Ketlle provides a connection configuration module for the hadoop cluster. Before configuring the "Hadoop cluster", do some preparatory work. Copy the relevant configuration files in the cluster to the directory in the kettle, and replace the files in the original directory.
1. Required configuration files: core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml, hbase-site.xml, hive-site.xml, the first four of these configuration files It is necessary to connect to Hadoop. The latter two depend on specific requirements. If they are also needed, they need to be copied in the cluster.
2. File storage path: E:\kettle-8.2\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\cdh514 The
last level of the directory mainly depends on the big data platform used, from the cluster Just replace the copied configuration file with the file in the original directory.
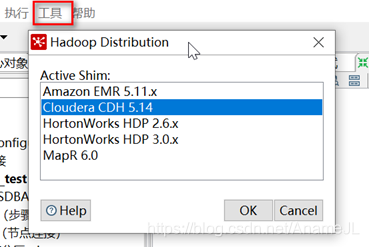
3. Then click "Tools" in the upper left corner of the kettle -> click "Hadoop Distribution" -> select the type corresponding to the server big data platform, as shown in the figure below
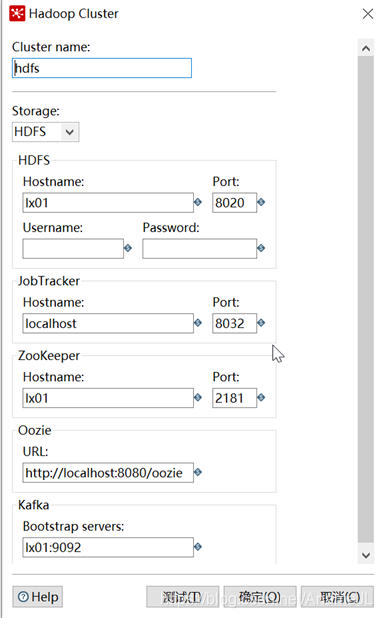
4. After the preparation work is completed, right-click "Hadoop cluster" -> New , The specific configuration content is determined by the software in the cluster, as shown in the figure below.
5. After the configuration is completed, click Test. If the content shown in the figure below appears, it
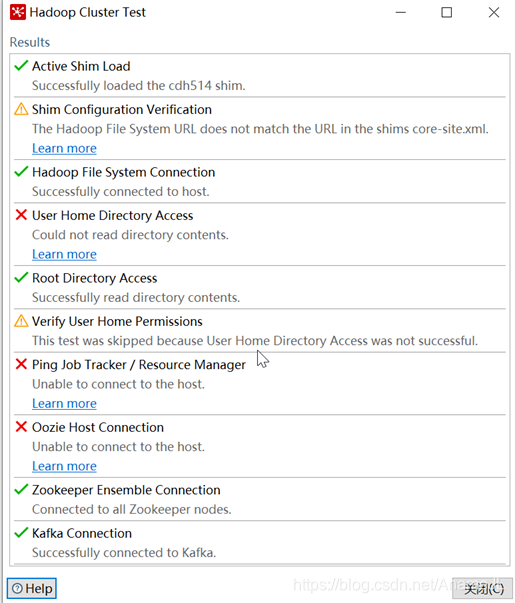
can be seen that it is connected. The software configured according to the actual situation of the big data platform has been The connection is established (provided that the services are all enabled), after the connection is configured, you can directly select the connection using the relevant components in the subsequent steps.