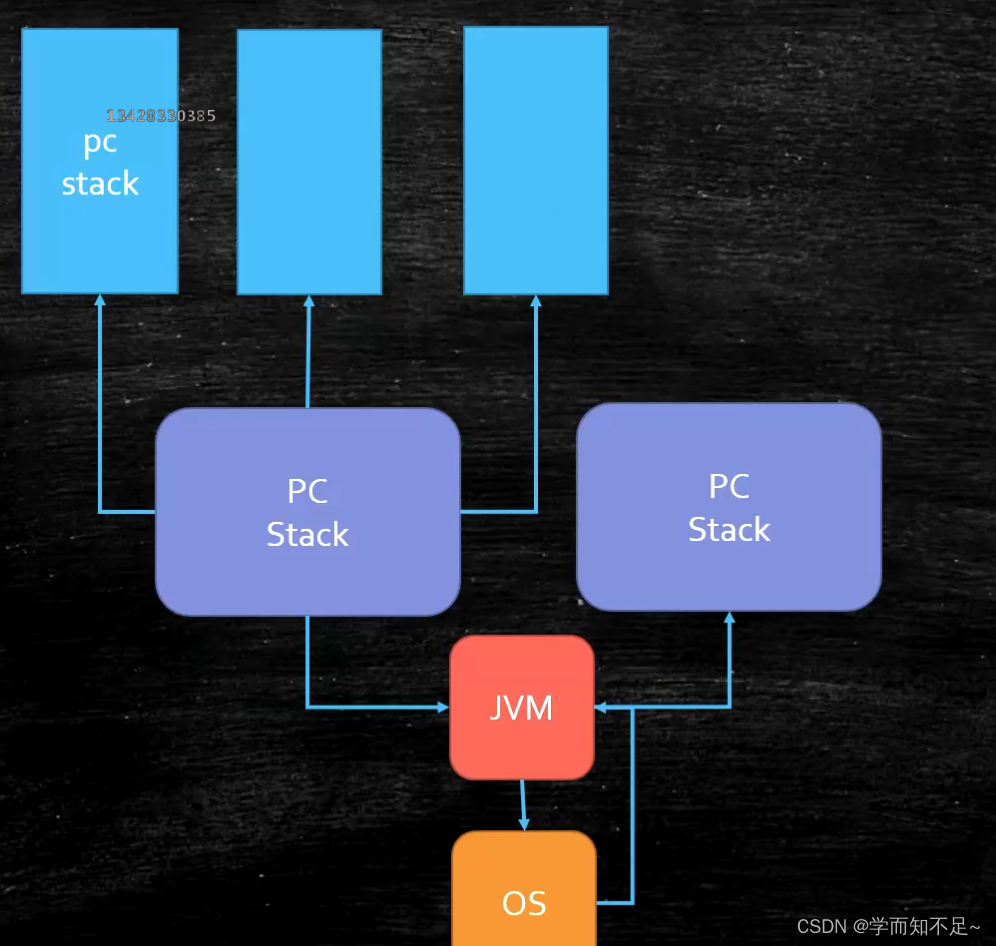
Fiber implementation
Support for fibers in Java: no built-in, hope built-in
Utilize Quaser library (immature)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>mashibing.com</groupId>
<artifactId>HelloFiber</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- https://mvnrepository.com/artifact/co.paralleluniverse/quasar-core -->
<dependency>
<groupId>co.paralleluniverse</groupId>
<artifactId>quasar-core</artifactId>
<version>0.8.0</version>
</dependency>
</dependencies>
</project>
import co.paralleluniverse.fibers.Fiber;
import co.paralleluniverse.fibers.SuspendExecution;
import co.paralleluniverse.strands.SuspendableRunnable;
public class HelloFiber {
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
Runnable r = new Runnable() {
@Override
public void run() {
calc();
}
};
int size = 10000;
Thread[] threads = new Thread[size];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(r);
}
for (int i = 0; i < threads.length; i++) {
threads[i].start();
}
for (int i = 0; i < threads.length; i++) {
threads[i].join();
}
long end = System.currentTimeMillis();
System.out.println(end - start);
}
static void calc() {
int result = 0;
for (int m = 0; m < 10000; m++) {
for (int i = 0; i < 200; i++) result += i;
}
}
}
import co.paralleluniverse.fibers.Fiber;
import co.paralleluniverse.fibers.SuspendExecution;
import co.paralleluniverse.strands.SuspendableRunnable;
public class HelloFiber2 {
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
int size = 10000;
Fiber<Void>[] fibers = new Fiber[size];
for (int i = 0; i < fibers.length; i++) {
fibers[i] = new Fiber<Void>(new SuspendableRunnable() {
public void run() throws SuspendExecution, InterruptedException {
calc();
}
});
}
for (int i = 0; i < fibers.length; i++) {
fibers[i].start();
}
for (int i = 0; i < fibers.length; i++) {
fibers[i].join();
}
long end = System.currentTimeMillis();
System.out.println(end - start);
}
static void calc() {
int result = 0;
for (int m = 0; m < 10000; m++) {
for (int i = 0; i < 200; i++) result += i;
}
}
}
Homework: Currently 10,000 Fiber -> 1 JVM thread, try to improve efficiency, such as 10,000 Fiber -> 10 copies -> 10Threads
Fiber application scenarios
Fiber vs thread pool: very short computing tasks, do not need to deal with the kernel, high concurrency!
