Big data overview||| hadoop ecosystem||| hadoop cluster construction||| Hadoop configuration JobHistory ||| port number
- 1. What is big data?
- Two, hadoop ecosystem
- Three, hadoop cluster construction
-
- 1. Treat the configured virtual machine as the master node and clone two new virtual machines.
- 2. Pass the hadoop folder and configuration file /etc/profile of the host to the other two virtual machines
- 3. Modify the configuration file on the host
- 4. Delete logs and tmp, format the first host (note: all three machines need to be deleted successfully)
- 5. Open on the first machine and enter jps to verify
- Four, Hadoop configuration JobHistory
- Five, Hadoop commonly used port numbers
1. What is big data?
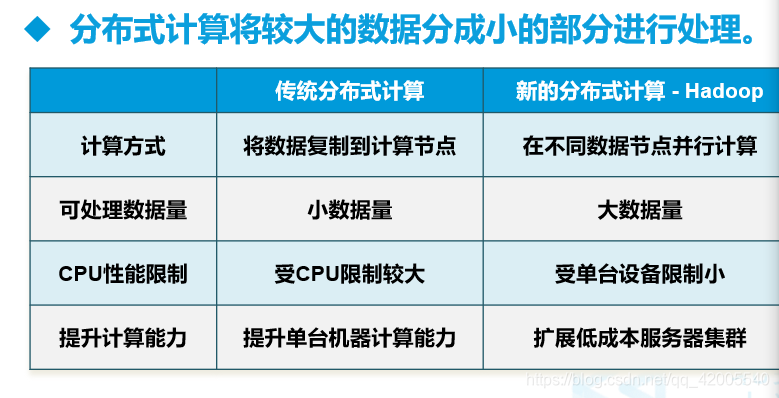
Big data refers to a collection of data whose content cannot be captured, managed and processed with conventional software tools within a certain period of time. It
has 4V characteristics: large data volume, fast speed, diversification, and low value density
Two, hadoop ecosystem
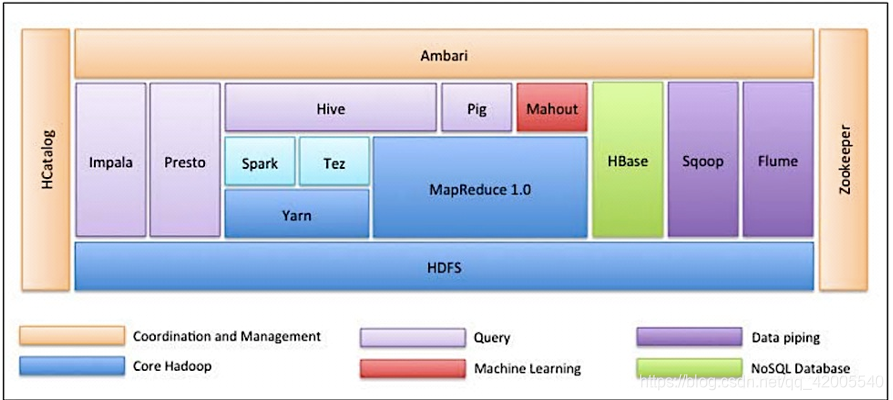
2.1 hadoop 2.0 framework
2.2 The concept of hadoop
Official website definition:
Hadoop is a distributed system infrastructure developed by the Apache Foundation. Users can develop distributed programs without understanding the underlying details of distributed systems. Make full use of the power of clusters for high-speed computing and storage.
So, Hadoop mainly solves the problem of storage and calculation of massive data. It can be used to build large-scale data warehouses, PB-level data storage, processing, analysis, statistics and other businesses .
Hadoop can be divided into two types: narrow sense and broad sense:
1. Hadoop in a narrow sense is just Hadoop itself, a distributed system architecture, including: (HDFS+MapReduce+yarn).
2. Hadoop in a broad sense refers to the Hadoop ecosystem. The Hadoop ecosystem is a very large concept. Hadoop is the most important and basic part of it: each subsystem of the ecosystem only solves a specific problem domain. To engage in a unified all-round system, but a small and sophisticated multiple small systems.
