Continue from section 20
4. Word segmentation
A tokenizer(tokenizer) receiving one 字符流, it will be divided into separate tokens(LUs usually independent words), then the output tokensstream.
For example, whitespace tokenizersplits text when it encounters a blank character. It will text " Quick Brown Fox! " Is divided into [ Quick, brown, fox!L.
The tokenizer(tokenizer) is also responsible for recording various term(entry) of the order or positionposition (for phrasephrases and word proximitywords neighbor queries), and termthe original (entry) represented by the word(word) of start(start) and end(end) of character offsets( Character offset) (used to highlight the search content).
Elasticsearch A lot of built-in tokenizers are provided, which can be used to build custom analyzers (custom tokenizers).
Test ES default standard tokenizer
英文::
POST _analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
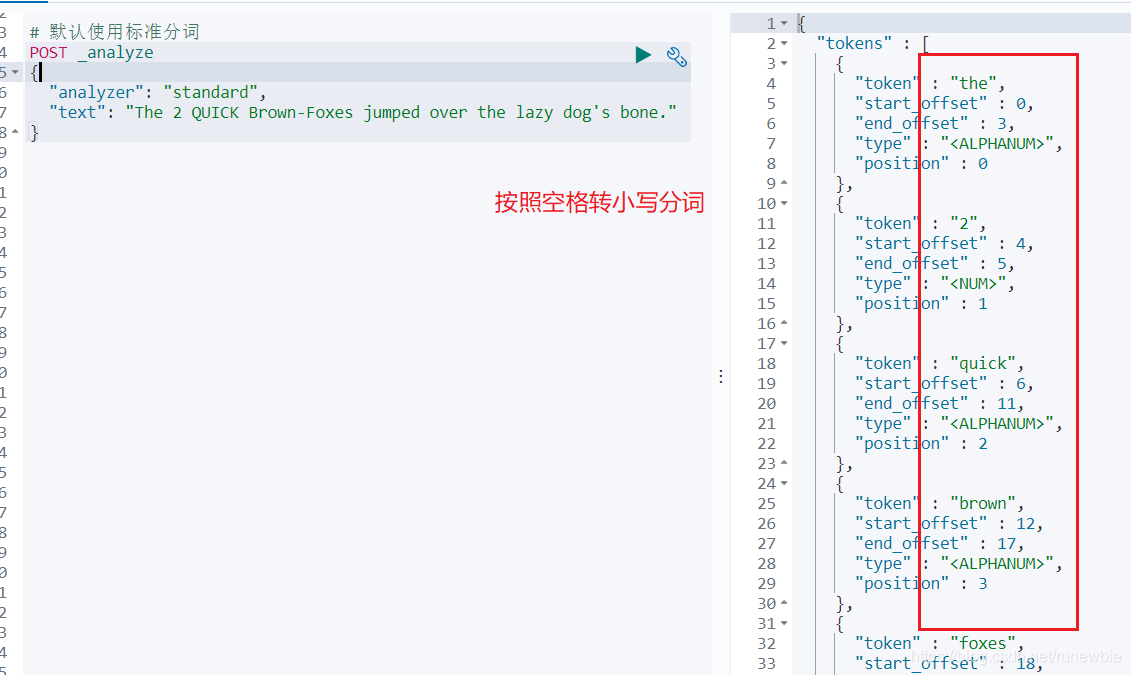
中文:
POST _analyze
{
"analyzer": "standard",
