For historical reasons, the training of recommendation models in the industry is mostly achieved through CPU. However, with the evolution of models from Logistic Regression to Deep Neural Networks and the development of hardware, a CPU-based training system may no longer be the most suitable solution. Based on the principle of not blindly obeying, not plagiarizing, and adhering to the original technical route, Kuaishou Seattle FeDA Intelligent Decision Lab launched a GPU-based advertising recommendation training system called "Persia". In the past, a system that required 50 CPU machines to train for 20 hours, now only requires an ordinary GPU machine to complete it in one to two hours, and the single machine efficiency is increased by up to 640 times.
this means:
In the past, using fifty computers, one could only try one new idea a day. The new system only needs one computer, and one or two hours can try a new idea.
In the past, only one or two students could try new models at the same time. The new system allows many students to try their own new ideas at the same time.
This system has been quickly promoted and used within Kuaishou commercialization, allowing everyone to quickly trial and error and test new models and features. The initiator of the project is an intern from the University of Rochester. The GPU solution he proposed was affirmed by his mentor at the University of Rochester, head of FeDA Intelligent Decision Lab Liu Ji, and many algorithm strategy experts in the company.
FeDA Lab immediately established a project team, and decided to name it after the project sponsor’s favorite comic character Persia ("Persia"), and started the intensive development. The team first uses PyTorch as the basic platform to solve various technical problems, and then implements and optimizes the TensorFlow version. After 4 months of development and cooperation, the Persia GPU advertising training system has taken shape. The system supports both PyTorch and TensorFlow two sets of solutions at the same time to facilitate the different preferences of model development students. Currently, Persia has supported multiple business projects, and each R&D staff only needs one machine to quickly iterate trial and error.
The technology behind Persia
The technology behind Persia's efficient training includes GPU distributed training and high-speed data reading.
GPU distributed computing accelerates model training efficiency
In recent years, GPU training has achieved great success in applications such as image recognition and word processing. GPU training, with its unique efficiency advantages in mathematical operations such as convolution, greatly improves the speed of training machine learning models, especially deep neural networks. However, in the advertising model, due to the existence of a large number of sparse samples (such as user ids), each id will have a corresponding Embedding vector in the model, so the advertising model is often very large, so that a single GPU cannot save the model. At present, the model is often stored in the memory, and the CPU performs this part of the huge Embedding layer operation. This not only limits the speed of training, but also makes it impossible to use more complex models in actual production-because the use of complex models will cause the CPU to take too long to calculate a given input and cannot respond to requests in a timely manner.
The composition of the advertising model: In the advertising model, the model is often composed of three parts as shown in the figure below:
Embedding layer composed of user id, advertisement id, etc. Each id corresponds to a vector of a preset size. Since the number of id is often very large, these vectors often occupy more than 99% of the entire model volume. Suppose we have m1 (Note: for typesetting reasons, here 1 is the subscript, the same below) such id:, their corresponding Embedding layer will output m1 vectors.
Image information, LDA and other real vector features. This part will be combined with the Embedding vector corresponding to id and input into DNN to predict click-through rate and so on. Suppose we have m2 such vectors:.
DNN. This part is a traditional neural network that accepts Embedding vector and real number vector features, and outputs the amount of click-through rate that you want to predict: prediction =.
Persia uses a variety of techniques to train advertising models, which we will introduce in the next few sections.
