Preface
Shopping coupon https://m.cqfenfa.com/SuperEdge service group uses application-grid-wrapper to realize topology awareness and completes closed-loop access to services in the same nodeunit
Before analyzing the application-grid-wrapper in depth, here is a brief introduction to the topology-aware features natively supported by the community Kubernetes
The alpha version of the Kubernetes service topology awareness feature was released in v1.17 to implement routing topology and nearby access features. The user needs to add the topologyKeys field to the service to indicate the topology key type. Only endpoints with the same topology domain will be accessed. There are currently three topologyKeys to choose from:
- "kubernetes.io/hostname": access
kubernetes.io/hostnamethe endpoint in this node (the same label value), if there is no endpoint, the service access fails - "topology.kubernetes.io/zone": access
topology.kubernetes.io/zoneendpoints in the same zone ( same label value), if not, the service access will fail - "topology.kubernetes.io/region": access
topology.kubernetes.io/regionendpoints in the same region ( same label value), if not, the service access will fail
In addition to filling in one of the above topological keys individually, you can also construct these keys into a list to fill in, for example:, ["kubernetes.io/hostname", "topology.kubernetes.io/zone", "topology.kubernetes.io/region"]this means: priority access to the endpoint in this node; if it does not exist, access to the endpoint in the same zone; if If it does not exist anymore, access the endpoint in the same region, if it does not exist, the access will fail
In addition, you can also add "*" at the end of the list (only the last item) to indicate: if the previous topology domains fail, then any valid endpoint is accessed, that is, there is no restriction on the topology. Examples are as follows:
# A Service that prefers node local, zonal, then regional endpoints but falls back to cluster wide endpoints.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 9376
topologyKeys:
- "kubernetes.io/hostname"
- "topology.kubernetes.io/zone"
- "topology.kubernetes.io/region"
- "*"
The topology awareness and community comparison implemented by service group have the following differences:
- The service group topology key can be customized, that is, gridUniqKey, which is more flexible to use. There are currently only three options for community implementation: "kubernetes.io/hostname", "topology.kubernetes.io/zone" and "topology.kubernetes. io/region"
- The service group can only fill in one topology key, that is, it can only access the valid endpoints in this topology domain, and cannot access the endpoints of other topology domains; and the community can access other alternative topology domain endpoints through the topologyKey list and "*"
Topology awareness implemented by service group, service configuration is as follows:
# A Service that only prefers node zone1al endpoints.
apiVersion: v1
kind: Service
metadata:
annotations:
topologyKeys: '["zone1"]'
labels:
superedge.io/grid-selector: servicegrid-demo
name: servicegrid-demo-svc
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
appGrid: echo
After introducing the topology awareness implemented by the service group, we dive into the source code analysis and implementation details. Similarly, here is a usage example to start the analysis:
# step1: labels edge nodes
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node0 Ready <none> 16d v1.16.7
node1 Ready <none> 16d v1.16.7
node2 Ready <none> 16d v1.16.7
# nodeunit1(nodegroup and servicegroup zone1)
$ kubectl --kubeconfig config label nodes node0 zone1=nodeunit1
# nodeunit2(nodegroup and servicegroup zone1)
$ kubectl --kubeconfig config label nodes node1 zone1=nodeunit2
$ kubectl --kubeconfig config label nodes node2 zone1=nodeunit2
...
# step3: deploy echo ServiceGrid
$ cat <<EOF | kubectl --kubeconfig config apply -f -
apiVersion: superedge.io/v1
kind: ServiceGrid
metadata:
name: servicegrid-demo
namespace: default
spec:
gridUniqKey: zone1
template:
selector:
appGrid: echo
ports:
- protocol: TCP
port: 80
targetPort: 8080
EOF
servicegrid.superedge.io/servicegrid-demo created
# note that there is only one relevant service generated
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 192.168.0.1 <none> 443/TCP 16d
servicegrid-demo-svc ClusterIP 192.168.6.139 <none> 80/TCP 10m
# step4: access servicegrid-demo-svc(service topology and closed-looped)
# execute on node0
$ curl 192.168.6.139|grep "node name"
node name: node0
# execute on node1 and node2
$ curl 192.168.6.139|grep "node name"
node name: node2
$ curl 192.168.6.139|grep "node name"
node name: node1
After the ServiceGrid CR is created, the ServiceGrid Controller is responsible for generating the corresponding service (including the topologyKeys annotations composed of serviceGrid.Spec.GridUniqKey) according to the ServiceGrid; the application-grid-wrapper realizes topology awareness according to the service, and the following analysis is in order.