"text": "pafcmall电商项目"
}
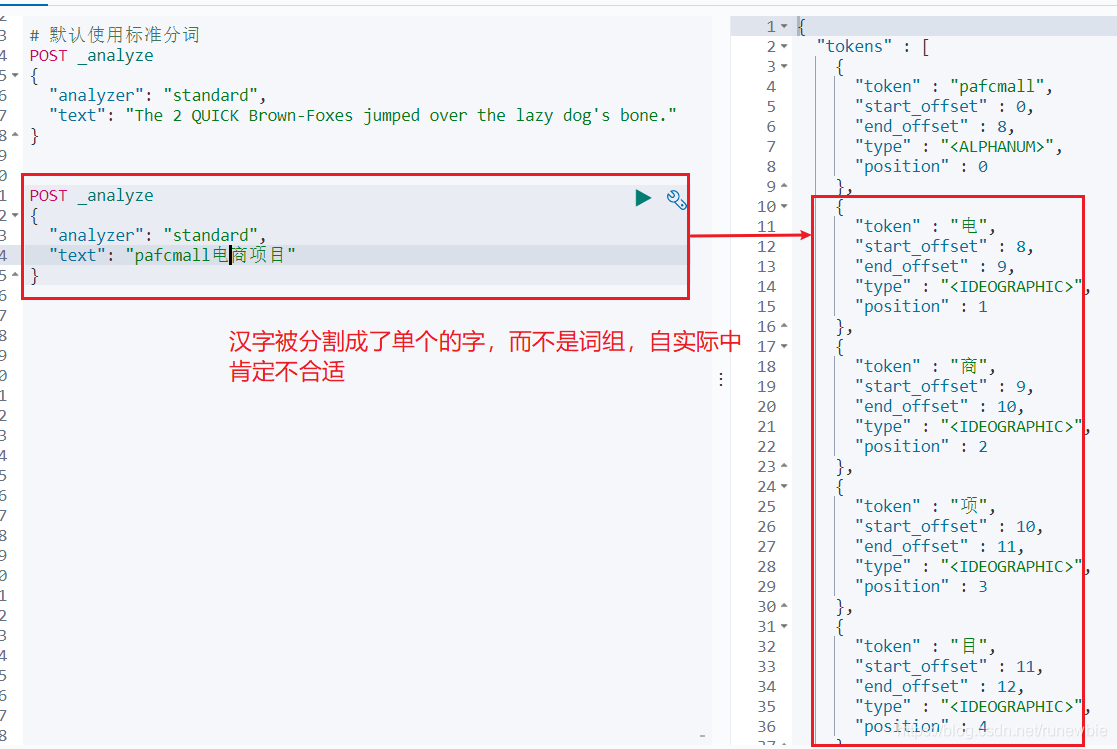
1), install the ik tokenizer
注意: Cannot use the default elasticsearch-plugin install xxx.zip for automatic installation
Go to https://github.com/medcl/elasticsearch-analysis-ik/releases to
find the corresponding es version installation
1、进入 es 容器内部 plugins 目录
docker exec -it 容器id /bin/bash
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
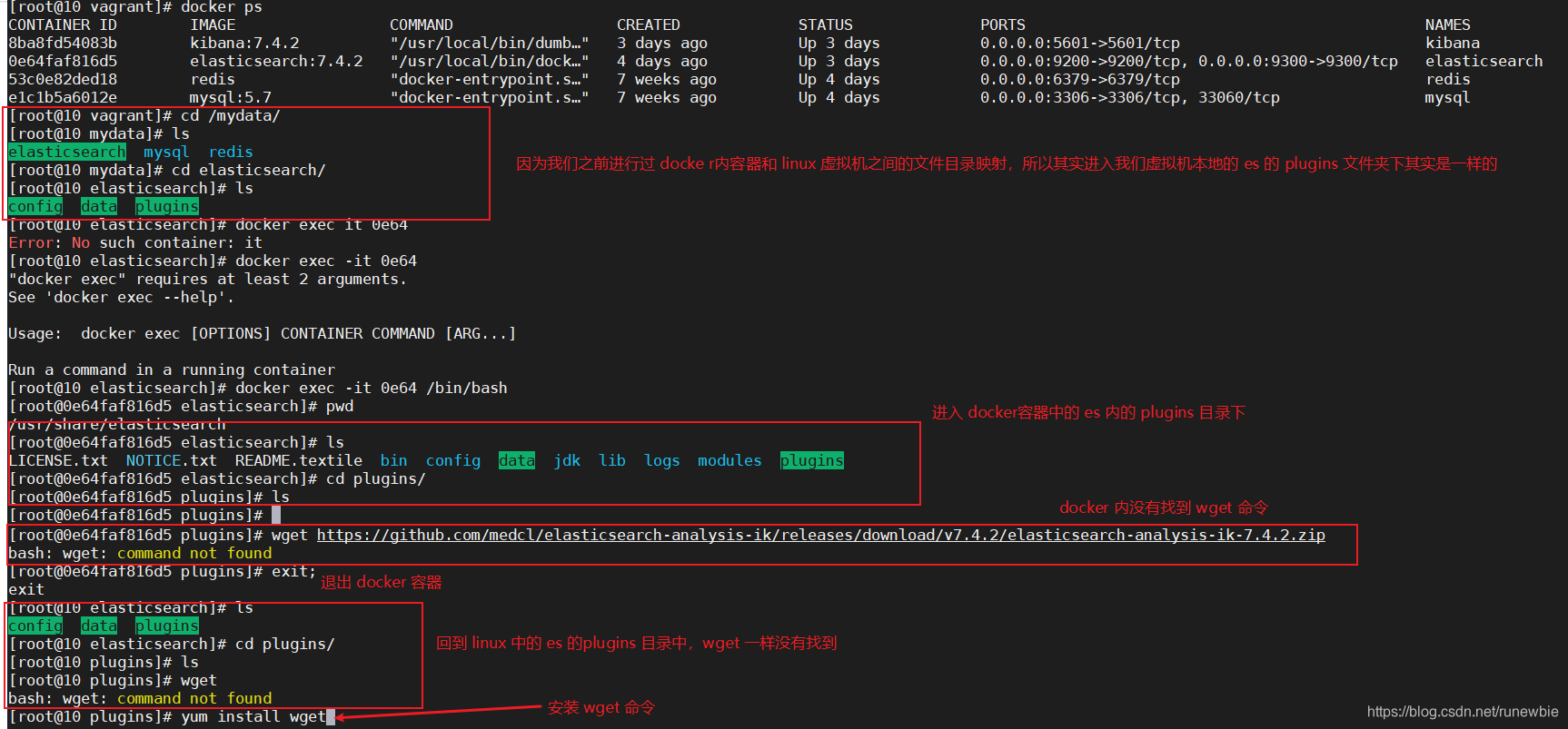
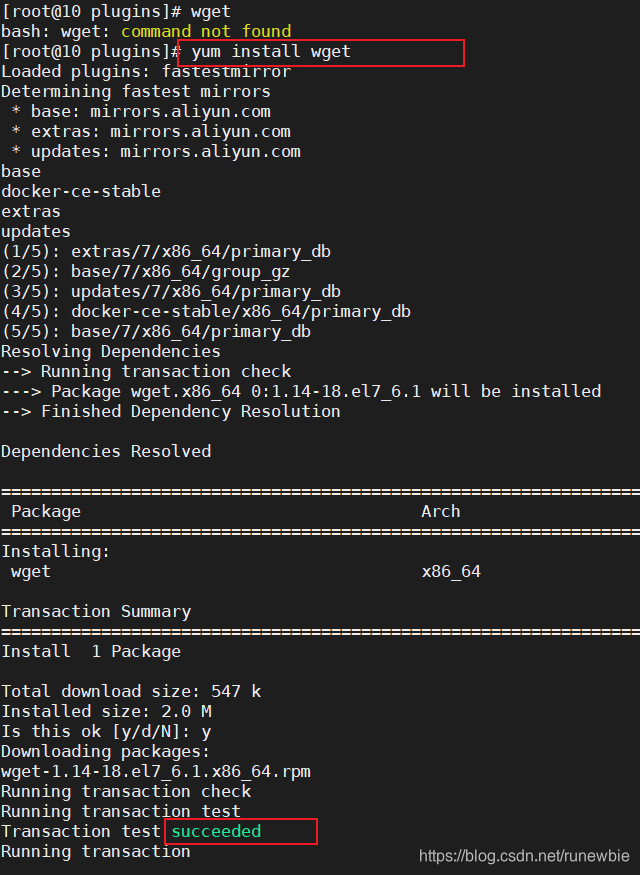
2. Installation wget:
yum install wget
3, download and ES matching versions of ikWord Breaker:
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
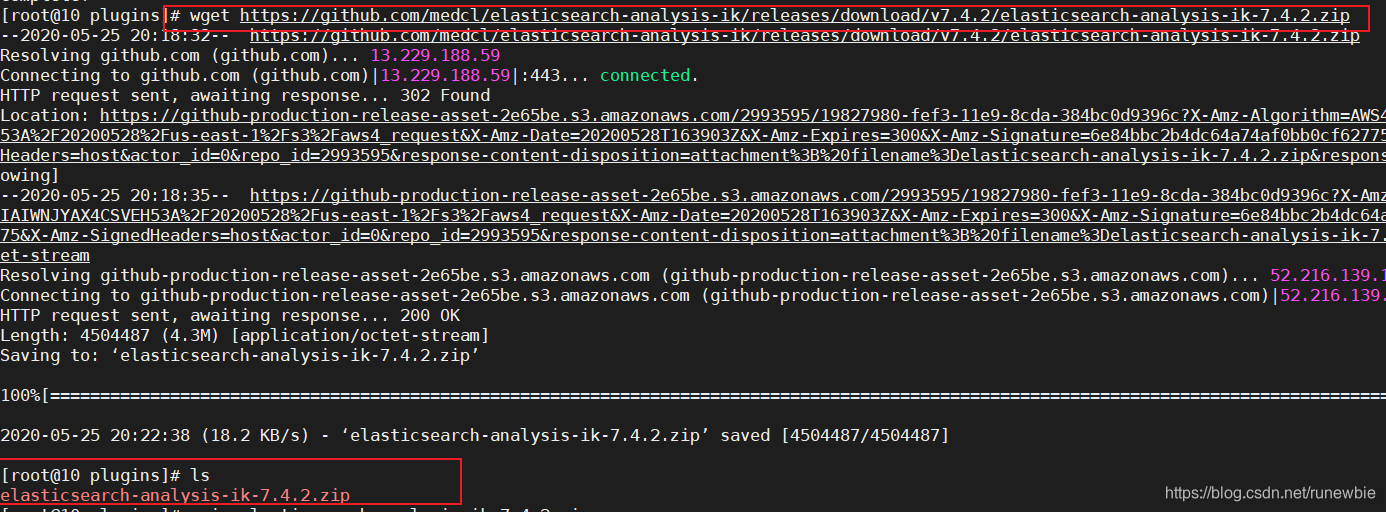
4, unzipdownload the file and extract
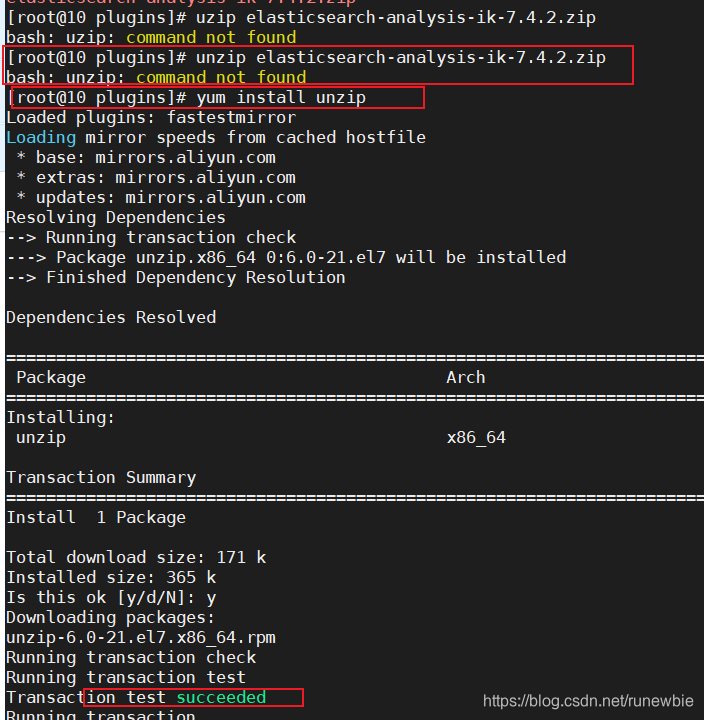
1), using the unzipdecompression elasticsearch-analysis-ik-7.4.2.zipdiscovery unzipcommand has not been installed, install unzip
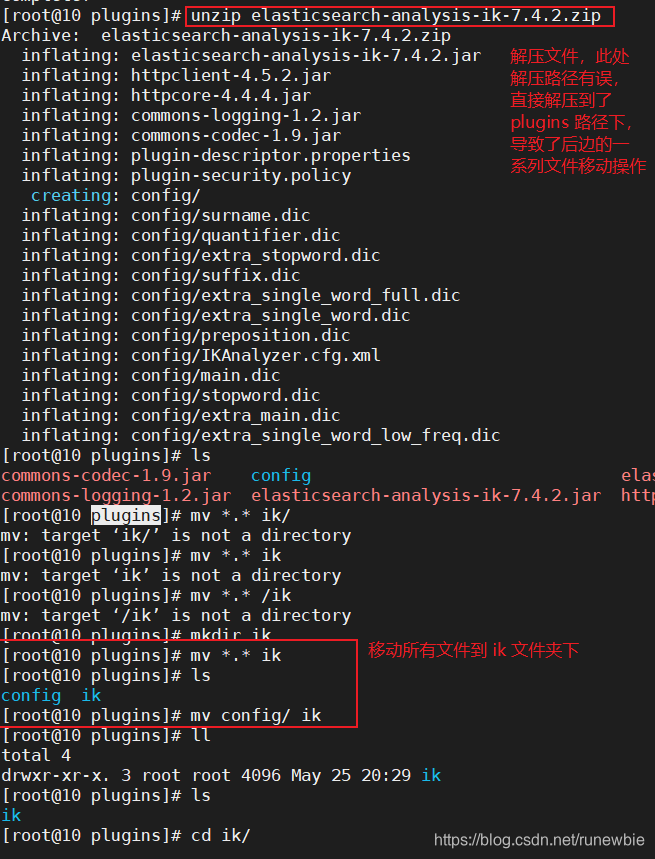
2), extract the files to a pluginsdirectory ikdirectory
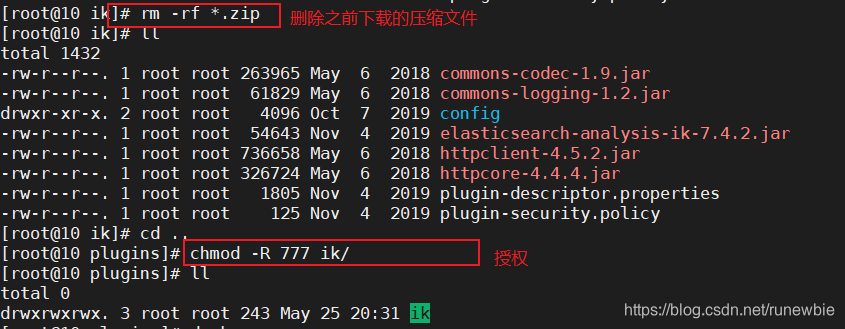