2.3 Introduction to the main components in the hadoop ecosystem:
HDFS
Hadoop distributed file system. It is the foundation of data storage management in the Hadoop system. It is a highly fault-tolerant system that can detect and respond to hardware failures and is used to run on low-cost general-purpose hardware. HDFS simplifies the consistency model of files, provides high-throughput application data access functions through streaming data access, and is suitable for applications with large data sets.
MapReduce (distributed computing framework)
MapReduce is a computing model for computing large amounts of data. Among them, Map performs specified operations on independent elements on the data set to generate intermediate results in the form of key-value pairs. Reduce reduces all the "values" of the same "key" in the intermediate result to get the final result. The functional division of MapReduce is very suitable for data processing in a distributed parallel environment composed of a large number of computers.
Hive (Hadoop-based data warehouse)
Hive defines a SQL-like query language (HQL) that converts SQL into MapReduce tasks and executes them on Hadoop. Usually used for offline analysis.
Hbase (distributed column storage database)
HBase is a scalable, highly reliable, high-performance, distributed and column-oriented dynamic database for structured data. Unlike traditional relational databases, HBase uses BigTable's data model: an enhanced sparse sort mapping table (Key/Value), where the key is composed of row keys, column keys, and timestamps. HBase provides random, real-time read and write access to large-scale data. At the same time, the data stored in HBase can be processed using MapReduce, which perfectly combines data storage and parallel computing.
Zookeeper (distributed collaborative service)
solves data management problems in a distributed environment: unified naming, state synchronization, cluster management, configuration synchronization, etc.
Sqoop (data synchronization tool)
Sqoop is the abbreviation of SQL-to-Hadoop, which is mainly used to transfer data before traditional databases and Hadoop. The import and export of data are essentially Mapreduce programs, making full use of the parallelization and fault tolerance of MR.
Pig (a data flow system based on Hadoop)
is open sourced by yahoo!, and the design motivation is to provide an ad-hoc (calculation occurs during query) data analysis tool based on MapReduce. A data flow language—Pig Latin is defined, which converts scripts into MapReduce tasks and executes them on Hadoop. Usually used for offline analysis.
Mahout (Data Mining Algorithm Library)
Mahout's main goal is to create some scalable implementations of classic algorithms in the field of machine learning, aiming to help developers create smart applications more conveniently and quickly. Mahout now includes widely used data mining methods such as clustering, classification, recommendation engines (collaborative filtering), and frequent set mining. In addition to algorithms, Mahout also includes data mining support architectures such as data input/output tools, integration with other storage systems (such as databases, MongoDB or Cassandra).
Flume (log collection tool)
Cloudera's open source log collection system is distributed, highly reliable, highly fault-tolerant, easy to customize and expand. It abstracts the process of data generation, transmission, processing, and finally written into the target path into a data stream. In a specific data stream, the data source supports customizing the data sender in Flume, thereby supporting the collection of various protocol data. At the same time, the Flume data stream provides the ability to perform simple processing on log data, such as filtering and format conversion. In addition, Flume also has the ability to write logs to various data targets (customizable). In general, Flume is a scalable, massive log collection system suitable for complex environments.
2.4 The three core components of hadoop
The three core components of Hadoop are:
HDFS (Hadoop Distribute File System): Hadoop's data storage tool.
YARN (Yet Another Resource Negotiator, another resource coordinator): Hadoop resource manager.
Hadoop MapReduce: a distributed computing framework
HDFS architecture
HDFS adopts the Master/slave architecture model, 1 Master (NameNode/NN) with N Slaves (DataNode/DN).
From an internal point of view, the data block is stored on the DataNode. The NameNode executes the namespace of the file system, such as opening, closing, and renaming files or directories, and is also responsible for the mapping of data blocks to specific DataNodes. The DataNode is responsible for processing file reads and writes on the client side of the file system, and creates, deletes, and replicates the database under the unified scheduling of the NameNode. The NameNode is the manager of all HDFS metadata, and user data never passes through the NameNode.