Kernel threads (just understand)
The kernel often needs to do some background operations after startup, which is done by the Kernel Thread and only runs in the kernel space.
Such as timing, regular cleaning of garbage
Process creation and startup
System function: the interface provided by the system externally
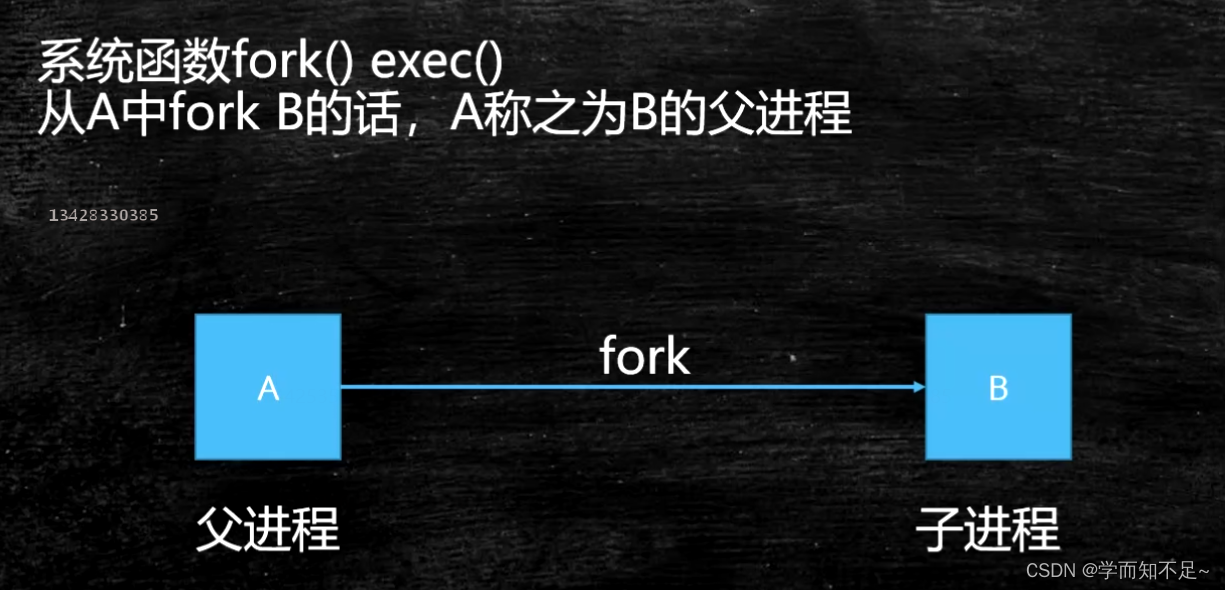
zombie process orphan process

Zombie process experiment
The process from the ps command in linux with < defunct > is a zombie process
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <assert.h>
#include <sys/types.h>
int main() {
pid_t pid = fork();
if (0 == pid) {
printf("child id is %d\n", getpid());
printf("parent id is %d\n", getppid());
} else {
while(1) {
}
}
}
Orphan Process Experiment
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <assert.h>
#include <sys/types.h>
int main() {
pid_t pid = fork();
if (0 == pid) {
printf("child ppid is %d\n", getppid());
sleep(10);
printf("parent ppid is %d\n", getppid());
} else {
printf("parent id is %d\n", getpid());
sleep(5);
exit(0);
}
}
Process scheduling
Each process in linux has its own scheduling scheme.