ServiceGrid Controller analysis
The logic of ServiceGrid Controller is the same as that of DeploymentGrid Controller as a whole, as follows:
- 1. Create and maintain a number of CRDs (including: ServiceGrid) required by the service group
- 2. Monitor the ServiceGrid event, and fill the ServiceGrid into the work queue; cyclically take out the ServiceGrid from the queue for analysis, create and maintain the corresponding service
- 3. Monitor the service event, and stuff the related ServiceGrid into the work queue for the above processing to assist the above logic to achieve the overall reconcile logic
Note that this is different from DeploymentGrid Controller:
- A ServiceGrid object generates only one service
- Only need to monitor the service event additionally, no need to monitor the node event. Because node's CRUD has nothing to do with ServiceGrid
- ServiceGrid corresponds to the generated service, named as:
{ServiceGrid}-svc
func (sgc *ServiceGridController) syncServiceGrid(key string) error {
startTime := time.Now()
klog.V(4).Infof("Started syncing service grid %q (%v)", key, startTime)
defer func() {
klog.V(4).Infof("Finished syncing service grid %q (%v)", key, time.Since(startTime))
}()
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
sg, err := sgc.svcGridLister.ServiceGrids(namespace).Get(name)
if errors.IsNotFound(err) {
klog.V(2).Infof("service grid %v has been deleted", key)
return nil
}
if err != nil {
return err
}
if sg.Spec.GridUniqKey == "" {
sgc.eventRecorder.Eventf(sg, corev1.EventTypeWarning, "Empty", "This service grid has an empty grid key")
return nil
}
// get service workload list of this grid
svcList, err := sgc.getServiceForGrid(sg)
if err != nil {
return err
}
if sg.DeletionTimestamp != nil {
return nil
}
// sync service grid relevant services workload
return sgc.reconcile(sg, svcList)
}
func (sgc *ServiceGridController) getServiceForGrid(sg *crdv1.ServiceGrid) ([]*corev1.Service, error) {
svcList, err := sgc.svcLister.Services(sg.Namespace).List(labels.Everything())
if err != nil {
return nil, err
}
labelSelector, err := common.GetDefaultSelector(sg.Name)
if err != nil {
return nil, err
}
canAdoptFunc := controller.RecheckDeletionTimestamp(func() (metav1.Object, error) {
fresh, err := sgc.crdClient.SuperedgeV1().ServiceGrids(sg.Namespace).Get(context.TODO(), sg.Name, metav1.GetOptions{})
if err != nil {
return nil, err
}
if fresh.UID != sg.UID {
return nil, fmt.Errorf("orignal service grid %v/%v is gone: got uid %v, wanted %v", sg.Namespace,
sg.Name, fresh.UID, sg.UID)
}
return fresh, nil
})
cm := controller.NewServiceControllerRefManager(sgc.svcClient, sg, labelSelector, util.ControllerKind, canAdoptFunc)
return cm.ClaimService(svcList)
}
func (sgc *ServiceGridController) reconcile(g *crdv1.ServiceGrid, svcList []*corev1.Service) error {
var (
adds []*corev1.Service
updates []*corev1.Service
deletes []*corev1.Service
)
sgTargetSvcName := util.GetServiceName(g)
isExistingSvc := false
for _, svc := range svcList {
if svc.Name == sgTargetSvcName {
isExistingSvc = true
template := util.KeepConsistence(g, svc)
if !apiequality.Semantic.DeepEqual(template, svc) {
updates = append(updates, template)
}
} else {
deletes = append(deletes, svc)
}
}
if !isExistingSvc {
adds = append(adds, util.CreateService(g))
}
return sgc.syncService(adds, updates, deletes)
}
func CreateService(sg *crdv1.ServiceGrid) *corev1.Service {
svc := &corev1.Service{
ObjectMeta: metav1.ObjectMeta{
Name: GetServiceName(sg),
Namespace: sg.Namespace,
// Append existed ServiceGrid labels to service to be created
Labels: func() map[string]string {
if sg.Labels != nil {
newLabels := sg.Labels
newLabels[common.GridSelectorName] = sg.Name
newLabels[common.GridSelectorUniqKeyName] = sg.Spec.GridUniqKey
return newLabels
} else {
return map[string]string{
common.GridSelectorName: sg.Name,
common.GridSelectorUniqKeyName: sg.Spec.GridUniqKey,
}
}
}(),
Annotations: make(map[string]string),
},
Spec: sg.Spec.Template,
}
keys := make([]string, 1)
keys[0] = sg.Spec.GridUniqKey
keyData, _ := json.Marshal(keys)
svc.Annotations[common.TopologyAnnotationsKey] = string(keyData)
return svc
}