NN:
1) Responsible for the response to the client request
2) Responsible for the management of metadata (name of the file, copy coefficient, DN of Block storage)
DN:
1) Store the data block corresponding to the user's file (Block)
2) Regularly send heartbeat information to NN, report itself and all block information, and health status
HDFS write data process

HDFS read data process

Three, hadoop cluster construction
1. Treat the configured virtual machine as the master node and clone two new virtual machines.
(Refer to the blog for the configuration process: the previous blog Hadoop configuration )
Steps to be operated after cloning:
(1) Modify the IP: vi /etc/sysconfig/network-scripts/ifcfg-ens33
Replace the cloned virtual machine with a different ip address
(2) Restart the network: systemctl restart network
(3) Add mutual trust to the three hosts (see steps Blog: add each other )
2. Pass the hadoop folder and configuration file /etc/profile of the host to the other two virtual machines
[root@hadoop2 software]# scp -r hadoop root@hadoop5:$PWD #@后写要传对象的主机名
[root@hadoop2 software]# scp /etc/profile root@hadoop7:/etc/profile
In this way, the hadoop folder and profile will be transferred to the same location in hadoop5 and hadoop7 as the host
3. Modify the configuration file on the host
(1) Modify vi etc/hadoop/hdfs-site.xml
在root/software/hadoop路径下输入:
[root@hadoop2 hadoop]# vi etc/hadoop/hdfs-site.xml
或者在root/software/hadoop/etc/hadoop路径下输入:
[root@hadoop2 hadoop]# vi hdfs-site.xml
Change the number of copies to 3 and
change the ip of the secondary machine to the ip of the second machine
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.21.5:50090</value>
</property>
</configuration>
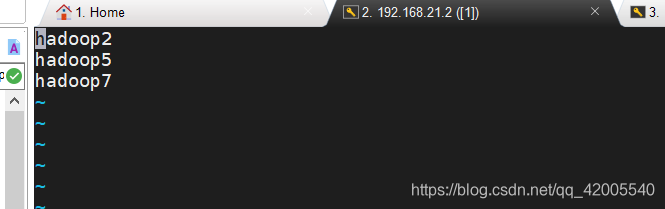
(2) Configure vi /etc/slaves
Add the hostnames of three machines, all three virtual machines must be added
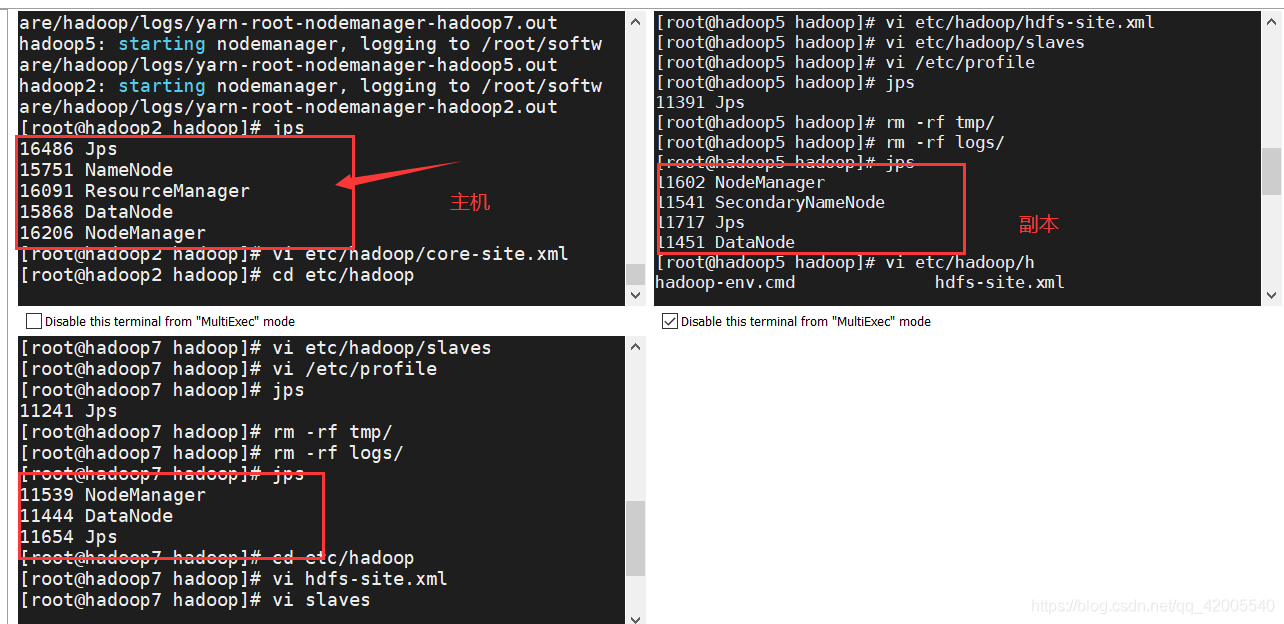
4. Delete logs and tmp, format the first host (note: all three machines need to be deleted successfully)