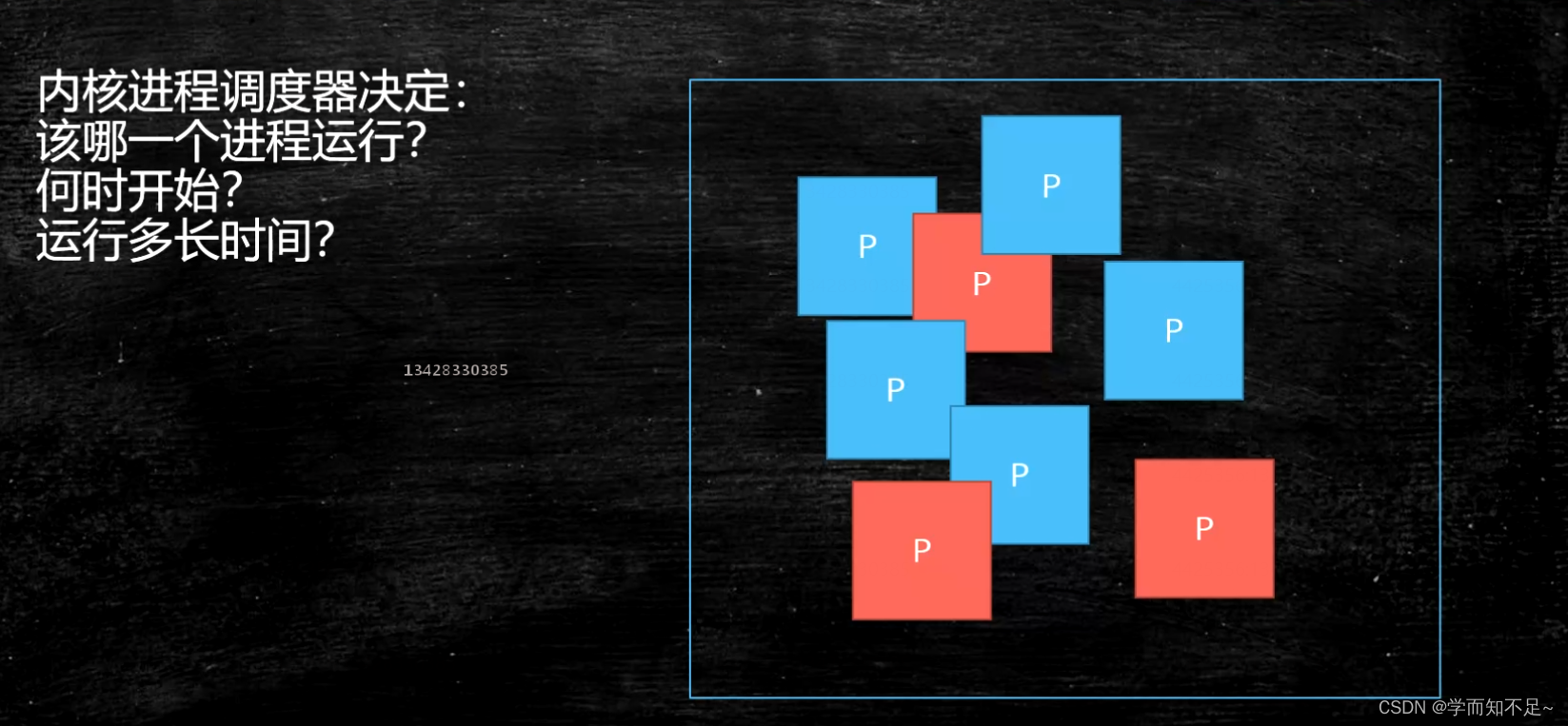
The early operating system was a single-task (exclusive CPU), and later it gradually became a multi-task (time-sharing CPU)
process scheduling principle:最大限度的压榨CPU资源
Basic Concepts of Process Scheduling
- Process type
- IO intensive: most of the time is spent waiting for IO
- CPU Intensive: Most of the time is spent on bulky calculations
- Process priority
- real-time process > normal process (0 - 99)
- Normal process nice value (-20 - 19)
- time management
- Linux uses CPU time ratio by priority
- Other systems mostly use time slices by priority
- eg. Two apps running at the same time
- a text processing program
- a post-production program
Process Scheduling Algorithms
In case of multitasking:
- Non-preemptive (cooperative multitasking): Unless the process actively yields the CPU (yielding), it will always run
- Preemptive multitasking:
进程调度器Start or suspend (preempt) the execution of a process by force
Linux Scheduling Strategies (Elective)
linux2.5 Classic Unix O(1) scheduling strategy, biased towards servers, but not friendly to interaction
linux2.6.23 adopts CFS complete fair scheduling algorithm Completety Fair Scheduler
CFS: According to the proportion of time slices allocated by priority, record the execution time of each process. If there is a process whose execution time is less than the proportion it should be allocated, it will be executed first.
