Author: laboratory Chen / Big Data Laboratory
In the previous article "Analysis of In-Memory Database and Comparison of Mainstream Products (2)", we introduced the characteristics of in-memory database and the technical implementation of several products from the perspective of data organization and indexing. This article will continue to analyze the in-memory database, introduce several technologies from the perspective of concurrency control, persistence and query processing, and bring more dimensions and more detailed in-memory database technology discussions.
— Concurrency control in database management system —
1. Two strategies for concurrency control in memory databases
a. Multi-version concurrency control Concurrency control in
memory databases mainly adopts two types of strategies: 1. Multi-version concurrency control; 2. Partition processing. Concurrency control mechanisms can be divided into two types: optimistic and pessimistic. Pessimistic concurrency control believes that there is always competition for resources in the process, so it is locked first when accessing, and then released after access; optimistic concurrency control believes that most situations do not need to compete for resources, and only check whether there is a conflict before the final submission. Roll back, commit if not.
Optimistic concurrency control mostly does not use lock-based technology to achieve, and usually multi-version. Multi-version means that each update will produce a new version. The read operation selects the appropriate old version according to the visible range. The read operation does not block the write operation, so the degree of concurrency is relatively high. The disadvantage is that it will incur additional costs, such as creating new versions for updates, and as more and more versions, additional costs are required to recover the old version. In-memory databases mostly use an optimistic multi-version concurrency control mechanism. Compared with lock-based pessimistic concurrency control, its advantage is that it has lower overhead and supports scenarios with higher concurrency; the disadvantage is that in scenarios with a lot of write competition, transactions between transactions When the conflict probability is relatively high, a large number of transactions will fail and roll back.
b. Partition processing
Another strategy for concurrency control of in-memory databases is to divide the database into multiple Partitions, and each Partition handles transactions in a serial manner. The advantage is that the execution of a single Partition service does not have additional overhead for concurrency control. The disadvantage is that the throughput rate of the system will plummet when there are cross-partition transactions. Therefore, if it is not guaranteed that all services are performed in a single Partition, the performance will be unpredictable.
2.
Hekaton of multi-version concurrency control Hekaton adopts optimistic multi-version concurrency control. When the transaction starts, the system assigns a read timestamp to the transaction and marks the transaction as active, and then starts to execute the transaction. During the operation, the system records the data read/scanned/written. Subsequently, in the Pre-commit phase, first obtain an end timestamp, and then verify whether the version of the read and scanned data is still valid. If the verification passes, write a new version to the log, execute Commit, and then set all new versions to be visible. After Commit, Post-Processing records the version timestamp, and then the Transaction really ends. 
a. Hekaton's transaction verification
i) Read Stability : The Hekaton system can guarantee the read stability of the data (Read Stability), for example, the version of each record read at the beginning of the transaction is still visible at the time of Commit, thereby achieving Read Stability.
ii) Phantom Avoidances : Phantom means that the same conditional query is executed at the beginning and end of a transaction, and the two results are different. The reason for the phantom is that during the execution of the transaction, other transactions added/deleted/updated the same data set. How to avoid phantom phenomenon? Repeated scanning can be used to check whether the read data has a new version, and to ensure that the version recorded at the beginning of the transaction is the same at the end.
The advantage of Hekaton concurrency control is that there is no need to verify the Read-Only transaction, because multiple versions can ensure that the record version at the beginning of the transaction still exists at the end. For transactions that perform updates, whether to verify is determined by the isolation level of the transaction. For example, if the snapshot isolation level is required, there is no need to do any verification; if repeatable reads are to be required, Read Stability is required; if it is the serialization isolation level, both Read Stability and Phantom Avoidance must be guaranteed.