3) delete the archive, and to ikauthorize directory and its files
rm -rf *.zip
chmod -R 777 ik/
5. You can confirm whether the tokenizer is installed
cd../bin
elasticsearch plugin list:即可列出系统的分词器
1), enter the es container in docker
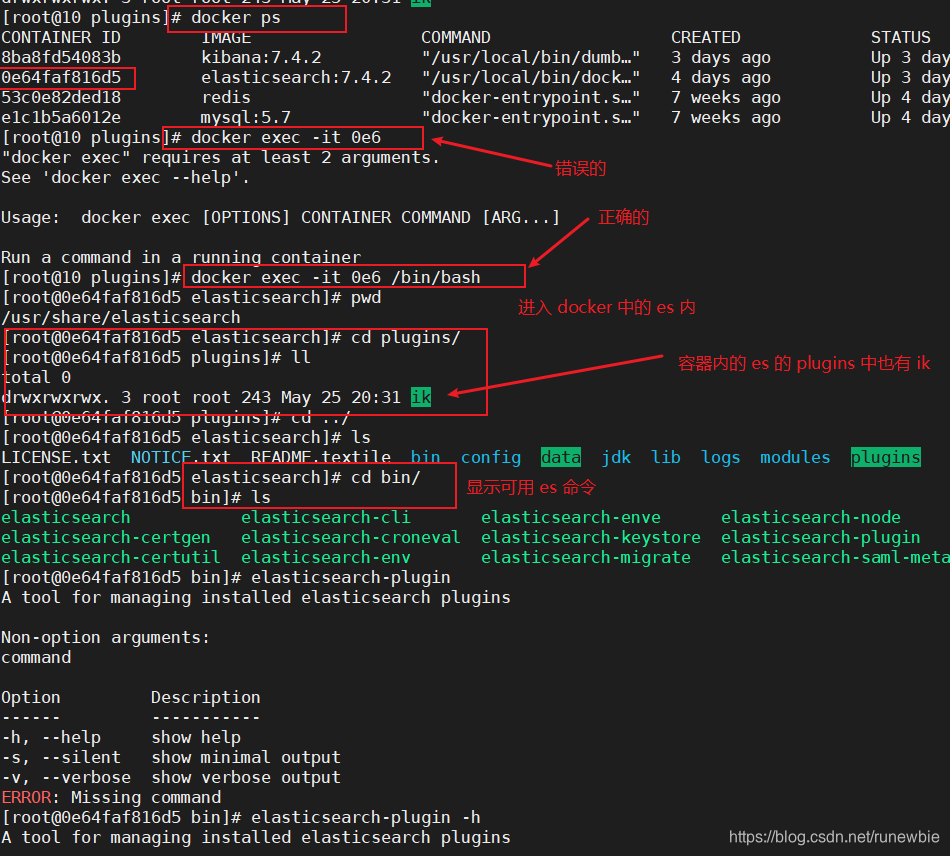
2), list the tokenizer of the system

6. Restart ES to make the ik tokenizer take effect
docker restart elasticsearch
2), test the tokenizer
使用默认分词:
POST _analyze
{
"analyzer": "standard",
"text": "pafcmall电商项目"
}
result:
![[External link image transfer failed. The source site may have an anti-leech link mechanism. It is recommended to save the image and upload it directly (img-l0aY1xXN-1590760088470)(imgs/20-2.png)]](https://img-blog.csdnimg.cn/20200529215201470.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3J1bmV3Ymll,size_16,color_FFFFFF,t_70)
ik智能分词:
POST _analyze
{
"analyzer": "ik_smart",
"text": "pafcmall电商项目"
}
result:
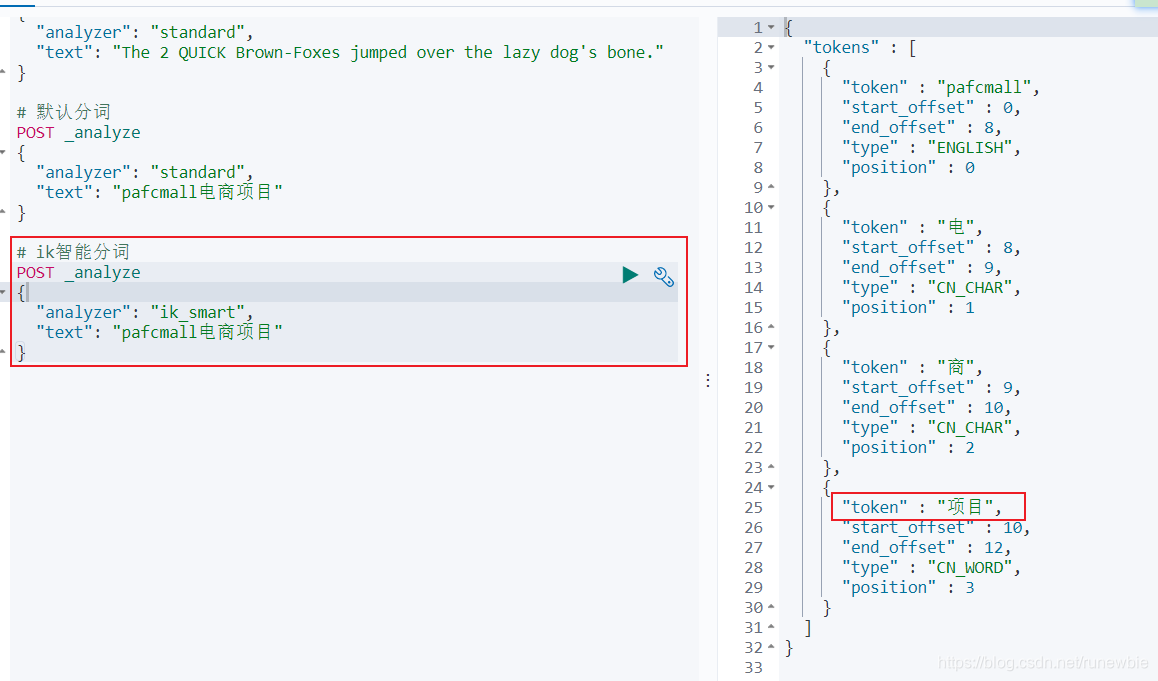
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