1. Large model Embedding sharding training
广告模型的 Embedding 部分占模型体积和计算量的大部分。很有可能无法放入单个 GPU 的显存中。为了使用 GPU 运算以解决 CPU 运算速度过慢的问题,但又不受制于单 GPU 显存对模型大小的限制,Persia 系统使用多 GPU 分散存储模型,每个 GPU 只存储模型一部分,并进行多卡协作查找 Embedding 向量训练模型的模式。
Persia 将第 i 个 Embedding 层 Ei 放入第 (i% 总显卡数) 个显卡中,从而使每个显卡只存放部分 Embedding。与此同时,实数向量特征和 DNN 部分则置于第 0 个显卡中。在使用 Persia 时,它将自动在各个显卡中计算出 的值(如果对于一个 Embedding 输入了多个 id,则计算其中每个值对应的 Embedding vector 的平均),并传送给第 0 个显卡。第 0 个显卡会合并这些 Embedding vector 和实数向量特征,输入 DNN 中进行预测。
当求解梯度时,第 0 个显卡会将各个 Embedding 层输出处的导数传回各个显卡,各个显卡各自负责各自 Embedding 的反向传播算法求梯度。大致结构如下图所示:
GPU 分配的负载均衡:由于将 Embedding 依次分配在每个 GPU 上,可能导致部分 GPU 负载显著高于其他 GPU,为了让每个 GPU 都能充分发挥性能,Persia 训练系统还支持对 Embedding 运算在 GPU 上进行负载均衡。
给定 k 个 GPU,当模型的 m1 个 Embedding 层对应 GPU 负载分别为 l1, l2, …,lm1,Persia 将会尝试将 Embedding 分为 k 组 S1, S2, …, Sk,并分别存放在对应 GPU 上,使得每组 大致相等。这等价于如下优化问题:
其中 Vi 是第 i 个模型的大小,C 是单个 GPU 的显存大小。Persia 使用贪心算法得到该问题的一个近似解,并依此将不同 Embedding 均匀分散在不同 GPU 上,以达到充分利用 GPU 的目的。当需要精确求解最优的 Embedding 放置位置时,Persia 还可以通过 integer optimization 给出精确解。
2. 简化小模型多 GPU 分布训练
当模型大小可以放入单个 GPU 时,Persia 也支持切换为目前在图像识别等任务中流行的 AllReduce 分布训练模式。这样不仅可以使训练算法更加简单,在某些情景下还可以加快训练速度。
使用这种训练模式时,每个 GPU 都会拥有一个同样的模型,各自获取样本进行梯度计算。在梯度计算后,每个 GPU 只更新自己显存中的模型。需要注意的是即使模型可以置于一个 GPU 的显存中,往往 Embedding 部分也比较大,如果每次更新都同步所有 GPU 上的模型,会大大拖慢运算速度。因此 Persia 在 AllReduce 模式下,每次更新模型后,所有 GPU 使用 AllReduce 同步 DNN 部分,而 Embedding 部分每隔几个更新才同步一次。这样,即不会损失太多信息,又保持了训练速度。
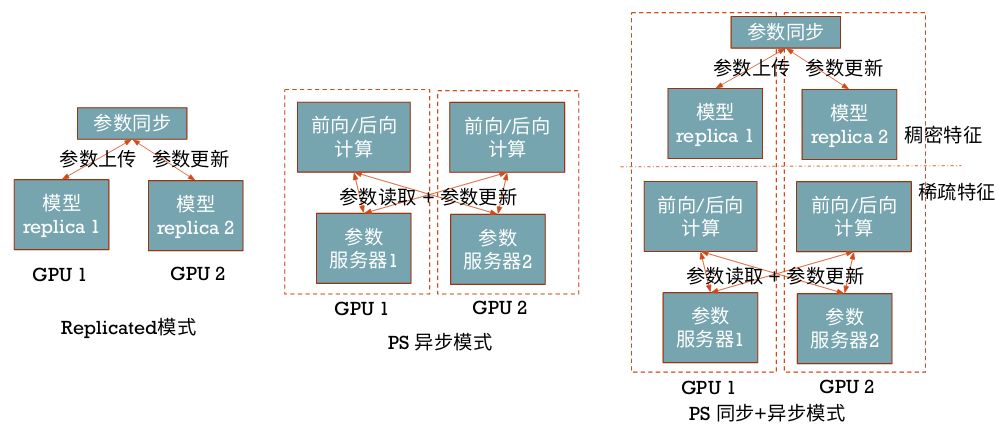
此外,在 TensorFlow 上,Persia 还支持 TensorFlow 的"Replicated", "PS", "PS" + "Asynchronous" 模式多卡训练,它们的主要区别如下图:

模型准确度提升
同步更新:由于普遍使用的传统异步 SGD 有梯度的延迟问题,若有 n 台计算机参与计算,每台计算机的梯度的计算实际上基于 n 个梯度更新之前的模型。在数学上,对于第 t 步的模型 xt,传统异步 SGD 的更新为:

其中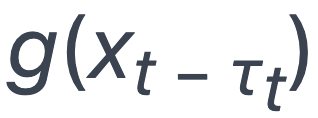 是训练样本的损失函数在τt 个更新之前的模型上的梯度。而τt 的大小一般与计算机数量成正比,当计算机数量增多,
