When creating a data table in mysql, attributes are set for each field, and there are corresponding operations in ES—mapping; mapping defines how a document is processed, how these attribute fields are stored or retrieved, these They are all operated by mapping.
ES contains many mapping rules. For details, please refer to the official documents. In the first storage, ES will guess the mapping rules of the fields, of course, you can also modify the mapping rules of the fields yourself; for example: to query the default mapping rules, you can see In general, the number is defaulted to the long type, the string is defaulted to the text type, and there is a keyword attribute under the text type for exact matching.
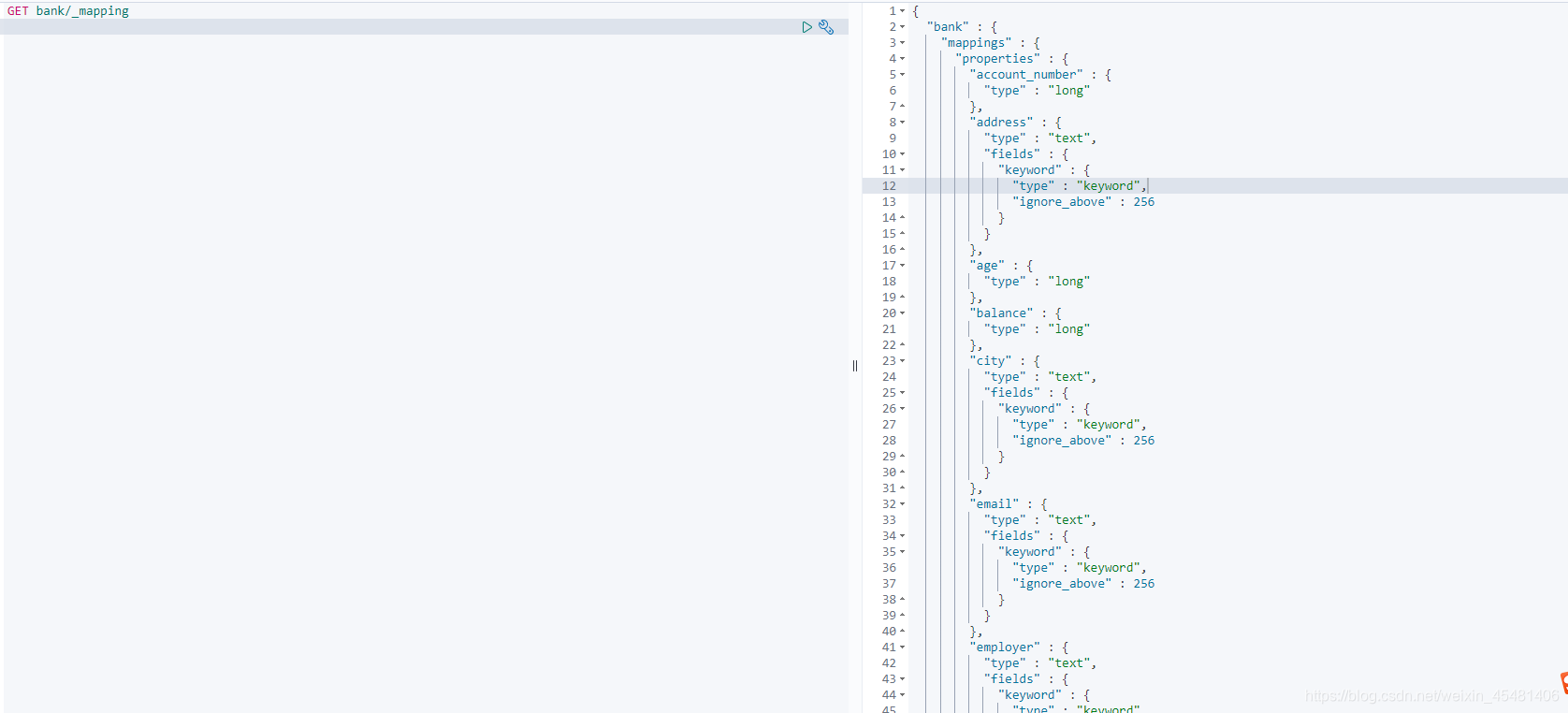
Of course, in actual applications, there must be other mapping rules. We It can be changed after storage, or it can be set in advance before storage
Create mapping

Add new field mapping

Update mapping