Default scheduling policy:
real-time process (emergency) priority level - FIFO (First In First Out), the same priority - RR (Round Robin)
common process: CFS

interrupt
A mechanism by which hardware interacts with the operating system kernel
Soft interrupt (0x80 interrupt signal) == system call
System call: int 0x80 (old, supported at the software level) or sysenter primitive (new, supported directly at the hardware level)
fill in the call number (corresponding to different functions) through the ax register
The parameters are passed into the kernel through bx cx dx si di
The return value is returned through ax
Example: java read network -> jvm read() -> c library read() -> kernel space -> system_call() (system call handler) -> sys_read()
Implementation details of the interrupt handling mechanism
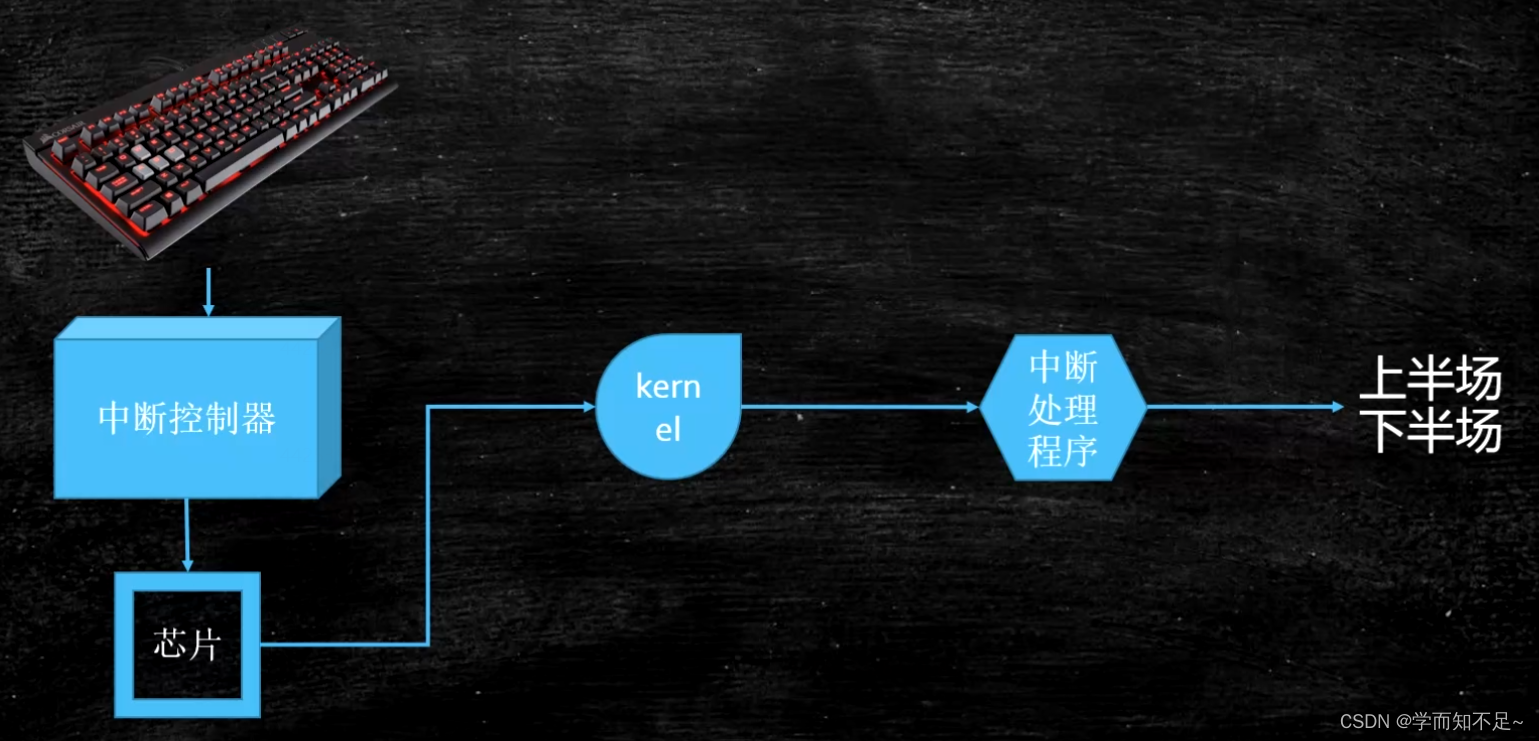
Understanding soft interrupts from an assembly perspective
Build an assembly environment
yum install nasm
;hello.asm
;write(int fd, const void *buffer, size_t nbytes)
;fd 文件描述符 file descriptor - linux下一切皆文件
section data
msg db "Hello", 0xA
len equ $ - msg
section .text
global _start
_start:
mov edx, len
mov ecx, msg
mov ebx, 1 ;文件描述符1 std_out
mov eax, 4 ;write函数系统调用号 4
int 0x80
mov ebx, 0
mov eax, 1 ;exit函数系统调用号
int 0x80
Compile: nasm -f elf hello.asm -o hello.o
Link: ld -m elf_i386 -o hello hello.o
The execution process of a program is either in user mode or in kernel mode