
In the daily development of the Internet back-end interface, whether you are using C, Java, PHP or Golang, you cannot avoid the need to call mysql, redis and other components to obtain data. You may also need to perform some rpc remote calls or call Some other restful apis. At the bottom of these calls, the TCP protocol is basically used for transmission. This is because in the transport layer protocol, the TCP protocol has the advantages of reliable connection, error retransmission, and congestion control, so it is currently more widely used than UDP.
I believe you must have heard that TCP also has some shortcomings, that is, the old-fashioned overhead is slightly larger. However, in various technical blogs, it is said that the cost is large or small, and it is rare that no specific quantitative analysis is given. You're welcome, this is all nonsense with little nutrition. After thinking about my daily work, what I want to understand more is how much overhead is. How long does it take to delay the establishment of a TCP connection, how many milliseconds, or how many microseconds? Can there be even a rough quantitative estimate? Of course, there are many factors that affect TCP's time consumption, such as network packet loss. Today I only share the relatively high incidence of various situations I encountered in my work practice.
A normal TCP connection establishment process
To understand the time-consuming establishment of a TCP connection, we need to understand the connection establishment process in detail. In the previous article "Illustrated Linux Network Packet Receiving Process" , we introduced how data packets are received at the receiving end. The data packet comes out from the sender, and reaches the receiver's network card through the network. After the receiver network card DMAs the data packet to the RingBuffer, the kernel processes it through hard interrupt, soft interrupt and other mechanisms (if user data is sent, it will finally be sent to the socket receiving queue and wake up the user process).
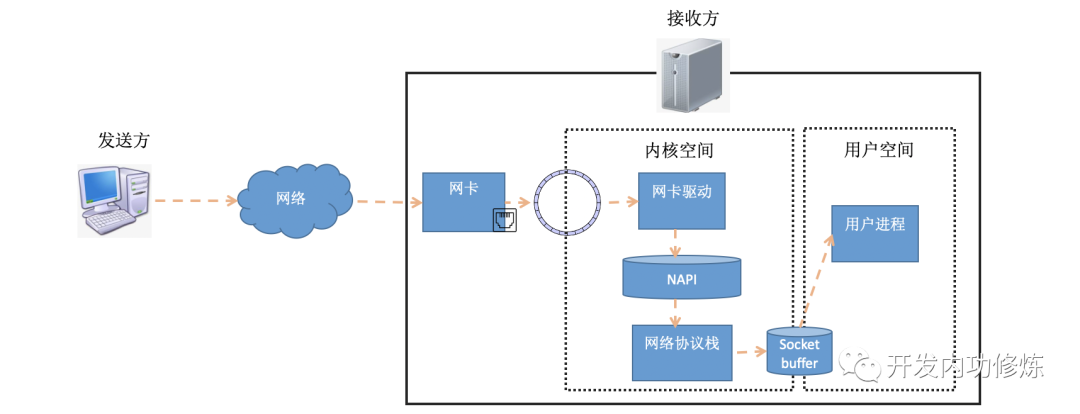
In soft interrupts, when a packet is taken from the RingBuffer by the kernel, it is represented by a struct sk_buffstructure in the kernel (see kernel code include/linux/skbuff.h). The data member is the received data. When the protocol stack is processed layer by layer, the data that each layer of protocol cares about can be found by modifying the pointer to point to different locations of data.