Since the logic is similar to DeploymentGrid, the details will not be expanded here, and focus on the application-grid-wrapper part
application-grid-wrapper 分析
After the ServiceGrid Controller creates the service, the role of application-grid-wrapper starts:
apiVersion: v1
kind: Service
metadata:
annotations:
topologyKeys: '["zone1"]'
creationTimestamp: "2021-03-03T07:33:30Z"
labels:
superedge.io/grid-selector: servicegrid-demo
name: servicegrid-demo-svc
namespace: default
ownerReferences:
- apiVersion: superedge.io/v1
blockOwnerDeletion: true
controller: true
kind: ServiceGrid
name: servicegrid-demo
uid: 78c74d3c-72ac-4e68-8c79-f1396af5a581
resourceVersion: "127987090"
selfLink: /api/v1/namespaces/default/services/servicegrid-demo-svc
uid: 8130ba7b-c27e-4c3a-8ceb-4f6dd0178dfc
spec:
clusterIP: 192.168.161.1
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
appGrid: echo
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
In order to achieve zero intrusion of Kubernetes, it is necessary to add a layer of wrapper between the communication between kube-proxy and apiserver. The architecture is as follows:
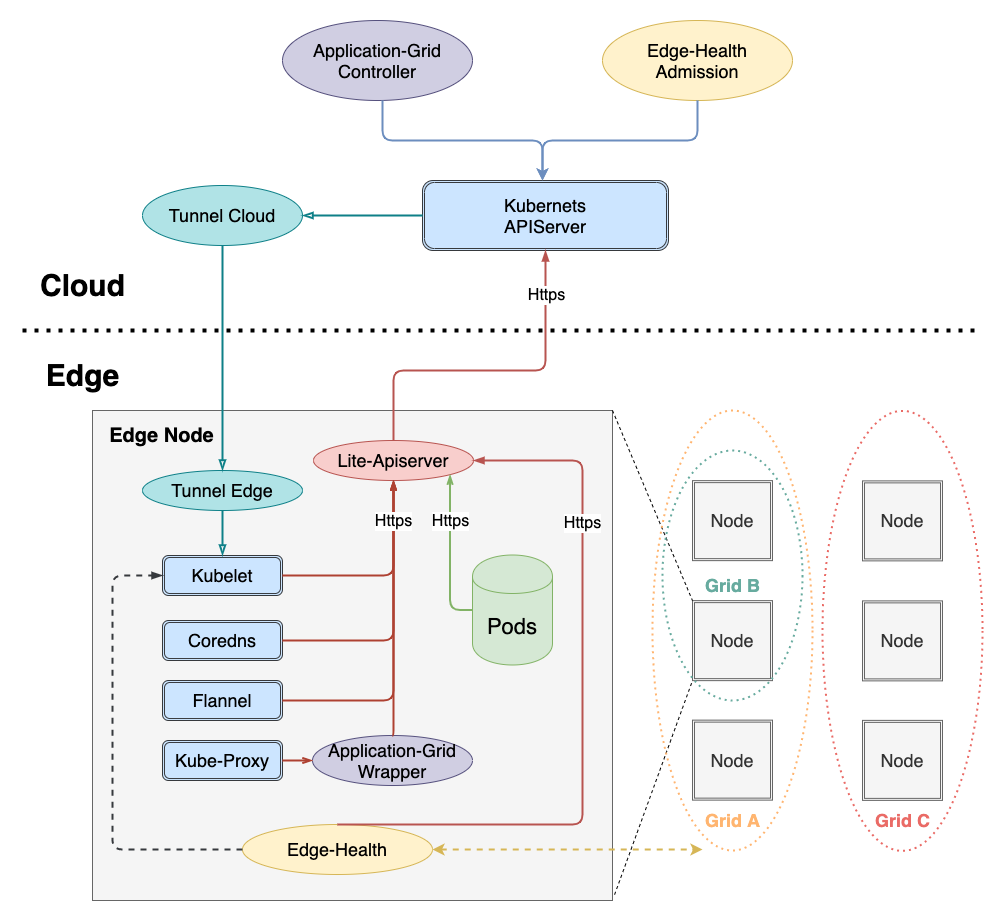
The call link is as follows:
kube-proxy -> application-grid-wrapper -> lite-apiserver -> kube-apiserver
Therefore, application-grid-wrapper will serve and accept requests from kube-proxy, as follows:
func (s *interceptorServer) Run(debug bool, bindAddress string, insecure bool, caFile, certFile, keyFile string) error {
...
klog.Infof("Start to run interceptor server")
/* filter
*/
server := &http.Server{Addr: bindAddress, Handler: s.buildFilterChains(debug)}
if insecure {
return server.ListenAndServe()
}
...
server.TLSConfig = tlsConfig
return server.ListenAndServeTLS("", "")
}
func (s *interceptorServer) buildFilterChains(debug bool) http.Handler {
handler := http.Handler(http.NewServeMux())
handler = s.interceptEndpointsRequest(handler)
handler = s.interceptServiceRequest(handler)
handler = s.interceptEventRequest(handler)
handler = s.interceptNodeRequest(handler)
handler = s.logger(handler)
if debug {
handler = s.debugger(handler)
}
return handler
}
Here, the interceptorServer will be created first, and then the processing functions will be registered, as follows from the outside to the inside:
-
debug: accept debug request and return the running information of wrapper pprof
-
logger: print request log
-
node: accept kube-proxy node GET(/api/v1/nodes/{node}) request and return node information
-
event: accept kube-proxy events POST (/events) request and forward the request to lite-apiserver
func (s *interceptorServer) interceptEventRequest(handler http.Handler) http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { if r.Method != http.MethodPost || !strings.HasSuffix(r.URL.Path, "/events") { handler.ServeHTTP(w, r) return } targetURL, _ := url.Parse(s.restConfig.Host) reverseProxy := httputil.NewSingleHostReverseProxy(targetURL) reverseProxy.Transport, _ = rest.TransportFor(s.restConfig) reverseProxy.ServeHTTP(w, r) }) } -
service: accept kube-proxy service List&Watch(/api/v1/services) request, and return according to storageCache content (GetServices)
-
endpoint: accept kube-proxy endpoint List&Watch(/api/v1/endpoints) request, and return according to storageCache content (GetEndpoints)
Let's focus on analyzing the logic of the cache part, and then go back to analyze the specific http handler List&Watch processing logic
In order to realize topology awareness, wrapper maintains a cache, including node, service, and endpoint. You can see that the processing functions for these three types of resources are registered in setupInformers:
type storageCache struct {
// hostName is the nodeName of node which application-grid-wrapper deploys on
hostName string
wrapperInCluster bool
// mu lock protect the following map structure
mu sync.RWMutex
servicesMap map[types.NamespacedName]*serviceContainer
endpointsMap map[types.NamespacedName]*endpointsContainer
nodesMap map[types.NamespacedName]*nodeContainer
// service watch channel
serviceChan chan<- watch.Event
// endpoints watch channel
endpointsChan chan<- watch.Event
}
...