b. Hekaton's recycling strategy
The recovery task in Hekaton is not processed by an independent thread, but each transaction is recovered by itself. As shown in the figure below, the transaction end timestamp with Transaction ID 250 is 150 and the status is terminated. At this time, there will be a Write Set to get all the old versions and determine whether the start timestamp of all current active transactions is greater than the ID 250. The end time of the transaction, which is 150. If both are greater than 150, it means that it is impossible to modify the old version based on the timestamp earlier than 150, so the old version is recycled by the transaction. This part of the work is an extra work for each thread when processing the Transaction. 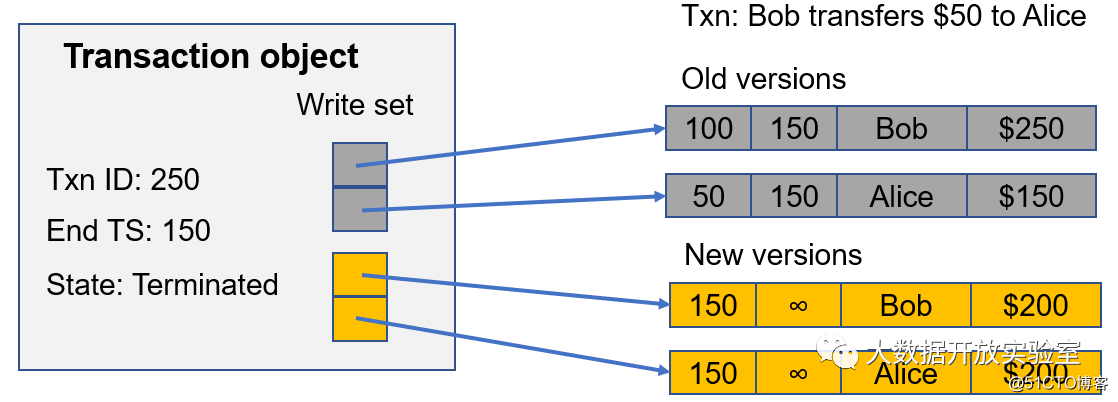
3. Hyper for multi-version concurrency control
The difference between Hyper's concurrency control and Hekaton is mainly as follows: 1. Update directly at the record location, save the data modification through the undo buffer, and the data and all modifications are linked together; 2. The verification is based on the latest update It is achieved by comparing with the read records (will be involved later); 3. Serialize the commit, sort the submitted transactions, and process them in turn. 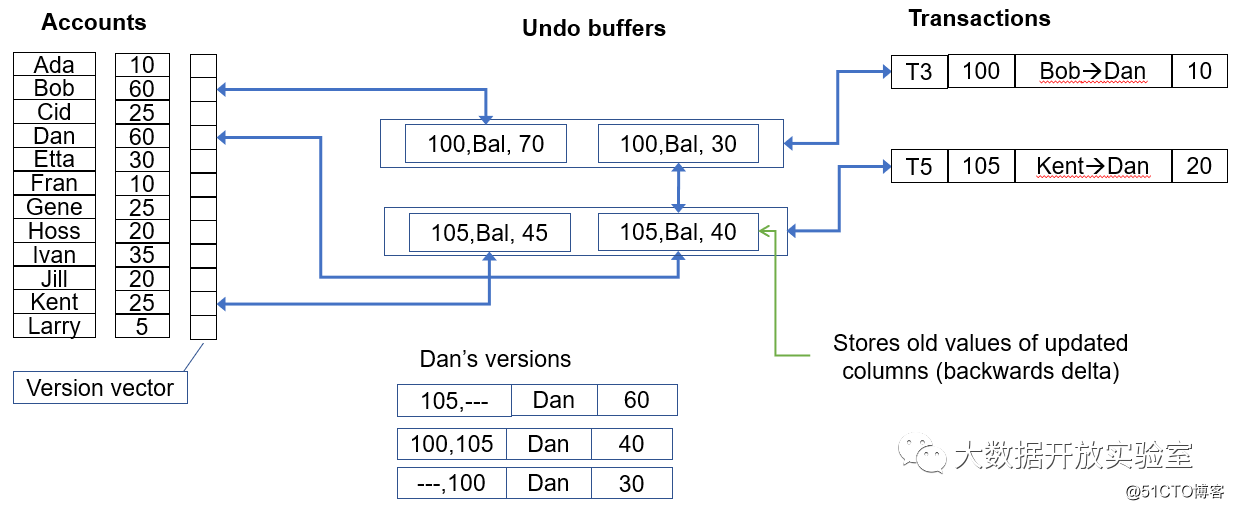
In terms of transaction verification, Hyper verification needs to record Read Predictates in the log, including queries or Range Scan, and record insert, delete, and update records. In Hyper mode, insert/delete/update learns the modified records through the corresponding Undo Buffer, so record changes are easy for Hyper.