If the field of an attribute in ES already exists, the mapping cannot be updated. If the existing mapping is modified, then our previous search rules will become invalid, so the official does not allow to modify the mapping. If the mapping must be modified, it can be achieved through data migration. , Re-create a new mapping rule, and then migrate the data
data migration

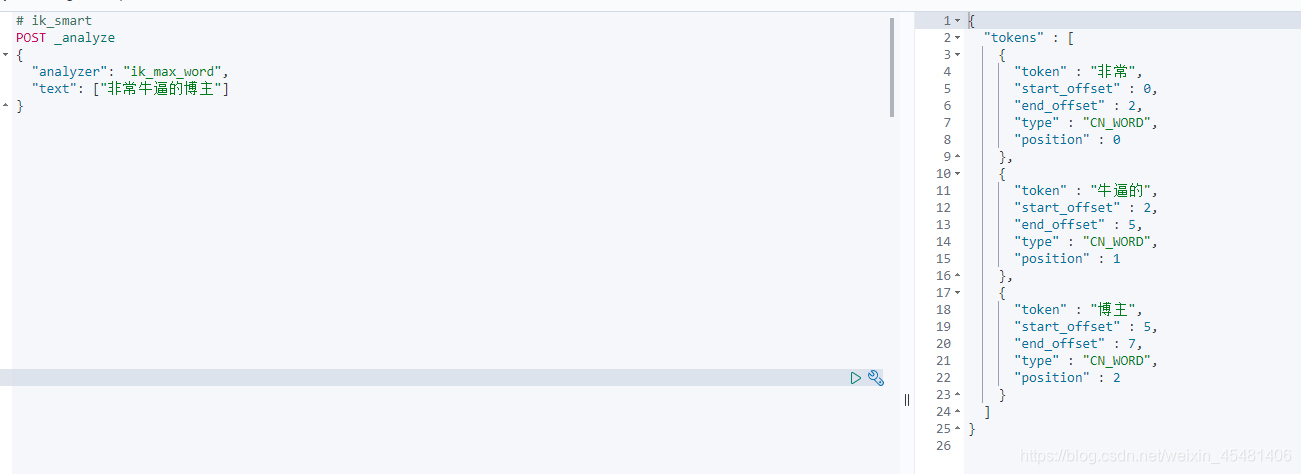
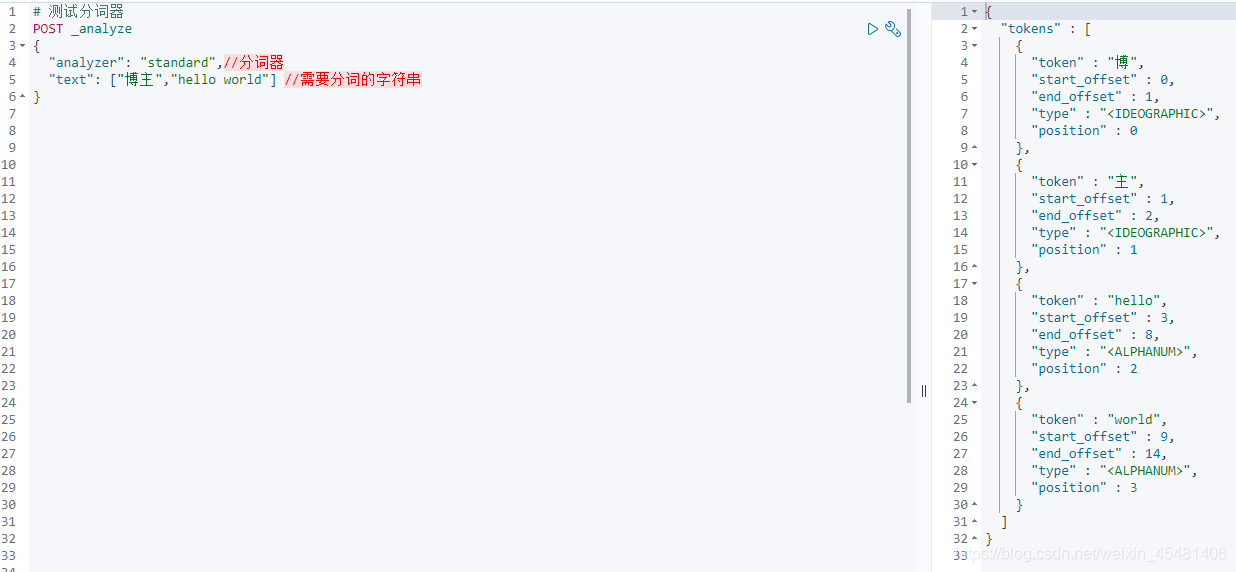
ES has a core of full-text search-word segmentation, which divides a string of characters into words one by one, and then uses the correlation of the words to match, and finally completes the full-text search function; the word segmentation uses a tokenizer in ES to receive a character Stream, divide it into independent tokens (word elements), and then perform matching; there are many ES tokenizers, the default is "standard", you can test it, you can see that Chinese is a word by word split , While English is split according to spaces, ES word segmenters are all to support English, while Chinese need to install its own word segmentation additionally, otherwise it will be split one by one like the figure below