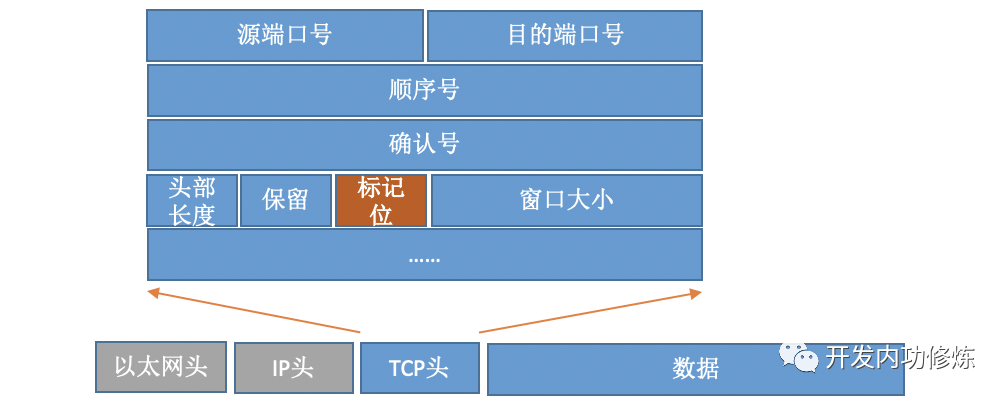
For TCP protocol packets, there is an important field-flags in its Header. As shown below:
By setting different flags, TCP packets are divided into SYNC, FIN, ACK, RST and other types. The client uses the connect system to call the command kernel to send out SYNC, ACK and other packages to establish a TCP connection with the server. On the server side, many connection requests may be received, and the kernel also needs to use some auxiliary data structures-semi-connected queues and fully connected queues. Let's take a look at the entire connection process:
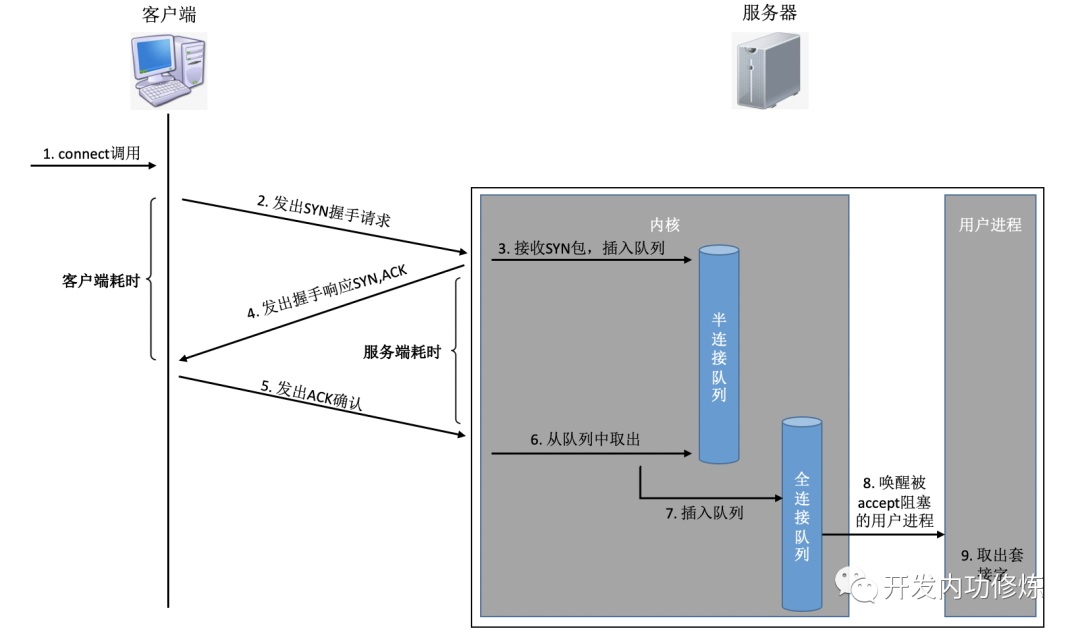
In this connection process, let’s briefly analyze the time consuming of each step
The client sends a SYNC packet: the client generally sends SYN through the connect system call, which involves the CPU time-consuming overhead of the local system call and soft interrupt
SYN is transmitted to the server : SYN is sent from the client's network card, and it starts to "cross mountains and seas, but also through the sea of people..." This is a long-distance network transmission
The server processes the SYN packet: the kernel receives the packet through a soft interrupt, then puts it in the semi-connection queue, and then sends a SYN/ACK response. CPU time-consuming overhead
SYC/ACK is transmitted to the client : After the SYC/ACK is sent from the server, it also crosses many mountains and possibly many seas to the client. Another long network trek
The client processes SYN/ACK: After the client kernel receives the packet and processes the SYN, it is processed by the CPU for a few us and then sends out an ACK. The same is soft interrupt processing overhead
ACK is transmitted to the server : the same as the SYN packet, it passes through almost the same distance and transmits it again. Another long network trek
The server receives the ACK: the server kernel receives and processes the ACK, and then takes the corresponding connection out of the semi-connection queue and puts it in the full connection queue. One soft interrupt CPU overhead
Server-side user process wakeup: The user process that is being blocked by the accpet system call is awakened, and then the established connection is taken from the full connection queue. CPU overhead of a context switch
The above steps can be simply divided into two categories:
The first category is that the kernel consumes the CPU for receiving, sending or processing, including system calls, soft interrupts, and context switches. Their time-consuming is basically a few us. For the specific analysis process, please refer to " How much is the overhead of a system call?" " , "How much CPU will soft interrupt eat you?" " , " Process / thread switch you can use up much CPU? " These three articles.
The second type is network transmission. When the packet is sent from a machine, it passes through various network cables and various switch routers. Therefore, the time-consuming network transmission is much higher than the CPU processing of this machine. According to the distance of the network, it generally ranges from a few ms to a few hundred ms. .
1ms is equal to 1000us, so the network transmission time is about 1000 times higher than the dual-end CPU overhead, and it may even be 100000 times higher. Therefore, in the normal TCP connection establishment process, the network delay can generally be considered. An RTT refers to the delay time of a packet from one server to another server. Therefore, from a global perspective, the network established by the TCP connection takes about three transmissions, plus a little CPU overhead for both parties, which is a little larger than 1.5 times RTT in total. However, from the perspective of the client, as long as the ACK packet is sent, the kernel considers the connection to be established successfully. Therefore, if the client counts the time-consuming TCP connection establishment, only two transmissions are required-that is, one RTT takes a little longer. (From the perspective of the server side, the same is true. From the beginning of the SYN packet reception to the receipt of the ACK, there is also an RTT time-consuming in the middle)
2. Abnormal situation when TCP connection is established
As you can see in the previous section, from the perspective of the client, under normal circumstances, the total time consumed by a TCP connection is about the time consumed by a network RTT. If everything is so simple, I think my sharing will be unnecessary. Things are not always so beautiful, there will always be accidents. In some cases, it may lead to increased network transmission time during connection, increased CPU processing overhead, or even connection failure. Now let's talk about the various gaps and hurdles I have encountered online.