For each Transaction, you only need to compare the transaction from the beginning to the Commit, whether there are other transactions that have added/deleted/modified the data set that meets the search conditions, so as to determine whether there is a phantom phenomenon, and if it exists, terminate the transaction directly .
4. HANA and HStore/VoltDB for multi-version concurrency control
The HANA parallel control method is relatively simple. It adopts pessimistic multi-version control. The data structure is protected by row-level locks. Each row is determined by a timestamp to determine the visible range of each version. Each Transaction needs to apply for a write lock when it is updated or deleted, and deadlock detection is required.
HStore/VoltDB is a Partition system. The granularity of the lock is very coarse. Each Partition corresponds to a lock. Therefore, when a transaction is executed on a node, it needs to get all the resources of the node. Once a transaction may involve two Partitions, you need to get the locks of both Partitions. Therefore, the advantage of the Partition system is that the processing speed of a single Partition is very fast, but the disadvantage is that the efficiency of multiple Partitions is very low. At the same time, the system is very sensitive to load skew. If there is hot data, the hot data constitutes a system bottleneck.
5. Load prediction for multi-version concurrency control
Assuming that in a workload, the data set that transactions need to read and write can be obtained in advance, and the execution order of all transactions can be determined before execution. Calvin is a VLL (Very Lightweight Locking) ultra-lightweight lock database prototype system designed based on this assumption. It is impossible to know the read-write set in advance for the workload of the general scenario, but in the application of the stored procedure business, the read-write set can be determined in advance. For these scenarios, a system like Calvin can be considered.
— Persistence technology in database management system —
For in-memory databases, logs and checkpoints are required in the same way as disk-based databases. The purpose of Checkpoint is to recover from the most recent checkpoint without having to replay all the data. Because Checkpoint involves the operation of writing to disk, it affects performance, so it is necessary to speed up related processing as much as possible.