func NewStorageCache(hostName string, wrapperInCluster bool, serviceNotifier, endpointsNotifier chan watch.Event) *storageCache {
msc := &storageCache{
hostName: hostName,
wrapperInCluster: wrapperInCluster,
servicesMap: make(map[types.NamespacedName]*serviceContainer),
endpointsMap: make(map[types.NamespacedName]*endpointsContainer),
nodesMap: make(map[types.NamespacedName]*nodeContainer),
serviceChan: serviceNotifier,
endpointsChan: endpointsNotifier,
}
return msc
}
...
func (s *interceptorServer) Run(debug bool, bindAddress string, insecure bool, caFile, certFile, keyFile string) error {
...
if err := s.setupInformers(ctx.Done()); err != nil {
return err
}
klog.Infof("Start to run interceptor server")
/* filter
*/
server := &http.Server{Addr: bindAddress, Handler: s.buildFilterChains(debug)}
...
return server.ListenAndServeTLS("", "")
}
func (s *interceptorServer) setupInformers(stop <-chan struct{}) error {
klog.Infof("Start to run service and endpoints informers")
noProxyName, err := labels.NewRequirement(apis.LabelServiceProxyName, selection.DoesNotExist, nil)
if err != nil {
klog.Errorf("can't parse proxy label, %v", err)
return err
}
noHeadlessEndpoints, err := labels.NewRequirement(v1.IsHeadlessService, selection.DoesNotExist, nil)
if err != nil {
klog.Errorf("can't parse headless label, %v", err)
return err
}
labelSelector := labels.NewSelector()
labelSelector = labelSelector.Add(*noProxyName, *noHeadlessEndpoints)
resyncPeriod := time.Minute * 5
client := kubernetes.NewForConfigOrDie(s.restConfig)
nodeInformerFactory := informers.NewSharedInformerFactory(client, resyncPeriod)
informerFactory := informers.NewSharedInformerFactoryWithOptions(client, resyncPeriod,
informers.WithTweakListOptions(func(options *metav1.ListOptions) {
options.LabelSelector = labelSelector.String()
}))
nodeInformer := nodeInformerFactory.Core().V1().Nodes().Informer()
serviceInformer := informerFactory.Core().V1().Services().Informer()
endpointsInformer := informerFactory.Core().V1().Endpoints().Informer()
/*
*/
nodeInformer.AddEventHandlerWithResyncPeriod(s.cache.NodeEventHandler(), resyncPeriod)
serviceInformer.AddEventHandlerWithResyncPeriod(s.cache.ServiceEventHandler(), resyncPeriod)
endpointsInformer.AddEventHandlerWithResyncPeriod(s.cache.EndpointsEventHandler(), resyncPeriod)
go nodeInformer.Run(stop)
go serviceInformer.Run(stop)
go endpointsInformer.Run(stop)
if !cache.WaitForNamedCacheSync("node", stop,
nodeInformer.HasSynced,
serviceInformer.HasSynced,
endpointsInformer.HasSynced) {
return fmt.Errorf("can't sync informers")
}
return nil
}
func (sc *storageCache) NodeEventHandler() cache.ResourceEventHandler {
return &nodeHandler{cache: sc}
}
func (sc *storageCache) ServiceEventHandler() cache.ResourceEventHandler {
return &serviceHandler{cache: sc}
}
func (sc *storageCache) EndpointsEventHandler() cache.ResourceEventHandler {
return &endpointsHandler{cache: sc}
}
Here we analyze NodeEventHandler, ServiceEventHandler and EndpointsEventHandler in turn, as follows:
1 、 NodeEventHandler
NodeEventHandler is responsible for monitoring node resource related events, and adding node and node Labels to storageCache.nodesMap (key is nodeName, value is node and node labels)
func (nh *nodeHandler) add(node *v1.Node) {
sc := nh.cache
sc.mu.Lock()
nodeKey := types.NamespacedName{Namespace: node.Namespace, Name: node.Name}
klog.Infof("Adding node %v", nodeKey)
sc.nodesMap[nodeKey] = &nodeContainer{
node: node,
labels: node.Labels,
}
// update endpoints
changedEps := sc.rebuildEndpointsMap()
sc.mu.Unlock()
for _, eps := range changedEps {
sc.endpointsChan <- eps
}
}
func (nh *nodeHandler) update(node *v1.Node) {
sc := nh.cache
sc.mu.Lock()
nodeKey := types.NamespacedName{Namespace: node.Namespace, Name: node.Name}
klog.Infof("Updating node %v", nodeKey)
nodeContainer, found := sc.nodesMap[nodeKey]
if !found {
sc.mu.Unlock()
klog.Errorf("Updating non-existed node %v", nodeKey)
return
}
nodeContainer.node = node
// return directly when labels of node stay unchanged
if reflect.DeepEqual(node.Labels, nodeContainer.labels) {
sc.mu.Unlock()
return
}
nodeContainer.labels = node.Labels
// update endpoints
changedEps := sc.rebuildEndpointsMap()
sc.mu.Unlock()
for _, eps := range changedEps {
sc.endpointsChan <- eps
}
}
...