1) The client connect system call takes time out of control
Normally, a system call takes a few us (microseconds). However, in the article "Tracking the Murderer Who Depleted the Server CPU!" a server of the author encountered a situation at that time. A certain operation and maintenance student conveyed that the service CPU was not enough and needed to be expanded. The server monitoring at that time is as follows:
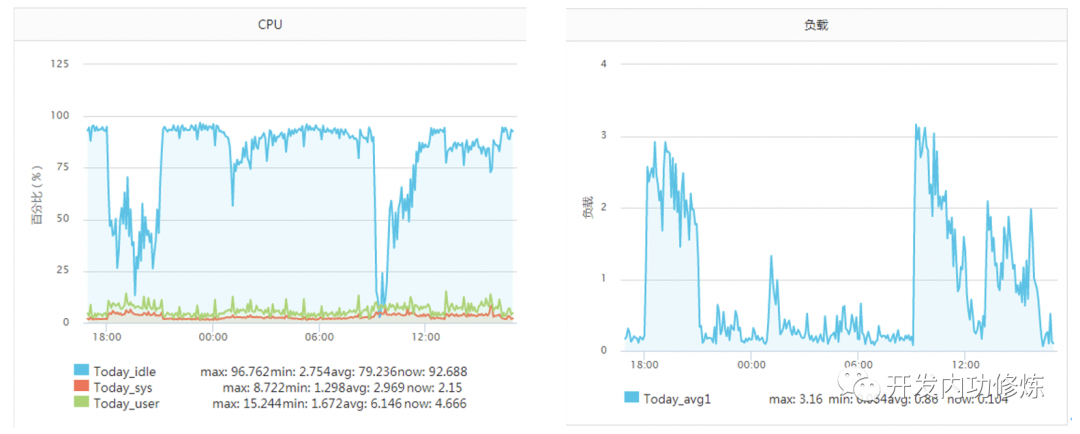
The service has been resistant to about 2000 qps per second before, and the idel of the CPU has always been 70%+. Why suddenly the CPU is not enough. What's even more strange is that the load was not high during the period when the CPU hit the bottom (the server is a 4-core machine, and the load 3-4 is normal). Later, after investigation, it was found that when the TCP client TIME_WAIT was about 30,000, which caused the available ports to be insufficient, the CPU overhead of the connect system call directly increased by more than 100 times, and the time consumption reached 2500us (microseconds) each time. Millisecond level.
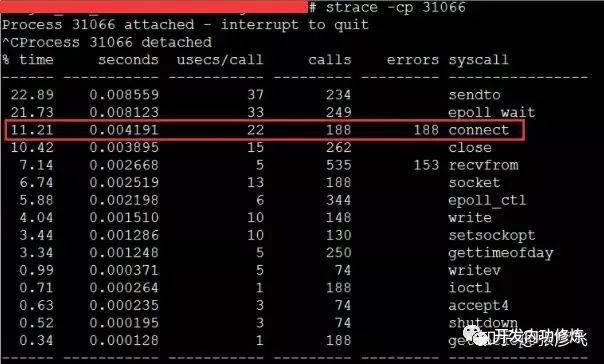
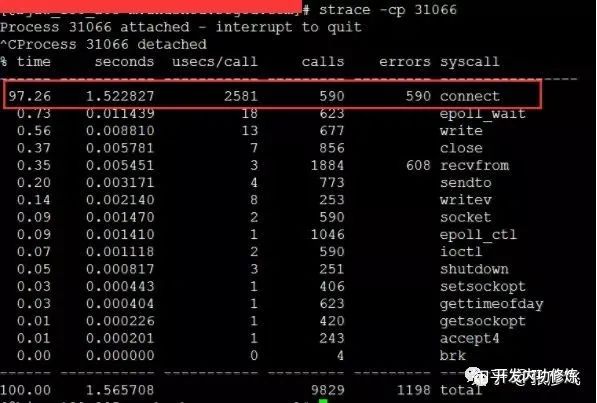
When encountering this kind of problem, although the TCP connection establishment time only increased by about 2ms, the overall TCP connection time seemed acceptable. But the problem here is that most of these 2ms are consuming CPU cycles, so the problem is not small. The solution is also very simple, and there are many ways: modify the kernel parameter net.ipv4.ip_local_port_range to reserve more port numbers, or switch to a long connection.