是训练样本的损失函数在τt 个更新之前的模型上的梯度。而τt 的大小一般与计算机数量成正比,当计算机数量增多,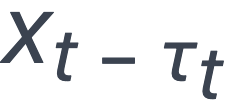 与 xt 相差就越大,不可避免地导致模型质量的降低。Persia 的训练模式在 Embedding 分片存储时没有这种延迟问题,而在 AllReduce 模式下也仅在 Embedding 层有常数量级的延迟,因此模型质量也有所提升。
与 xt 相差就越大,不可避免地导致模型质量的降低。Persia 的训练模式在 Embedding 分片存储时没有这种延迟问题,而在 AllReduce 模式下也仅在 Embedding 层有常数量级的延迟,因此模型质量也有所提升。
优化算法:与此同时,Persia 还可以使用 Adam 等 momentum optimizer,并为其实现了 sparse 版本的更新方式,比 PyTorch/TensorFlow 内置的 dense 版本更新在广告任务上快 3x-5x。这些算法在很多时候可以在同样时间内得到比使用 SGD 或 Adagrad 更好的模型。
训练数据分布式实时处理
快手 Persia 的高速 GPU 训练,需要大量数据实时输入到训练机中,由于不同模型对样本的需求不同,对于每个新实验需要的数据格式可能也不同。因此 Persia 需要:
简单灵活便于修改的数据处理流程,
可以轻易并行的程序架构,
节约带宽的数据传输方式。
为此,Persia 系统实现了基于 Hadoop 集群的实时数据处理系统,可以应不同实验需求从 HDFS 中使用任意多计算机分布式读取数据进行多级个性化处理传送到训练机。传输使用高效消息队列,并设置多级缓存。传输过程实时进行压缩以节约带宽资源。
1. 并行数据处理
数据处理 pipeline:为了使 Persia 获取数据的方式更灵活,Persia 使用 dataflow 构建数据处理 pipeline。在 Persia 中可以定义每一步处理,相当于一个函数,输入为上一个处理步骤的输出,输出提供给下一个处理步骤。我们定义这些函数为 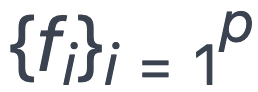 。在 Persia 中,这些函数可以单独定义修改。在每个函数的入口和出口,Persia 有数据队列缓存,以减少每个函数获取下一个输入的时间。这些函数的运行可以完全并行起来,这也是 pipeline 的主要目的。以在食堂就餐为例,pipeline 的运行就像这样:
。在 Persia 中,这些函数可以单独定义修改。在每个函数的入口和出口,Persia 有数据队列缓存,以减少每个函数获取下一个输入的时间。这些函数的运行可以完全并行起来,这也是 pipeline 的主要目的。以在食堂就餐为例,pipeline 的运行就像这样:

数据压缩和传输:全部处理之后,数据处理任务会将数据组成 mini-batch 并使用 zstandard 高速压缩每个 batch,通过 ZeroMQ 将压缩数据传输给训练机进行训练。定义 batching 操作为函数 B,压缩操作为函数 C,则每个数据处理任务相当于一个函数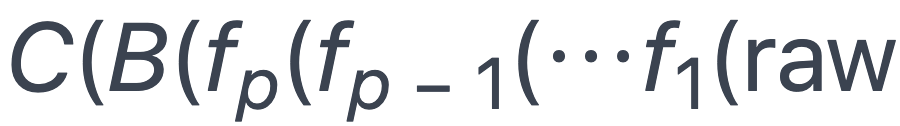
 。
。
Queue server:在 Hadoop 集群中 Persia 将启动多个数据处理任务,每个数据处理任务之间完全独立。数据处理任务本身并不知道处理哪些数据,而是通过请求训练机得知训练数据的位置。这样的好处是,在 Persia 中训练机可以应自己需求动态控制使用什么样的训练数据,而数据处理任务相当于一个无状态的服务,即使训练机更换了新的训练任务也不需要重启数据处理任务。具体来说,在 Persia 中训练机会启动一个 queue server 进程,该 queue server 将会应数据处理任务的请求返回下一个需要读取的数据文件。Persia 的每个数据处理任务会同时从 queue server 请求多个文件,并行从 HDFS 读取这些文件。
整个系统的构造如下图:
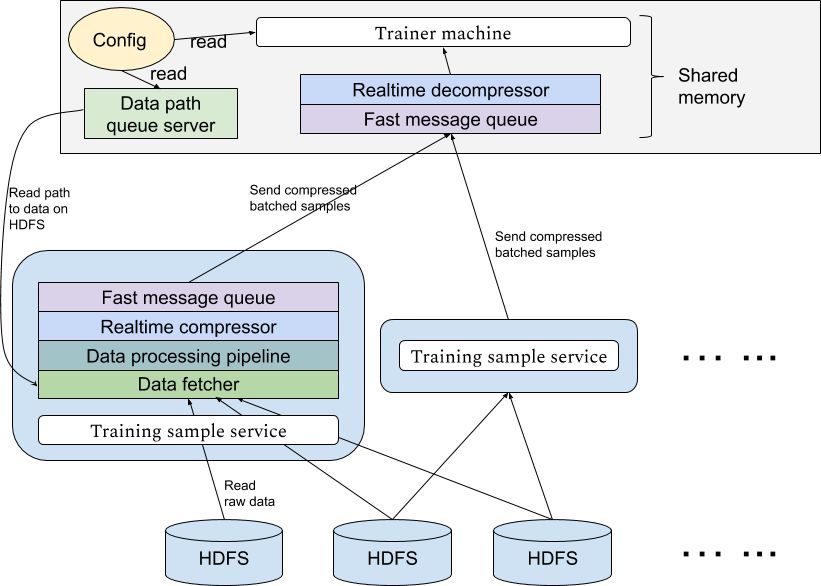
2. 实时训练