[root@hadoop2 hadoop]# rm -rf logs/
[root@hadoop2 hadoop]# rm -rf tmp/
[root@hadoop2 hadoop]# hdfs namenode -format
5. Open on the first machine and enter jps to verify
[root@hadoop2 hadoop]# start-all.sh
Four, Hadoop configuration JobHistory
4.1 What does jobhistory do?
View historical operation steps
4.2 Configuration and operation steps for using jobhistory
Step 1: Configure the vi mapred-site.xml file
[root@hadoop2 software]# cd hadoop
[root@hadoop2 hadoop]# vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop2:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop2:19888</value>
</property>
</configuration>
Step 2: Start jobhistory
[root@hadoop2 hadoop]# sbin/mr-jobhistory-daemon.sh start
historyserver
can view the process by jps after startup
[root@hadoop2 hadoop]# sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /root/software/hadoop/logs/mapred-root-historyserver-hadoop2.out
[root@hadoop2 hadoop]# jps
11298 NodeManager
11172 ResourceManager
11849 JobHistoryServer
10942 DataNode
10815 NameNode
11919 Jps
[root@hadoop2 hadoop]#
4.3 Test
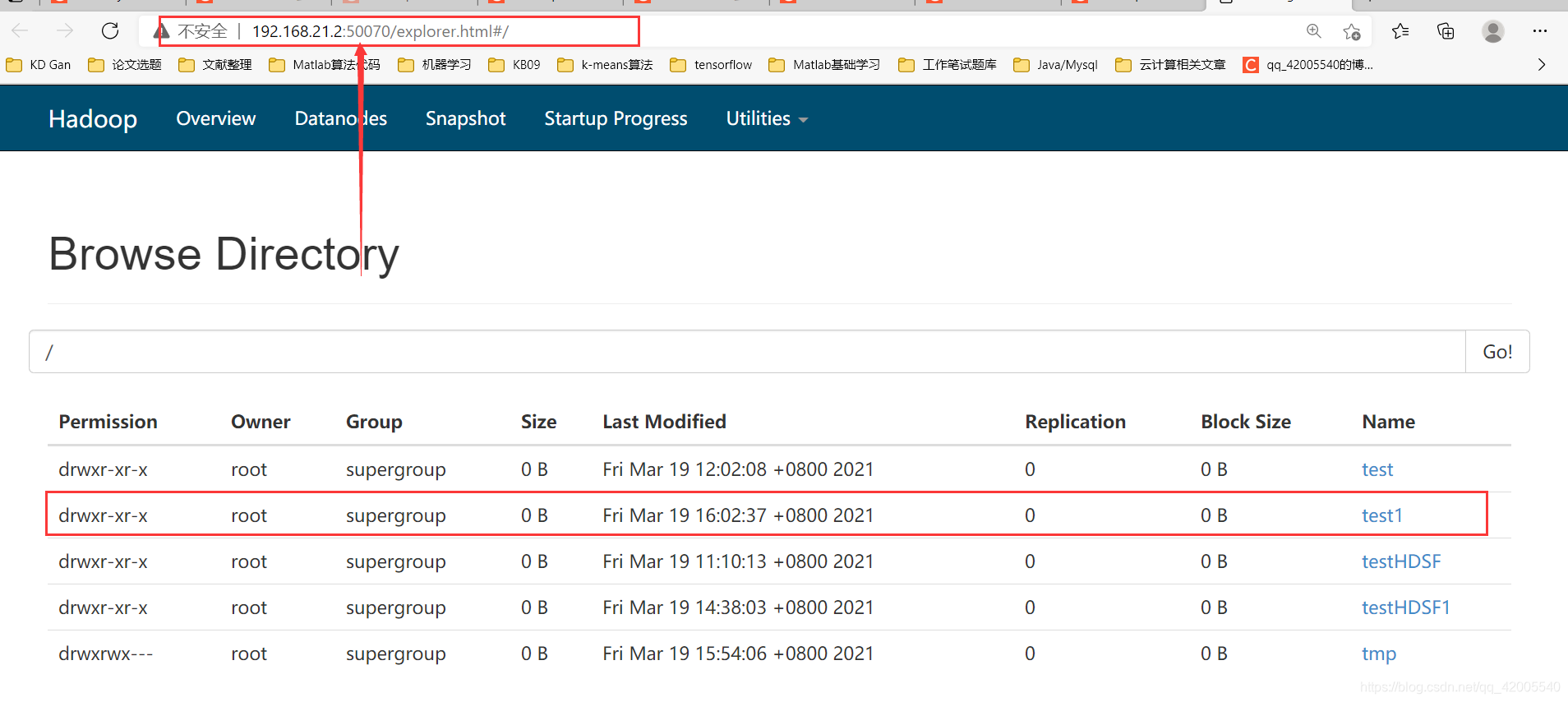