2) Half/full connection queue is full
If any queue is full during connection establishment, the syn or ack sent by the client will be discarded. After the client waits for a long time to no avail, it will send a TCP Retransmission. Take the example of a semi-connection queue:
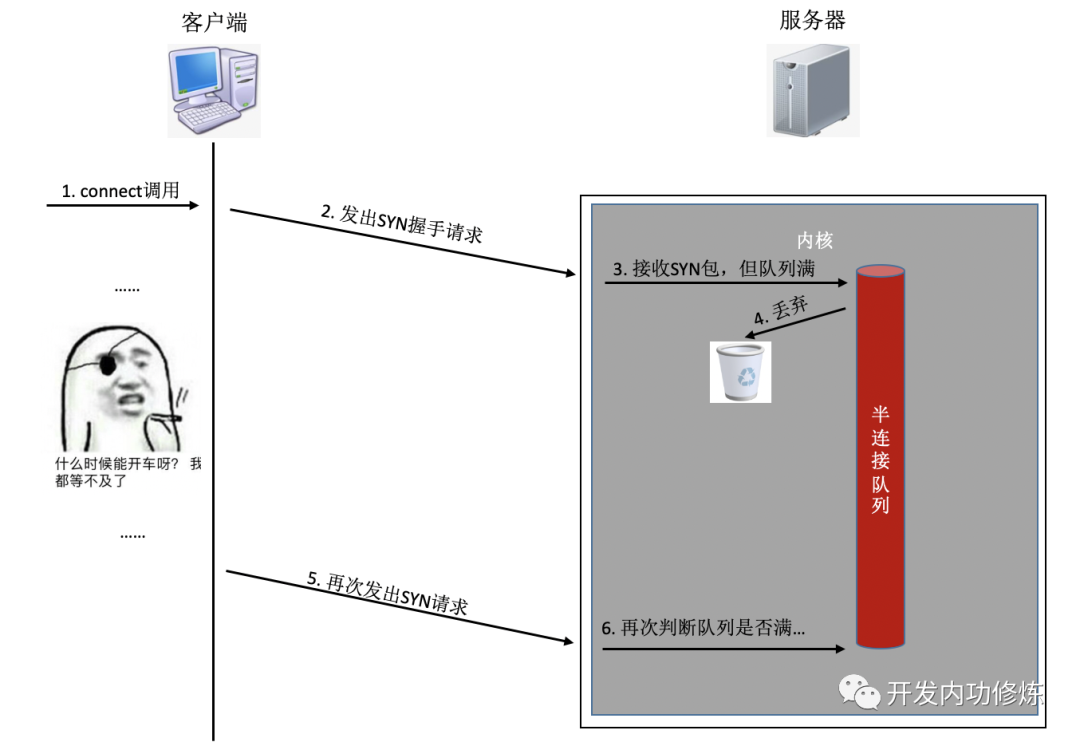
What you need to know is that the TCP handshake timeout and retransmission time above is in the second level. That is to say, once the connection queue on the server side causes the connection to be established unsuccessfully, it takes at least seconds to establish the connection. Normally, it only takes less than 1 millisecond in the same computer room, which is about 1000 times higher. Especially for programs that provide users with real-time services, the user experience will be greatly affected. If the handshake is not successful even for the retransmission, it is likely that the user cannot wait for the second retry, and the user access will directly time out.
There is another worse situation, it may also affect other users. If you are using the process/thread pool model to provide services, such as php-fpm. We know that the fpm process is blocked. When it responds to a user request, the process has no way to respond to other requests. Suppose you have opened 100 processes/threads, and within a certain period of time, 50 processes/threads are stuck in the handshake connection with the redis or mysql server ( note: at this time your server is the client side of the TCP connection ). In this period of time, there are only 50 normal working processes/threads that you can use. And this 50 workers may not be able to handle it at all, and your service may be congested at this time. If it lasts a little longer, an avalanche may occur, and the entire service may be affected.
Since the consequences may be so serious, how do we check whether the service at hand has occurred because the half/full connection queue is full? On the client side, you can capture packets to check whether there is SYN TCP Retransmission. If there are occasional TCP Retransmissions, then there may be a problem with the corresponding server connection queue.
On the server side, it is easier to view. netstat -sYou can view the statistics of packet loss caused by the current system semi-connection queue being full, but this number records the total number of packets lost. You need to use watchcommands to dynamically monitor. If the following numbers change during your monitoring process, it means that the current server has packet loss due to the full half-connection queue. You may need to increase the length of your semi-connection queue.
