Recently, I learned target detection because of work needs.
darknet download https://github.com/pjreddie/darknet
yolov3.weights download https://github.com/ultralytics/yolov3
I use the darknet framework + yolov3-tiny (I used yolov3 at first, but my computer is ultra-thin, and the video memory is not enough. The parameter bs in the .cfg file is set unreasonably. Because of the help of a big guy, let I realize this, otherwise I myself may never understand why the data efficiency of my training model is so low)
The darknet framework is downloaded on github. My entire learning process is under the win10 development platform. After darknet is downloaded, I will decompress it (then I don’t know if it is necessary. This framework is developed in C language, so I use vs2015)
Then click darknet.sln and it will automatically enter the vs2015 interface, and then refer to the following blog to configure all aspects of darknet. Note that you must install gpu, otherwise the speed is really unimaginable slow. At first I thought it was a problem elsewhere, but later found out that it was really too slow without GPU.
Then download the yolovc3.weights file to this page
Click this file to run automatically, and you will see the picture given to Heche on the official website
If you want to try another picture, right-click the file and edit it, and there will be the following interface, my representative is in training

darknet.exe detector test cfg/obj.data yolov3-tiny.cfg backup/yolov3-tiny_200.weights -i 0 -thresh 0.25 data/img/2.jpg -ext_outputpause
The normal official website test code is written like the above. You need to test the picture. If it is in the same directory as darknet_yolo_v3.cmd, write the file name directly. Others should pay attention to the path problem.
darknet.exe detector test cfg/obj.data yolov3-tiny.cfg -map
darknet.exe detector test cfg/obj.data yolov3-tiny.cfg darknet53.conv.74
The training code is written as above. Both the first and second lines are fine. The second line is written by adding a weight file. The files after the test must pay attention to the path problem. yolov3-tiny.cfg is because of it. Is in the x64 directory, so you don’t need to add a directory if you don’t, you must pay attention to this


When I first started training, there would be this pop-up window, and my initial data results were not good, so there was no data to show on it. I don’t know what happened. Later, a kind person (that person is really very good Okay, otherwise my blog will become dirty, and I can’t train my own model.) This is the parameter that can represent the model you trained. The -map parameter will not appear until a certain level of training. The two pictures are generally as if the loss drops below 0.0, and it is only possible for mAP 70+ (the meaning of the parameters will be added when I am not lazy next time)
I reported an error during the training time. I didn’t find it on the Internet because of what the good guy told me. It was because of the computer configuration. I suggest people with poor computer video memory not to use it for target detection. If it is really data If necessary, it may burn your notebook, and the training effect is not particularly good
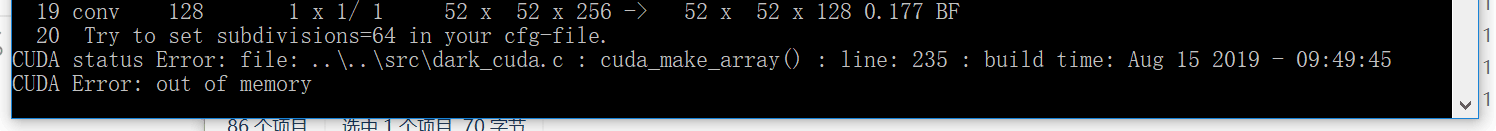
I just reported this error. I changed the parameters in the .cfg file and it didn't work. It was because of a problem with my notebook. If I checked it myself, I couldn't find it. Because yolov3 is a 53-layer network, the computer’s video memory is not good, so I replaced it with yolov3-tiny. This network is less so that my notebook can run, but the computer is also very hot.

My initial data looks like the above, which is really very, very bad. In addition to the data problem, you must find the reason for the .cfg file. At first I thought it was a problem with data pictures, but later I found a problem with the configuration of the .cfg file,
By the way, the last thing I want to talk about is data labeling, that is, don’t we want to train pictures. Before training, we have to label each picture by ourselves. I have read a lot, and I didn’t find any special attention. That is, a picture can have multiple labels or only one label. I use the yolo-mark tool, because it is not as simple as the voc and xml files mentioned on the Internet (but that is better than the one I used), this is a direct mark, as long as it is put in the darknet folder, there are four Each file can be voc.data voc.names img (the first picture in the picture folder must correspond to a .txt file, this is the function of data annotation), train.txt (this is the record file of data annotation)

The result of this kind of data is okay. Looking at most blogs on the Internet, there is no v3 (mse loss, Normalizer:(iou:0.750000) cls:1.000000) sentence. I was very worried. Later I learned that the new version of ab optimization After adding some super parameters
So don’t be afraid, I remember my mistakes are just that, and I’ll add something to it when I have a chance.