At the same time, because the change of node will affect the endpoint, rebuildEndpointsMap will be called to refresh storageCache.endpointsMap
// rebuildEndpointsMap updates all endpoints stored in storageCache.endpointsMap dynamically and constructs relevant modified events
func (sc *storageCache) rebuildEndpointsMap() []watch.Event {
evts := make([]watch.Event, 0)
for name, endpointsContainer := range sc.endpointsMap {
newEps := pruneEndpoints(sc.hostName, sc.nodesMap, sc.servicesMap, endpointsContainer.endpoints, sc.wrapperInCluster)
if apiequality.Semantic.DeepEqual(newEps, endpointsContainer.modified) {
continue
}
sc.endpointsMap[name].modified = newEps
evts = append(evts, watch.Event{
Type: watch.Modified,
Object: newEps,
})
}
return evts
}
rebuildEndpointsMap is the core function of cache, and it is also the realization of topology-aware algorithm:
// pruneEndpoints filters endpoints using serviceTopology rules combined by services topologyKeys and node labels
func pruneEndpoints(hostName string,
nodes map[types.NamespacedName]*nodeContainer,
services map[types.NamespacedName]*serviceContainer,
eps *v1.Endpoints, wrapperInCluster bool) *v1.Endpoints {
epsKey := types.NamespacedName{Namespace: eps.Namespace, Name: eps.Name}
if wrapperInCluster {
eps = genLocalEndpoints(eps)
}
// dangling endpoints
svc, ok := services[epsKey]
if !ok {
klog.V(4).Infof("Dangling endpoints %s, %+#v", eps.Name, eps.Subsets)
return eps
}
// normal service
if len(svc.keys) == 0 {
klog.V(4).Infof("Normal endpoints %s, %+#v", eps.Name, eps.Subsets)
return eps
}
// topology endpoints
newEps := eps.DeepCopy()
for si := range newEps.Subsets {
subnet := &newEps.Subsets[si]
subnet.Addresses = filterConcernedAddresses(svc.keys, hostName, nodes, subnet.Addresses)
subnet.NotReadyAddresses = filterConcernedAddresses(svc.keys, hostName, nodes, subnet.NotReadyAddresses)
}
klog.V(4).Infof("Topology endpoints %s: subnets from %+#v to %+#v", eps.Name, eps.Subsets, newEps.Subsets)
return newEps
}
// filterConcernedAddresses aims to filter out endpoints addresses within the same node unit
func filterConcernedAddresses(topologyKeys []string, hostName string, nodes map[types.NamespacedName]*nodeContainer,
addresses []v1.EndpointAddress) []v1.EndpointAddress {
hostNode, found := nodes[types.NamespacedName{Name: hostName}]
if !found {
return nil
}
filteredEndpointAddresses := make([]v1.EndpointAddress, 0)
for i := range addresses {
addr := addresses[i]
if nodeName := addr.NodeName; nodeName != nil {
epsNode, found := nodes[types.NamespacedName{Name: *nodeName}]
if !found {
continue
}
if hasIntersectionLabel(topologyKeys, hostNode.labels, epsNode.labels) {
filteredEndpointAddresses = append(filteredEndpointAddresses, addr)
}
}
}
return filteredEndpointAddresses
}
func hasIntersectionLabel(keys []string, n1, n2 map[string]string) bool {
if n1 == nil || n2 == nil {
return false
}
for _, key := range keys {
val1, v1found := n1[key]
val2, v2found := n2[key]
if v1found && v2found && val1 == val2 {
return true
}
}
return false
}
The algorithm logic is as follows:
- Determine whether the endpoint is the default kubernetes service, if so, convert the endpoint to the lite-apiserver address (127.0.0.1) and port (51003) of the edge node where the wrapper is located
apiVersion: v1
kind: Endpoints
metadata:
annotations:
superedge.io/local-endpoint: 127.0.0.1
superedge.io/local-port: "51003"