$ watch 'netstat -s | grep LISTEN'
8 SYNs to LISTEN sockets ignoredFor fully connected queues, the viewing method is similar.
$ watch 'netstat -s | grep overflowed'
160 times the listen queue of a socket overflowedIf your service loses packets because the queue is full, one way to do it is to increase the length of the half/full connection queue. In the Linux kernel, the semi-connection queue length is mainly affected by tcp_max_syn_backlog and it can be increased to an appropriate value.
# cat /proc/sys/net/ipv4/tcp_max_syn_backlog
1024
# echo "2048" > /proc/sys/net/ipv4/tcp_max_syn_backlogThe length of the fully connected queue is the smaller of the backlog passed in when the application calls listen and the kernel parameter net.core.somaxconn. You may need to adjust your application and this kernel parameter at the same time.
# cat /proc/sys/net/core/somaxconn
128
# echo "256" > /proc/sys/net/core/somaxconn改完之后我们可以通过ss命令输出的Send-Q确认最终生效长度:
$ ss -nlt
Recv-Q Send-Q Local Address:Port Address:Port
0 128 *:80 *:*
Recv-Q告诉了我们当前该进程的全连接队列使用长度情况。如果Recv-Q已经逼近了Send-Q,那么可能不需要等到丢包也应该准备加大你的全连接队列了。
如果加大队列后仍然有非常偶发的队列溢出的话,我们可以暂且容忍。如果仍然有较长时间处理不过来怎么办?另外一个做法就是直接报错,不要让客户端超时等待。例如将Redis、Mysql等后端接口的内核参数tcp_abort_on_overflow为1。如果队列满了,直接发reset给client。告诉后端进程/线程不要痴情地傻等。这时候client会收到错误“connection reset by peer”。牺牲一个用户的访问请求,要比把整个站都搞崩了还是要强的。
三TCP连接耗时实测
我写了一段非常简单的代码,用来在客户端统计每创建一个TCP连接需要消耗多长时间。
<?php
$ip = {服务器ip};
$port = {服务器端口};
$count = 50000;
function buildConnect($ip,$port,$num){
for($i=0;$i<$num;$i++){
$socket = socket_create(AF_INET,SOCK_STREAM,SOL_TCP);
if($socket ==false) {
echo "$ip $port socket_create() 失败的原因是:".socket_strerror(socket_last_error($socket))."\n";
sleep(5);
continue;
}
if(false == socket_connect($socket, $ip, $port)){
echo "$ip $port socket_connect() 失败的原因是:".socket_strerror(socket_last_error($socket))."\n";
sleep(5);
continue;
}
socket_close($socket);
}
}
$t1 = microtime(true);
buildConnect($ip, $port, $count);
echo (($t2-$t1)*1000).'ms';在测试之前,我们需要本机linux可用的端口数充足,如果不够50000个,最好调整充足。
# echo "5000 65000" /proc/sys/net/ipv4/ip_local_port_range
1)正常情况
注意:无论是客户端还是服务器端都不要选择有线上服务在跑的机器,否则你的测试可能会影响正常用户访问
首先我的客户端位于河北怀来的IDC机房内,服务器选择的是公司广东机房的某台机器。执行ping命令得到的延迟大约是37ms,使用上述脚本建立50000次连接后,得到的连接平均耗时也是37ms。这是因为前面我们说过的,对于客户端来看,第三次的握手只要包发送出去,就认为是握手成功了,所以只需要一次RTT、两次传输耗时。虽然这中间还会有客户端和服务端的系统调用开销、软中断开销,但由于它们的开销正常情况下只有几个us(微秒),所以对总的连接建立延时影响不大。
接下来我换了一台目标服务器,该服务器所在机房位于北京。离怀来有一些距离,但是和广东比起来可要近多了。这一次ping出来的RTT是1.6~1.7ms左右,在客户端统计建立50000次连接后算出每条连接耗时是1.64ms。
