Big Data technologies kettle
Chapter 1 kettle Overview
1.1 What is the kettle
kettle is an open source ETL tool, written in pure java, runs on Windows, Linux, Unix, green without having to install, highly efficient and stable data extraction.
1.2 kettle core knowledge points
1.2.1 kettle storage project
1) is stored in XML
2) stored in a repository (database repository and document repository)
1.2.2 kettle of two designs
Description: Transformation (conversion): complete basis for data conversion.
Job (operation): complete control of the entire workflow.
Differences: (1) is a step of job stream, the data stream is converted.
Each step (2) operation must wait until the previous steps following step will finish execution; and a one-time conversion to start all the controls all (corresponding to a control to start a thread), then from the first data stream will be a control start, a record, a control flow of the last record.
1.2.3 Kettle consisting of
1. spoon (Spoon.bat / spoon.sh): is a graphical interface that allows us to develop and conversion work with graphical way. Select Windows .bat; Linux select .sh
2. frying pan (Pan.bat / pan.sh): Pan can be invoked using the Trans form of the command line
3. Kitchen (Ktitchen.bat / kitchen.sh): You can use the command line using the Kitchen call Job
4. Menu (Carte.bat / carte.sh): Carte is a lightweight Web container, for the establishment of a dedicated, remote ETL Server.
1.3 kettle features
Chapter 2 Installation kettle to deploy and use
2.1 kettle installation address
Official website address:
https://community.hitachivantara.com/s/article/data-integration-kettle
download link:
https://sourceforge.net/projects/pentaho/files/
Under 2.2 Windows installation
2.2.1 Overview
Are carried kettle in the local environment in the actual business development Job Development and Transformation can be run locally, you can also connect to a remote machine running.
2.2.2 Installation
1) install jdk
download link:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Agree to the agreement, and then download the corresponding version of jdk (windows x64)
Download software, double-click the installation
Next to continue (note path)
Next Wait for the installation to complete.
2) Download the archive kettle, kettle because green software, unzip to any local path to the
3) Double-click Spoon.bat, start the graphical interface tool that you can use
A stu1 case data by id synchronized to stu2, stu2 data is updated with the same id
Create two tables in mysql
| mysql>create database kettle; mysql>use kettle; mysql>create table stu1 (id int ,name varchar(20),age int); mysql>create table stu2 (id int ,name varchar(20));
mysql>insert into stu1 values(1001,’zhangsan’,20),(1002,’lisi’,18),(1003,’wangwu’,23); mysql>insert into stu2 values(1001,’wukong’); |
In the kettle in New Conversion
Click the top left corner of File - New - transition to a core object interface, click enter, find the input table dragged into the middle
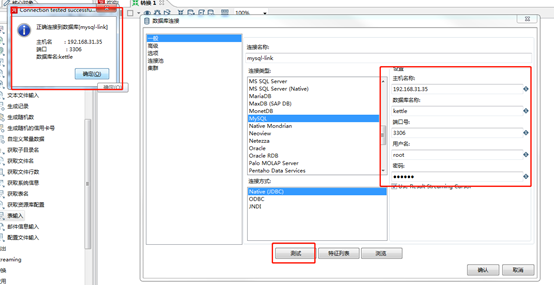
Double-table input configured mysql database connected to the database connection (note jar package mysql-connector-java-5.1.34-bin.jar kettle to be placed in the folder lib)
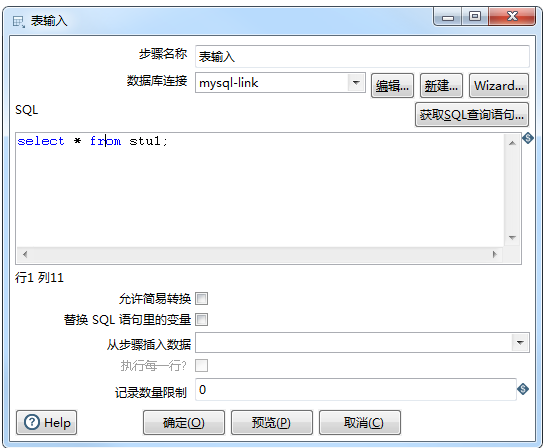
Enter the sql statement select * from stu1;
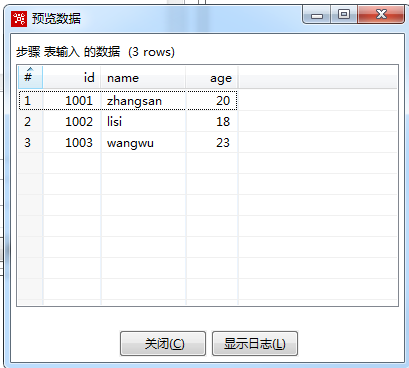
Click Preview can see the data
Found inserted in the output / update component to the intermediate drag, tap and hold the left mouse button table shift + input is connected to the insert / update component

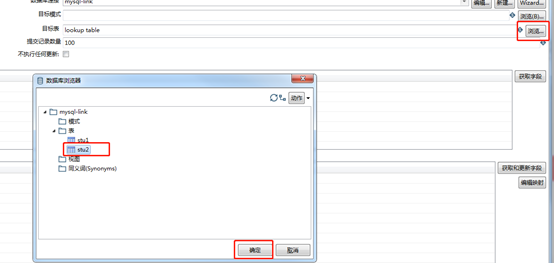
Double-click Insert / Update, click the target table browse, select stu2
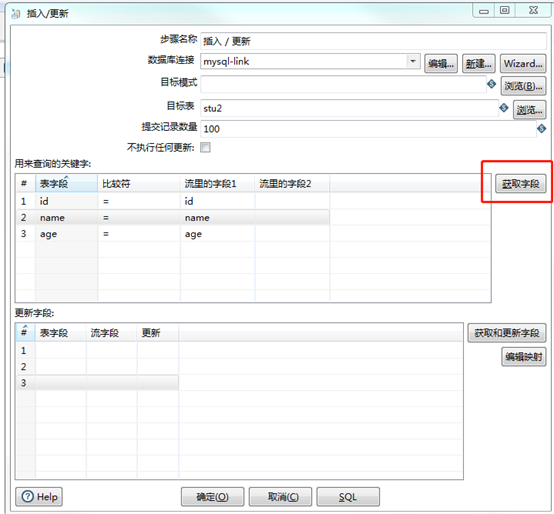
Click for the field to get 3 fields
Since stu1 the id associated with stu2, so remove the other two fields and click edit the mapping, the mapping between the two edit table
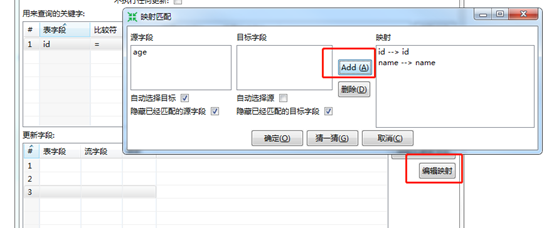
FIG determined after
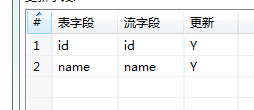
Updating process, modify the id attribute is n, determined
Save operation, see the results in the database.