The first step: first create a test folder on hdfs
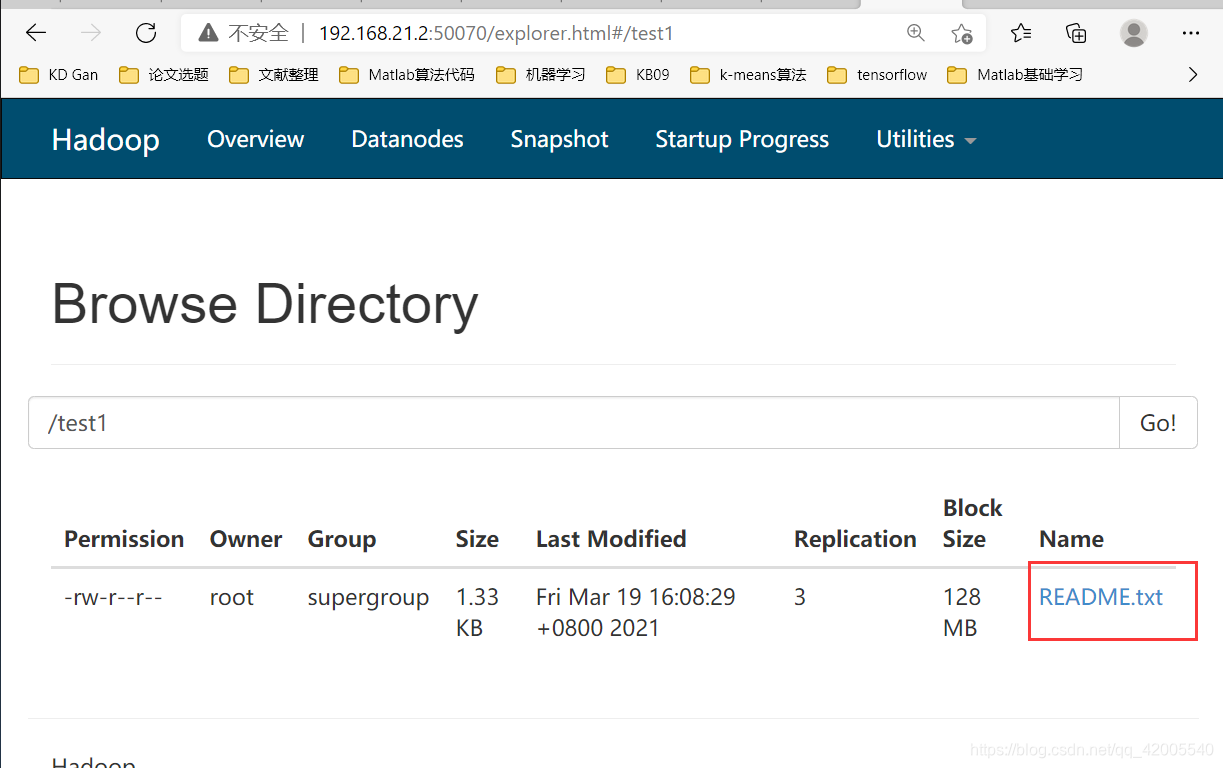
[root@hadoop2 hadoop]# hdfs dfs -mkdir /test1
Step 2: Log in to the browser to check whether the creation is successful
Step 3: Upload any file
[root@hadoop2 hadoop]# hdfs dfs -put README.txt /test1
hdfs dfs -put 路径/README.txt /test
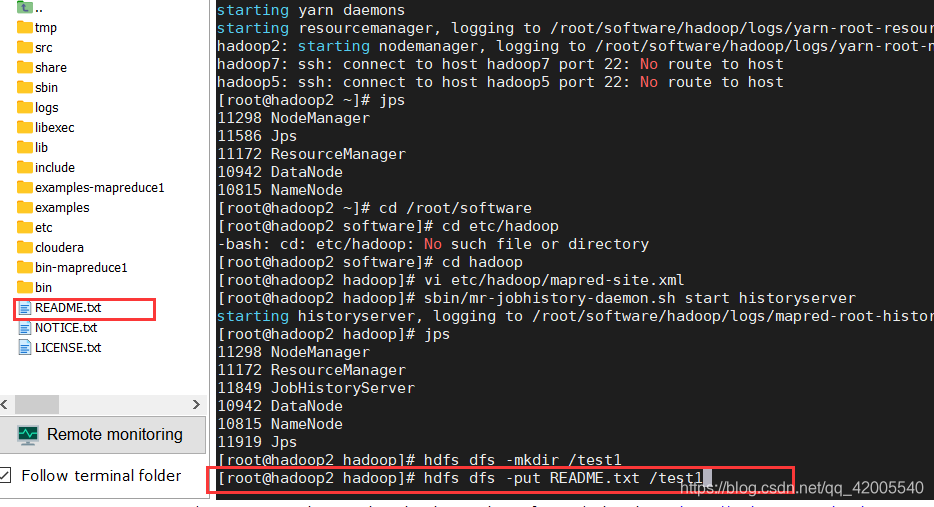
Enter the browser to see if the upload is successful
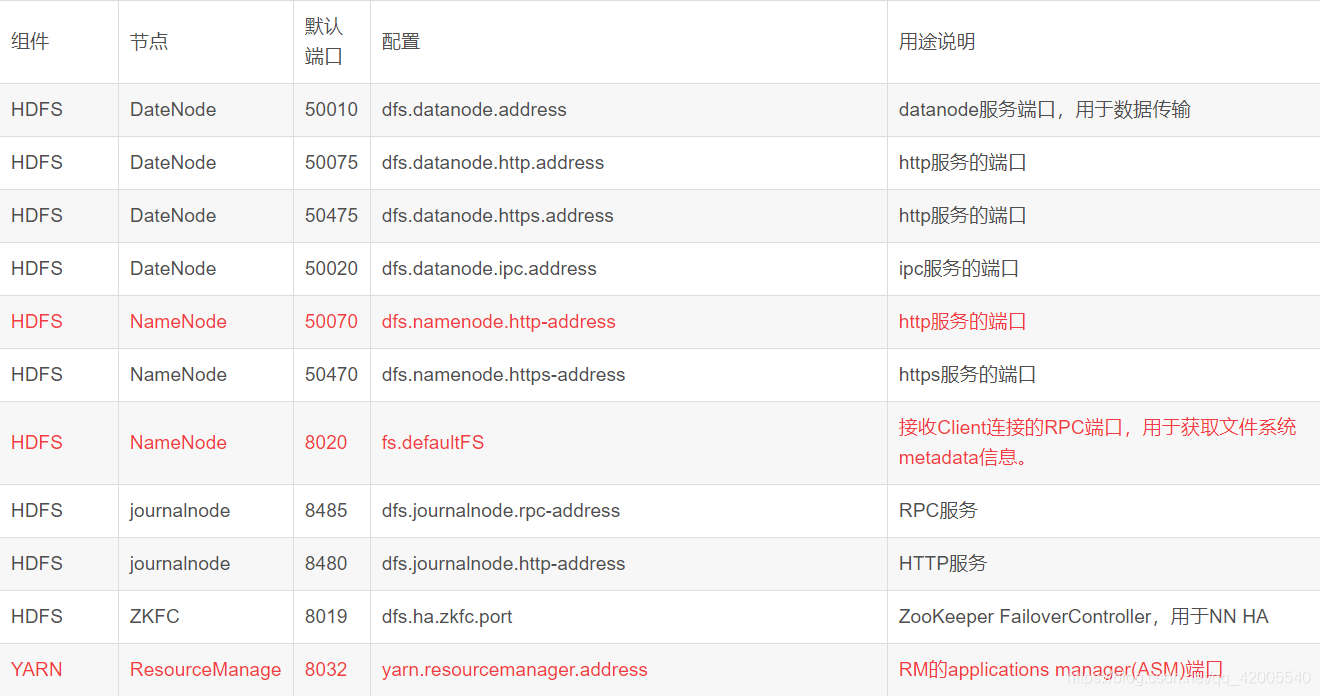
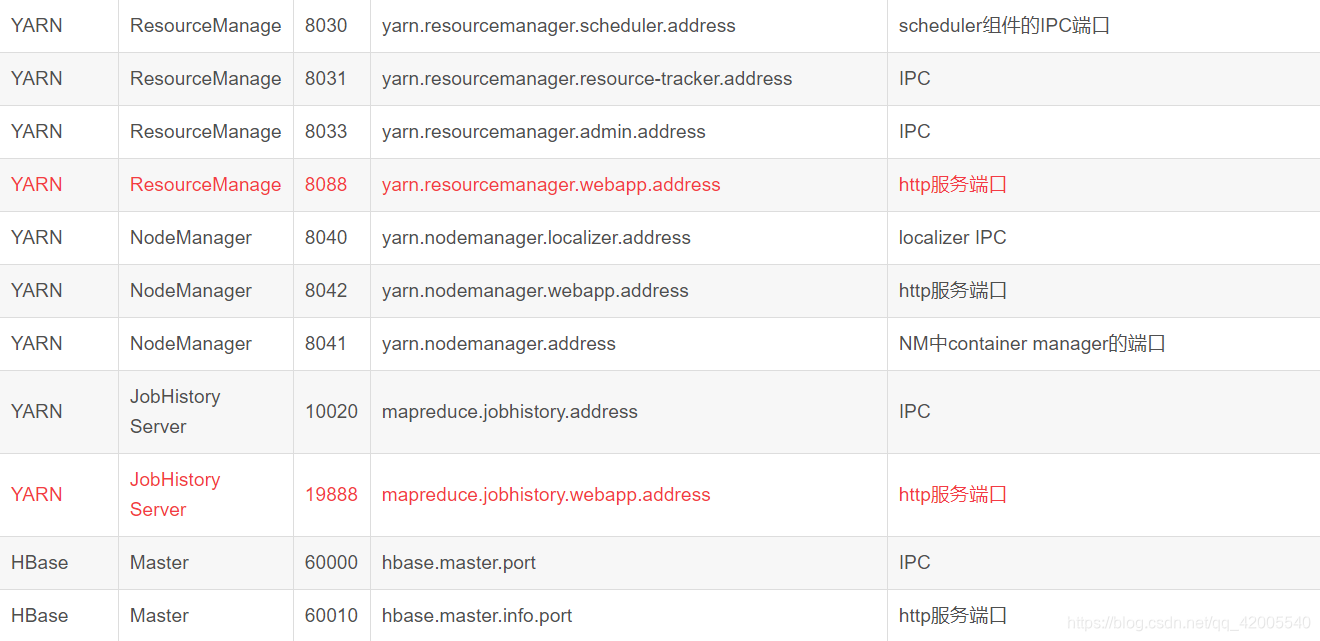
Five, Hadoop commonly used port numbers