再做一次实验,这次选中实验的服务器和客户端直接位于同一个机房内,ping延迟在0.2ms~0.3ms左右。跑了以上脚本以后,实验结果是50000 TCP连接总共消耗了11605ms,平均每次需要0.23ms。
线上架构提示:这里看到同机房延迟只有零点几ms,但是跨个距离不远的机房,光TCP握手耗时就涨了4倍。如果再要是跨地区到广东,那就是百倍的耗时差距了。线上部署时,理想的方案是将自己服务依赖的各种mysql、redis等服务和自己部署在同一个地区、同一个机房(再变态一点,甚至可以是甚至是同一个机架)。因为这样包括TCP链接建立啥的各种网络包传输都要快很多。要尽可能避免长途跨地区机房的调用情况出现。
2)连接队列溢出
测试完了跨地区、跨机房和跨机器。这次为了快,直接和本机建立连接结果会咋样呢?Ping本机ip或127.0.0.1的延迟大概是0.02ms,本机ip比其它机器RTT肯定要短。我觉得肯定连接会非常快,嗯实验一下。连续建立5W TCP连接,总时间消耗27154ms,平均每次需要0.54ms左右。嗯!?怎么比跨机器还长很多? 有了前面的理论基础,我们应该想到了,由于本机RTT太短,所以瞬间连接建立请求量很大,就会导致全连接队列或者半连接队列被打满的情况。一旦发生队列满,当时撞上的那个连接请求就得需要3秒+的连接建立延时。所以上面的实验结果中,平均耗时看起来比RTT高很多。
在实验的过程中,我使用tcpdump抓包看到了下面的一幕。原来有少部分握手耗时3s+,原因是半连接队列满了导致客户端等待超时后进行了SYN的重传。

我们又重新改成每500个连接,sleep 1秒。嗯好,终于没有卡的了(或者也可以加大连接队列长度)。结论是本机50000次TCP连接在客户端统计总耗时102399 ms,减去sleep的100秒后,平均每个TCP连接消耗0.048ms。比ping延迟略高一些。这是因为当RTT变的足够小的时候,内核CPU耗时开销就会显现出来了,另外TCP连接要比ping的icmp协议更复杂一些,所以比ping延迟略高0.02ms左右比较正常。
四结论
TCP连接建立异常情况下,可能需要好几秒,一个坏处就是会影响用户体验,甚至导致当前用户访问超时都有可能。另外一个坏处是可能会诱发雪崩。所以当你的服务器使用短连接的方式访问数据的时候,一定要学会要监控你的服务器的连接建立是否有异常状态发生。如果有,学会优化掉它。当然你也可以采用本机内存缓存,或者使用连接池来保持长连接,通过这两种方式直接避免掉TCP握手挥手的各种开销也可以。
Besides, under normal circumstances, the delay of TCP establishment is about an RTT time between two machines, which is unavoidable. But you can control the physical distance between the two machines to reduce this RTT, such as deploying the redis you want to access as close to the back-end interface machine as possible, so that the RTT can also be reduced from tens of ms to the lowest possible zero. A few ms.
Finally, let's think again, if we deploy the server in Beijing, is it feasible to give users in New York access? Whether we are in the same computer room or across computer rooms, the time consumption of electrical signal transmission is basically negligible (because the physical distance is very close), and the network delay is basically the time consumed by the forwarding equipment. But if it crosses half of the earth, the transmission time of the electric signal can be calculated. The spherical distance from Beijing to New York is about 15,000 kilometers. Then, regardless of the device's forwarding delay, only the speed of light travels back and forth (RTT is Rround trip time, which requires two runs), and it takes time = 15,000,000 *2 / speed of light = 100ms. The actual delay may be larger than this, generally more than 200ms. Based on this delay, it is very difficult to provide second-level services that users can access. Therefore, for overseas users, it is best to build a local computer room or purchase an overseas server.