result:
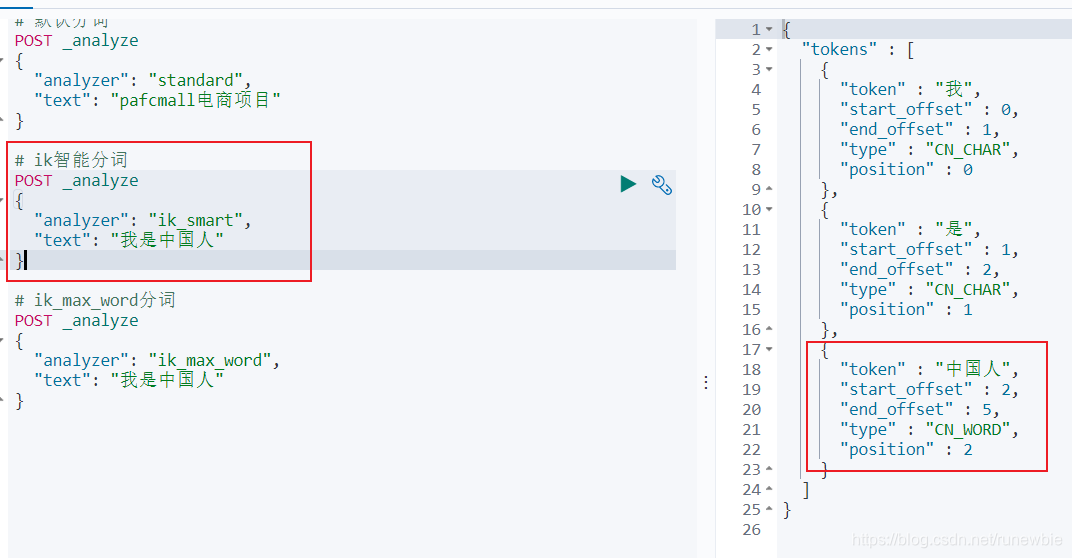
ik_max_word分词:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
Result: It can
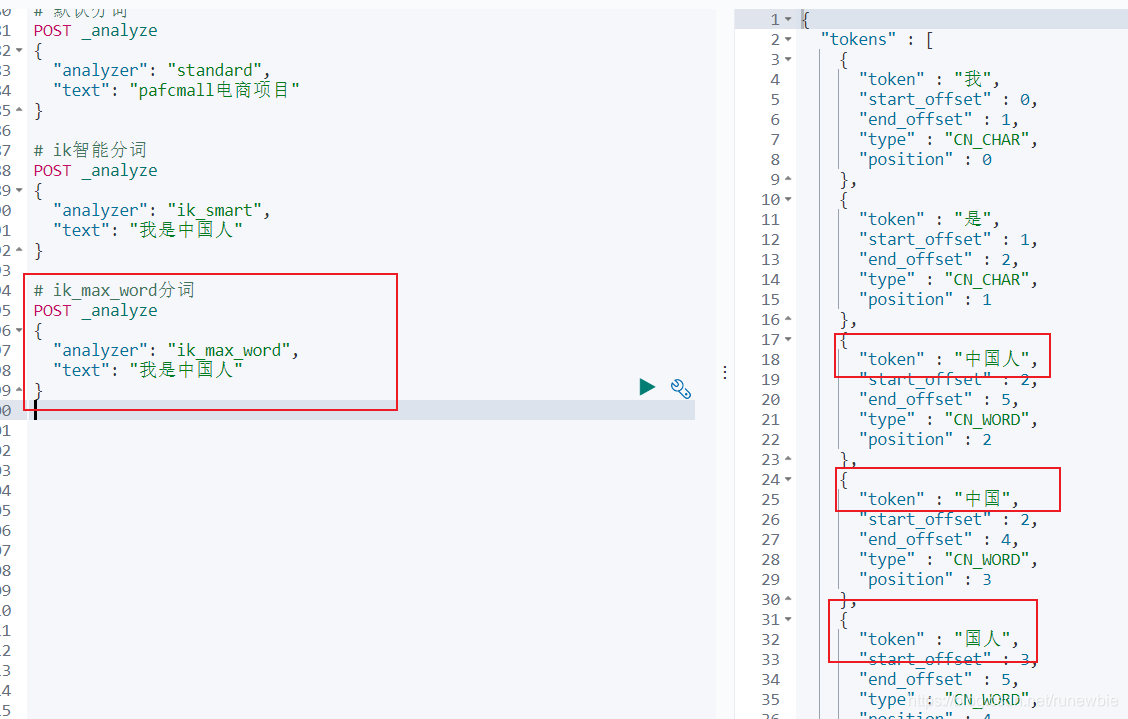
be seen that different tokenizers have obvious differences in word segmentation. Therefore, in the future, you can no longer use the default mapping to define an index. The mapping must be created manually because the tokenizer must be selected.
reference:
Getting started with the full-text search engine Elasticsearch