name: kubernetes
namespace: default
subsets:
- addresses:
- ip: 172.31.0.60
ports:
- name: https
port: xxx
protocol: TCP
func genLocalEndpoints(eps *v1.Endpoints) *v1.Endpoints {
if eps.Namespace != metav1.NamespaceDefault || eps.Name != MasterEndpointName {
return eps
}
klog.V(4).Infof("begin to gen local ep %v", eps)
ipAddress, e := eps.Annotations[EdgeLocalEndpoint]
if !e {
return eps
}
portStr, e := eps.Annotations[EdgeLocalPort]
if !e {
return eps
}
klog.V(4).Infof("get local endpoint %s:%s", ipAddress, portStr)
port, err := strconv.ParseInt(portStr, 10, 32)
if err != nil {
klog.Errorf("parse int %s err %v", portStr, err)
return eps
}
ip := net.ParseIP(ipAddress)
if ip == nil {
klog.Warningf("parse ip %s nil", ipAddress)
return eps
}
nep := eps.DeepCopy()
nep.Subsets = []v1.EndpointSubset{
{
Addresses: []v1.EndpointAddress{
{
IP: ipAddress,
},
},
Ports: []v1.EndpointPort{
{
Protocol: v1.ProtocolTCP,
Port: int32(port),
Name: "https",
},
},
},
}
klog.V(4).Infof("gen new endpoint complete %v", nep)
return nep
}
The purpose of this is to make the apiserver accessed by the service on the edge node in the cluster (InCluster) mode as the local lite-apiserver instead of the cloud apiserver
- Retrieve the corresponding service from the storageCache.servicesMap cache according to the endpoint name (namespace/name). If the service does not have topologyKeys, no topology conversion (non-service group) is required.
func getTopologyKeys(objectMeta *metav1.ObjectMeta) []string {
if !hasTopologyKey(objectMeta) {
return nil
}
var keys []string
keyData := objectMeta.Annotations[TopologyAnnotationsKey]
if err := json.Unmarshal([]byte(keyData), &keys); err != nil {
klog.Errorf("can't parse topology keys %s, %v", keyData, err)
return nil
}
return keys
}
- Call filterConcernedAddresses to filter endpoint.Subsets Addresses and NotReadyAddresses, and only retain the endpoints in the same service topologyKeys
// filterConcernedAddresses aims to filter out endpoints addresses within the same node unit
func filterConcernedAddresses(topologyKeys []string, hostName string, nodes map[types.NamespacedName]*nodeContainer,
addresses []v1.EndpointAddress) []v1.EndpointAddress {
hostNode, found := nodes[types.NamespacedName{Name: hostName}]
if !found {
return nil
}
filteredEndpointAddresses := make([]v1.EndpointAddress, 0)
for i := range addresses {
addr := addresses[i]
if nodeName := addr.NodeName; nodeName != nil {
epsNode, found := nodes[types.NamespacedName{Name: *nodeName}]
if !found {
continue
}
if hasIntersectionLabel(topologyKeys, hostNode.labels, epsNode.labels) {
filteredEndpointAddresses = append(filteredEndpointAddresses, addr)
}
}
}
return filteredEndpointAddresses
}
func hasIntersectionLabel(keys []string, n1, n2 map[string]string) bool {
if n1 == nil || n2 == nil {
return false
}
for _, key := range keys {
val1, v1found := n1[key]
val2, v2found := n2[key]
if v1found && v2found && val1 == val2 {
return true
}
}
return false
}
Note: If the edge node where the wrapper is located does not have the service topologyKeys label, the service cannot be accessed either
Back to rebuildEndpointsMap, after calling pruneEndpoints to refresh the endpoints in the same topology domain, the modified endpoints will be assigned to storageCache.endpointsMap [endpoint]. modified (this field records the endpoints modified after topology awareness).