One difference is that the log and checkpoint of the memory database may not contain an index, and the index is reconstructed from the basic data during recovery. The index in the in-memory database is reconstructed when it is restored. After the construction is completed, it is also placed in the memory without placing it on the disk. If the memory index data is lost, it can be reconstructed. Another difference is that the amount of data in the memory database Checkpoint is larger. When a disk-oriented database is in Checkpoint, you only need to write all Dirty Pages in the memory to disk, but the in-memory database Checkpoint needs to write all the data to the disk. No matter how large the data volume is, it must be written in full, so the memory database Checkpoint The data written to disk at the time is much larger than disk-based databases.
Hekaton Checkpoint
For the performance optimization of persistence, the first is to ensure high throughput and low latency when writing logs, and the second is to consider how to quickly reconstruct the entire database during recovery. Hekaton's records and indexes are stored in memory, and all operations are written to disk. The log only records data updates, not index updates. During Checkpoint, Hekaton will recover from the log and process in parallel according to the primary key range. As shown in the figure below, there are three primary key ranges: 100~199, 200~299, 300~399. Green represents data, and red represents deleted records (the deleted files are saved separately). During recovery, Hekaton uses a parallel algorithm to reconstruct indexes and data in memory. In the process, the data files are filtered according to the deleted records, the deleted data is removed, and then the data is played back according to the log from the Checkpoint point. 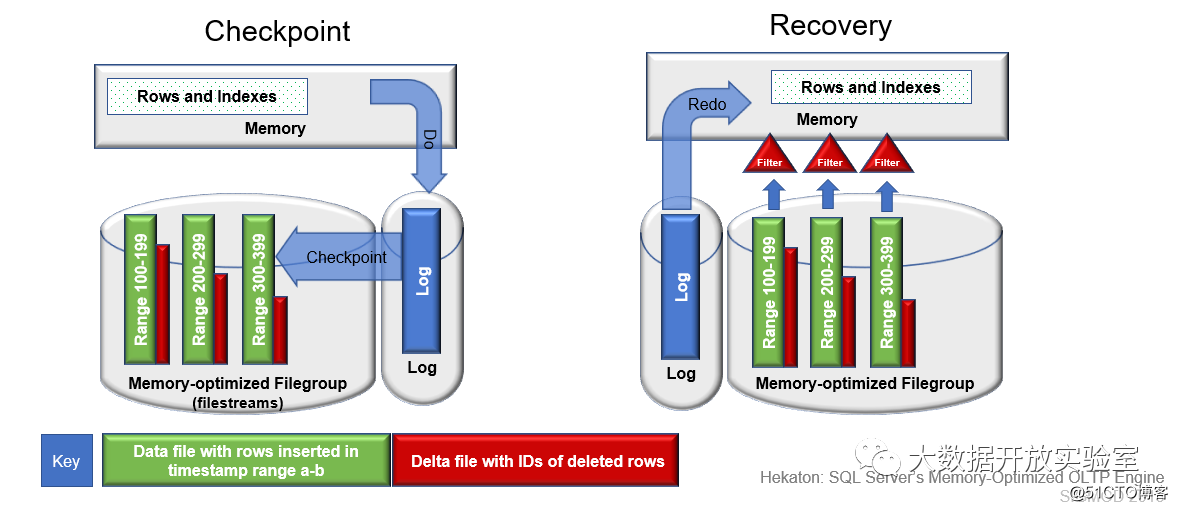
Checkpoints of other systems
1. The system that uses Logic Logging, such as H-Store/VoltDB, does not record specific data changes, but records executed operations and instructions. Its advantage is that it records less log information. When writing the log, HStore/VoltDB adopts the COW (Copy-on-Write) mode, that is, the normal state is a single version, but when writing the log, it will "copy" another version, and then merge the version after writing.
2. The other is to periodically write Snapshots to disk (excluding indexes). For example, Hyper provides Snapshots based on the Folk function of the operating system.
— Query processing in database management system —
Traditional query processing uses the volcano model. Each node on the query tree is a general operator. The advantage is that Operators can be combined arbitrarily. But the record that Operator gets is just a byte array, and another method needs to be called to parse the attribute and attribute type. If this design is placed in an in-memory database, the analysis of attributes and types is done at Runtime rather than at compile time, which will affect performance.