由于 Persia 的数据处理任务在获取数据时完全依赖于训练机的指示,Persia 支持对刚刚生成的数据进行在线训练的场景,只需要使 queue server 返回最近生成的数据文件即可。因此,Persia 在训练时的数据读取模式上非常灵活,对 queue server 非常简单的修改即可支持任意数据读取的顺序,甚至可以一边训练一边决定下一步使用什么数据。
3. 更快的数据读取速度:训练机共享内存读取数据
由于训练机要同时接收从不同数据处理任务发送来的大量数据,并进行解压缩和传输给训练进程进行实际训练的操作,接收端必须能够进行并行解压和高速数据传输。为此,Persia 使用 ZeroMQ device 接收多个任务传输而来的压缩数据,并使用多个解压进程读取该 device。每个解压进程独立进行解压,并与训练进程共享内存。当结束解压后,解压进程会将可以直接使用的 batch 样本放入共享内存中,训练任务即可直接使用该 batch 进行训练,而无需进一步的序列化反序列化操作。
训练效果
Persia 系统在单机上目前实现了如下训练效果:
数据大小:百 T 数据。
样本数量:25 亿训练样本。
8 卡 V100 计算机,25Gb 带宽:总共 1 小时训练时间,每秒 64 万样本。
8 卡 1080Ti 计算机,10Gb 带宽:总共不到 2 小时训练时间,每秒 40 万样本。
4 卡 1080Ti 达 30 万样本 / 秒,2 卡 1080Ti 达 20 万样本 / 秒。
Persia 同样数据上 Test AUC 高于原 ASGD CPU 平台。
Persia 支持很大 batch size,例如 25k。
综上,Persia 不仅训练速度上远远超过 CPU 平台,并且大量节省了计算资源,使得同时尝试多种实验变得非常方便。
展望:分布式多机训练
In the future, the Persia system will carry out distributed multi-GPU computer training. Different from mature tasks such as computer vision, due to the large increase in the size of the model in advertising tasks, the traditional distributed training method faces the synchronization bottleneck between computers, which will greatly reduce the training efficiency. The Persia system will support decentralized gradient compression training algorithms with lower communication costs and stronger system disaster tolerance. According to Liu Ji, head of the Kuaishou FeDA Intelligent Decision Lab, the algorithm combines the emerging asynchronous decentralized parallel stochastic gradient descent (ICML 2018) and the gradient compression compensation algorithm (Doublesqueeze: parallel stochastic gradient descent with double-pass). Error-compensated compression, ICML 2019), and with strict theoretical guarantees, the Kuaishou Persia system is expected to achieve several to tens of times higher efficiency on the basis of a single machine in the multi-machine scenario.