func (nh *nodeHandler) add(node *v1.Node) {
sc := nh.cache
sc.mu.Lock()
nodeKey := types.NamespacedName{Namespace: node.Namespace, Name: node.Name}
klog.Infof("Adding node %v", nodeKey)
sc.nodesMap[nodeKey] = &nodeContainer{
node: node,
labels: node.Labels,
}
// update endpoints
changedEps := sc.rebuildEndpointsMap()
sc.mu.Unlock()
for _, eps := range changedEps {
sc.endpointsChan <- eps
}
}
// rebuildEndpointsMap updates all endpoints stored in storageCache.endpointsMap dynamically and constructs relevant modified events
func (sc *storageCache) rebuildEndpointsMap() []watch.Event {
evts := make([]watch.Event, 0)
for name, endpointsContainer := range sc.endpointsMap {
newEps := pruneEndpoints(sc.hostName, sc.nodesMap, sc.servicesMap, endpointsContainer.endpoints, sc.wrapperInCluster)
if apiequality.Semantic.DeepEqual(newEps, endpointsContainer.modified) {
continue
}
sc.endpointsMap[name].modified = newEps
evts = append(evts, watch.Event{
Type: watch.Modified,
Object: newEps,
})
}
return evts
}
In addition, if endpoints (endpoints modified after topology awareness) change, a watch event will be constructed and passed to endpoints handler (interceptEndpointsRequest) for processing
2、ServiceEventHandler
The key of the storageCache.servicesMap structure is the service name (namespace/name), and the value is serviceContainer, which contains the following data:
- svc: service object
- keys:service topologyKeys
For changes to service resources, use Update event to illustrate:
func (sh *serviceHandler) update(service *v1.Service) {
sc := sh.cache
sc.mu.Lock()
serviceKey := types.NamespacedName{Namespace: service.Namespace, Name: service.Name}
klog.Infof("Updating service %v", serviceKey)
newTopologyKeys := getTopologyKeys(&service.ObjectMeta)
serviceContainer, found := sc.servicesMap[serviceKey]
if !found {
sc.mu.Unlock()
klog.Errorf("update non-existed service, %v", serviceKey)
return
}
sc.serviceChan <- watch.Event{
Type: watch.Modified,
Object: service,
}
serviceContainer.svc = service
// return directly when topologyKeys of service stay unchanged
if reflect.DeepEqual(serviceContainer.keys, newTopologyKeys) {
sc.mu.Unlock()
return
}
serviceContainer.keys = newTopologyKeys
// update endpoints
changedEps := sc.rebuildEndpointsMap()
sc.mu.Unlock()
for _, eps := range changedEps {
sc.endpointsChan <- eps
}
}
The logic is as follows:
- Get service topologyKeys
- Build service event.Modified event
- Compare the service topologyKeys with the existing ones for any difference
- If there is a difference, update the topologyKeys, and call rebuildEndpointsMap to refresh the endpoints corresponding to the service. If the endpoints change, construct the endpoints watch event and pass it to the endpoints handler (interceptEndpointsRequest) for processing
3、EndpointsEventHandler
The key of storageCache.endpointsMap structure is the name of endpoints (namespace/name), and the value is endpointsContainer, which contains the following data:
- endpoints: endpoints before topology modification
- modified: Endpoints after topology modification
Regarding changes to endpoints resources, use Update event to illustrate:
func (eh *endpointsHandler) update(endpoints *v1.Endpoints) {
sc := eh.cache
sc.mu.Lock()
endpointsKey := types.NamespacedName{Namespace: endpoints.Namespace, Name: endpoints.Name}
klog.Infof("Updating endpoints %v", endpointsKey)
endpointsContainer, found := sc.endpointsMap[endpointsKey]
if !found {
sc.mu.Unlock()
klog.Errorf("Updating non-existed endpoints %v", endpointsKey)
return
}
endpointsContainer.endpoints = endpoints
newEps := pruneEndpoints(sc.hostName, sc.nodesMap, sc.servicesMap, endpoints, sc.wrapperInCluster)
changed := !apiequality.Semantic.DeepEqual(endpointsContainer.modified, newEps)
if changed {
endpointsContainer.modified = newEps
}
sc.mu.Unlock()
if changed {
sc.endpointsChan <- watch.Event{
Type: watch.Modified,
Object: newEps,
}
}
}
The logic is as follows:
- Update endpointsContainer.endpoint to the new endpoints object
- Call pruneEndpoints to get the endpoints after topology refresh
- Compare endpointsContainer.modified with the newly refreshed endpoints
- If there are differences, update endpointsContainer.modified, construct endpoints watch event, and pass it to endpoints handler (interceptEndpointsRequest) for processing
After analyzing NodeEventHandler, ServiceEventHandler and EndpointsEventHandler, we return to the specific http handler List&Watch processing logic, here is an example of endpoints:
func (s *interceptorServer) interceptEndpointsRequest(handler http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodGet || !strings.HasPrefix(r.URL.Path, "/api/v1/endpoints") {
handler.ServeHTTP(w, r)
return
}
queries := r.URL.Query()
acceptType := r.Header.Get("Accept")
info, found := s.parseAccept(acceptType, s.mediaSerializer)
if !found {
klog.Errorf("can't find %s serializer", acceptType)
w.WriteHeader(http.StatusBadRequest)
return
}
encoder := scheme.Codecs.EncoderForVersion(info.Serializer, v1.SchemeGroupVersion)
// list request
if queries.Get("watch") == "" {
w.Header().Set("Content-Type", info.MediaType)
allEndpoints := s.cache.GetEndpoints()
epsItems := make([]v1.Endpoints, 0, len(allEndpoints))
for _, eps := range allEndpoints {
epsItems = append(epsItems, *eps)
}
epsList := &v1.EndpointsList{
Items: epsItems,
}
err := encoder.Encode(epsList, w)
if err != nil {
klog.Errorf("can't marshal endpoints list, %v", err)
w.WriteHeader(http.StatusInternalServerError)
return
}
return
}
// watch request
timeoutSecondsStr := r.URL.Query().Get("timeoutSeconds")
timeout := time.Minute
if timeoutSecondsStr != "" {