IK tokenizer
IK tokenizer is a recommended open source tokenizer. The installation is relatively simple. Download the same version of ES that you installed, and then put it in the plugins directory of ES to unzip it. Because of the plugins directory mapped when the container is created, you can Operate directly in the host
# 下载IK分词器
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.1/elasticsearch-analysis-ik-7.10.1.zip
# 解压文件
unzip elasticsearch-analysis-ik-7.10.1.zip
# 进入容器内部查询安装的插件
elasticsearch-plugin list
# 最后记得重启容器
If you can find it, it means that the IK tokenizer is installed. Next, test it. Ik has two commonly used tokenizers, "ik_smart" and "ik_max_word".
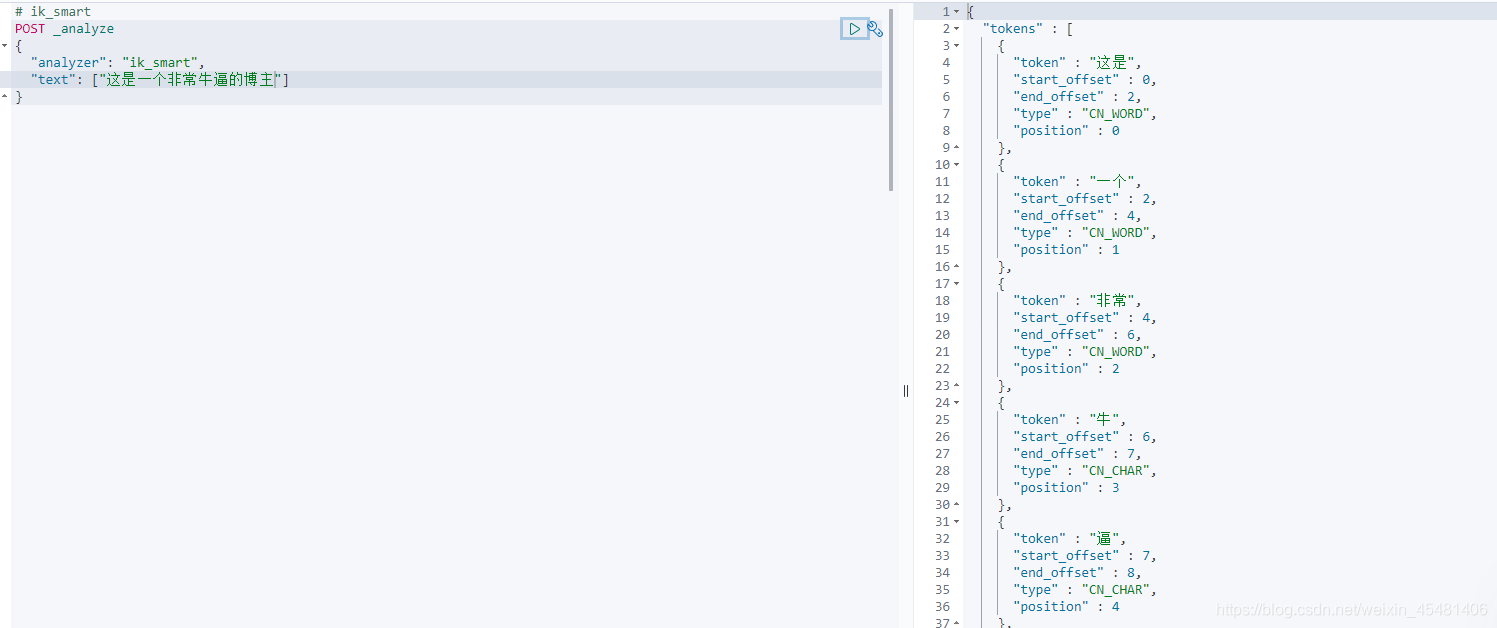
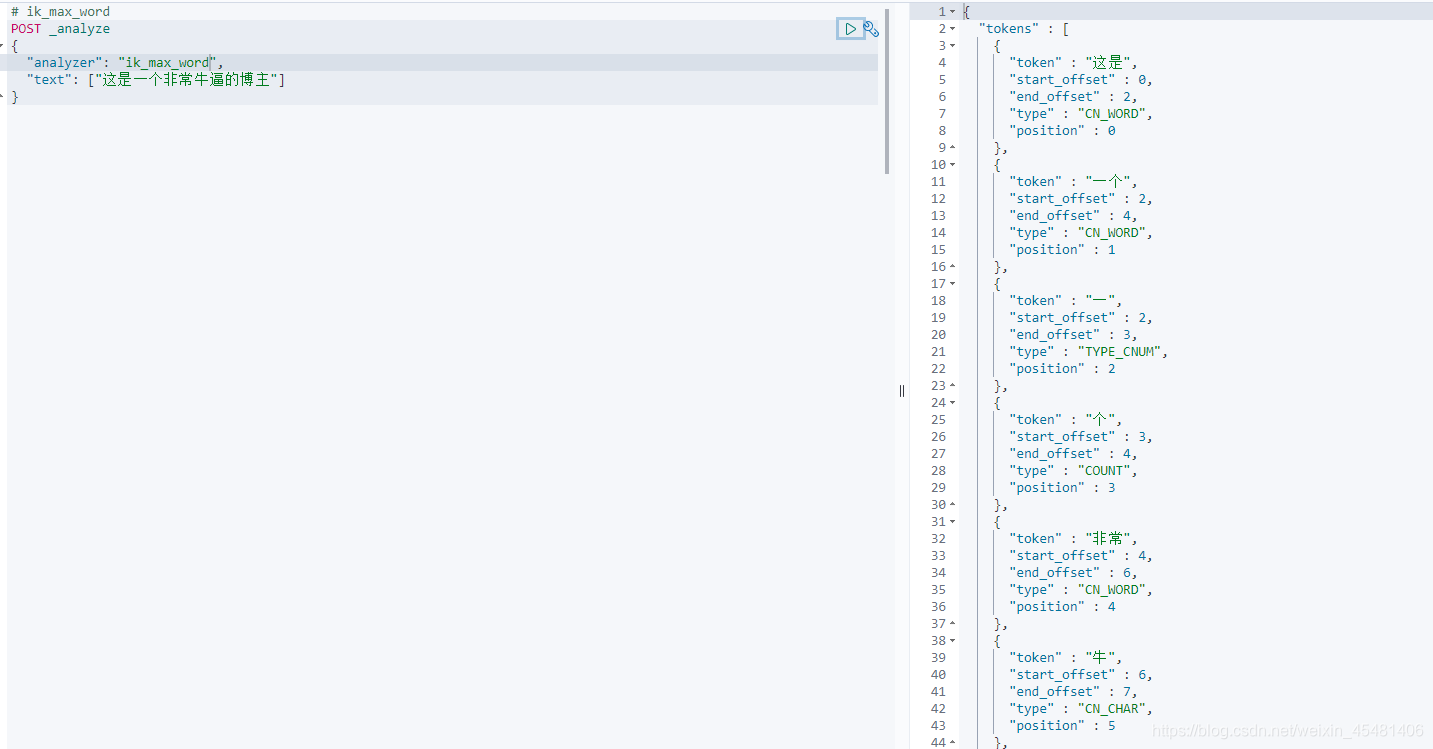
However, the IK tokenizer still fails to meet our expectations. "Forced" is taken apart, so we can expand the vocabulary
Custom thesaurus
To add a custom lexicon, you first need to put the lexicon file, which can be a txt text, on the network, and then configure the ik tokenizer. You can use nginx or other web servers. It is recommended to use nginx. Separate the nginx article,
let’s not talk about the nginx configuration here. For example, I have configured nginx and can access my thesaurus files through the network, and then modify IKAnalyzer.cfg.xml in the config directory of the ik tokenizer, This file is the configuration of ik; you can also add word segmentation through a dic file, add a file with the suffix .dic in the config directory of ik, and configure it in the configuration file of ik
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">fenci.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.0.109/images/fenci.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
After the configuration is complete, restart ES, and test our thesaurus after ES starts. Both methods are ok. I suggest using the second one, which is simpler.