timeout, _ = time.ParseDuration(fmt.Sprintf("%ss", timeoutSecondsStr))
}
timer := time.NewTimer(timeout)
defer timer.Stop()
flusher, ok := w.(http.Flusher)
if !ok {
klog.Errorf("unable to start watch - can't get http.Flusher: %#v", w)
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
e := restclientwatch.NewEncoder(
streaming.NewEncoder(info.StreamSerializer.Framer.NewFrameWriter(w),
scheme.Codecs.EncoderForVersion(info.StreamSerializer, v1.SchemeGroupVersion)),
encoder)
if info.MediaType == runtime.ContentTypeProtobuf {
w.Header().Set("Content-Type", runtime.ContentTypeProtobuf+";stream=watch")
} else {
w.Header().Set("Content-Type", runtime.ContentTypeJSON)
}
w.Header().Set("Transfer-Encoding", "chunked")
w.WriteHeader(http.StatusOK)
flusher.Flush()
for {
select {
case <-r.Context().Done():
return
case <-timer.C:
return
case evt := <-s.endpointsWatchCh:
klog.V(4).Infof("Send endpoint watch event: %+#v", evt)
err := e.Encode(&evt)
if err != nil {
klog.Errorf("can't encode watch event, %v", err)
return
}
if len(s.endpointsWatchCh) == 0 {
flusher.Flush()
}
}
}
})
}
The logic is as follows:
- If it is a List request, call GetEndpoints to obtain a list of endpoints after topology modification, and return
func (sc *storageCache) GetEndpoints() []*v1.Endpoints {
sc.mu.RLock()
defer sc.mu.RUnlock()
epList := make([]*v1.Endpoints, 0, len(sc.endpointsMap))
for _, v := range sc.endpointsMap {
epList = append(epList, v.modified)
}
return epList
}
- If it is a Watch request, it will continue to receive watch events from the storageCache.endpointsWatchCh pipeline and return
The interceptServiceRequest logic is consistent with interceptEndpointsRequest, so I won’t repeat it here.
to sum up
- SuperEdge service group uses application-grid-wrapper to realize topology awareness and completes closed-loop access to services in the same nodeunit
- Comparing the topology awareness implemented by the service group and the native implementation in the Kubernetes community, there are the following differences:
- The service group topology key can be customized, that is, gridUniqKey, which is more flexible to use. There are currently only three options for community implementation: "kubernetes.io/hostname", "topology.kubernetes.io/zone" and "topology.kubernetes. io/region"
- The service group can only fill in one topology key, that is, it can only access the valid endpoints in this topology domain, and cannot access the endpoints of other topology domains; and the community can access other alternative topology domain endpoints through the topologyKey list and "*"
- The ServiceGrid Controller is responsible for generating the corresponding service (including the topologyKeys annotations composed of serviceGrid.Spec.GridUniqKey) according to the ServiceGrid, and the logic is the same as that of the DeploymentGrid Controller as a whole, as follows:
- Create and maintain several CRDs required by service group (including: ServiceGrid)
- Monitor the ServiceGrid event, and fill the ServiceGrid into the work queue; cyclically remove the ServiceGrid from the queue for analysis, create and maintain the corresponding service
- Monitor the service event, and stuff the related ServiceGrid into the work queue for the above processing to assist the above logic to achieve the overall reconcile logic
- In order to achieve zero intrusion of Kubernetes, it is necessary to add a layer of wrapper between the communication between kube-proxy and apiserver, and the call link is as follows:
kube-proxy -> application-grid-wrapper -> lite-apiserver -> kube-apiserver - application-grid-wrapper is an http server that accepts requests from kube-proxy and maintains a resource cache at the same time. The processing functions are as follows from the outside to the inside:
- debug: accept debug request and return the running information of wrapper pprof
- logger: print request log
- node: accept kube-proxy node GET (/api/v1/nodes/{node}) request and return node information
- event: accept kube-proxy events POST (/events) request and forward the request to lite-apiserver
- service: accept kube-proxy service List&Watch (/api/v1/services) request, and return (GetServices) according to storageCache content.
- endpoint: accept kube-proxy endpoint List&Watch(/api/v1/endpoints) request, and return (GetEndpoints) according to storageCache content.
- In order to realize topology awareness, the wrapper maintains a resource cache, including node, service, and endpoint, and registers related event processing functions. The core topology algorithm logic is: call filterConcernedAddresses to filter endpoint.Subsets Addresses and NotReadyAddresses, and only retain the endpoints in the same service topologyKeys. In addition, if the edge node where the wrapper is located does not have a service topologyKeys label, the service cannot be accessed either.
- The wrapper accepts List&Watch requests from kube-proxy for endpoints and services. Take endpoints as an example: if it is a List request, call GetEndpoints to obtain a list of endpoints after topology modification, and return; if it is a Watch request, it will continue to pipe from storageCache.endpointsWatchCh Accept the watch event and return. The service logic is consistent with endpoints.
Outlook
At present, the topology algorithm functions implemented by the SuperEdge service group are more flexible and convenient. How to deal with the relationship with the Kubernetes community service topology awareness is worth exploring. It is recommended to push the SuperEdge topology algorithm to the community
Refs
- duyanghao kubernetes-reading-notes