In addition, for get-next, if there are millions of data, it will be called a million times. At the same time, get-next is usually implemented as a virtual function. Calling through a pointer, compared to calling directly through a memory address, will affect performance. In addition, the distribution of such function codes in the memory is non-continuous and must be constantly jumped. In summary, the query processing methods of traditional DBMS are not applicable to memory databases, especially when executed at the bottom. 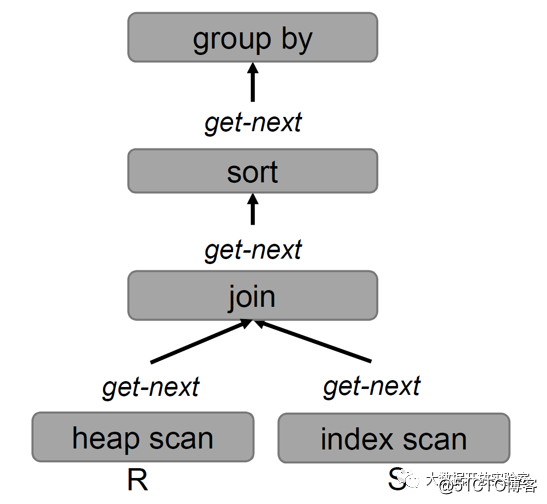
In-memory databases usually adopt the method of compilation and execution. First, the query is parsed, then the parsed statement is optimized, and the execution plan is generated, and then the execution plan is compiled according to the template to generate executable machine code, and then the machine code is loaded into the database engine , It is called directly during execution. 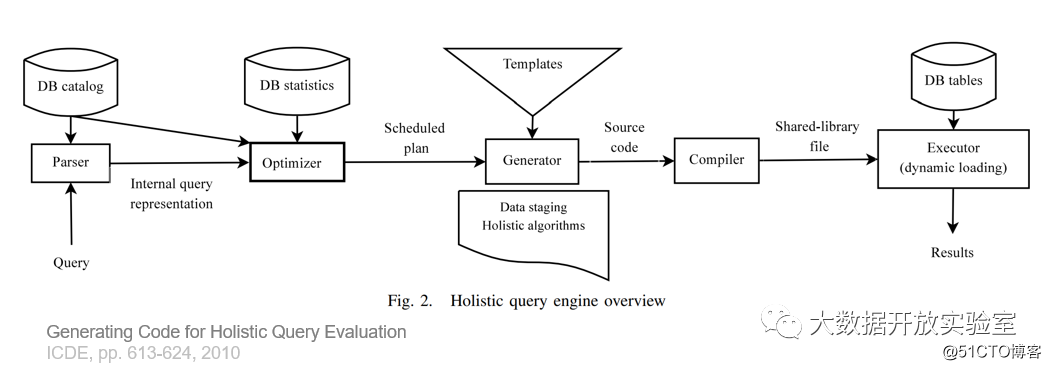
The following figure is a time-consuming analysis of different query methods. It can be seen that the proportion of Resource Stall in the compilation and execution method is very small. 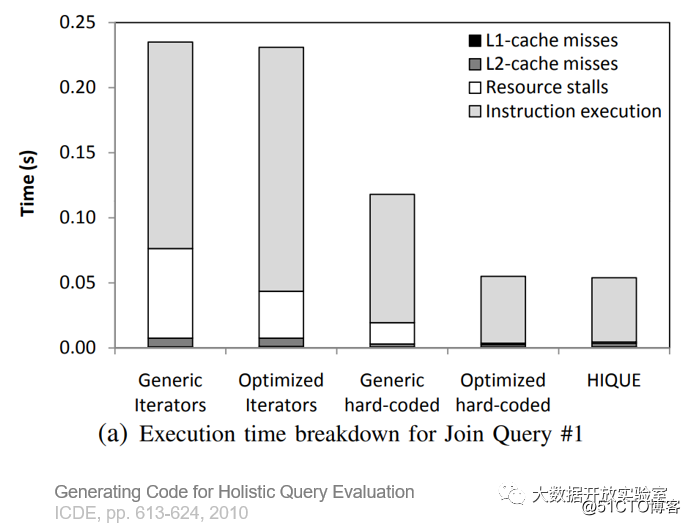
Another picture explains the current implementation of the CPU architecture. There is a Hardware Pre-fetcher between the L2 Cache and the main memory. L2 Cache is divided into instruction Cache and Data Cache. Instruction Cache will be predicted by Branch Prediction, and Data Cache will be predicted by Pre-fetcher based on Sequential Pattern. Therefore, the design of the database system needs to consider how to make full use of the Pre-fetcher function under this architecture, so that Cache can continuously provide instructions and data to the CPU computing unit, and avoid Cache Stall. 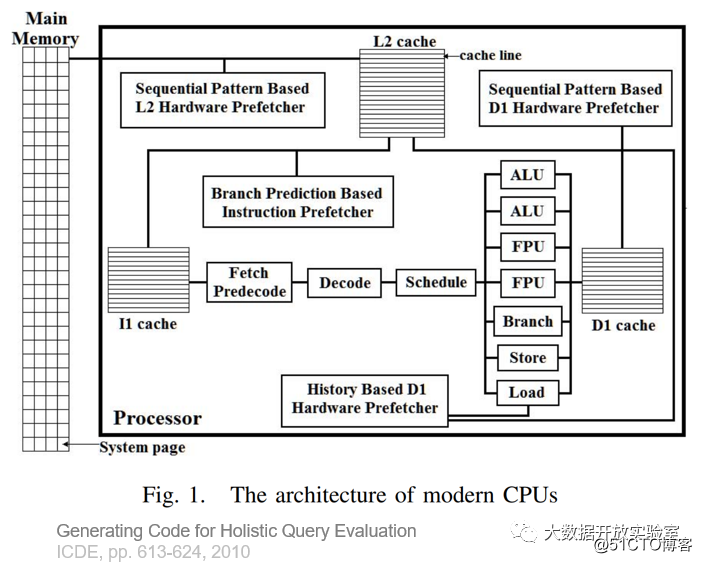
Hekaton compiled query processing
Hekaton's compilation uses T-SQL stored procedures, the intermediate form of compilation is called MAT Generator, and the final C code is generated and executed in the compiler. The difference between the library it generates and the general operator is: the general operator needs to interpret the data type at runtime; and the Hekaton compilation method is to compile the table definition and query together. Each library can only process the corresponding table but not the general. You can get the data type, and such an implementation can achieve a performance improvement of 3 to 4 times. 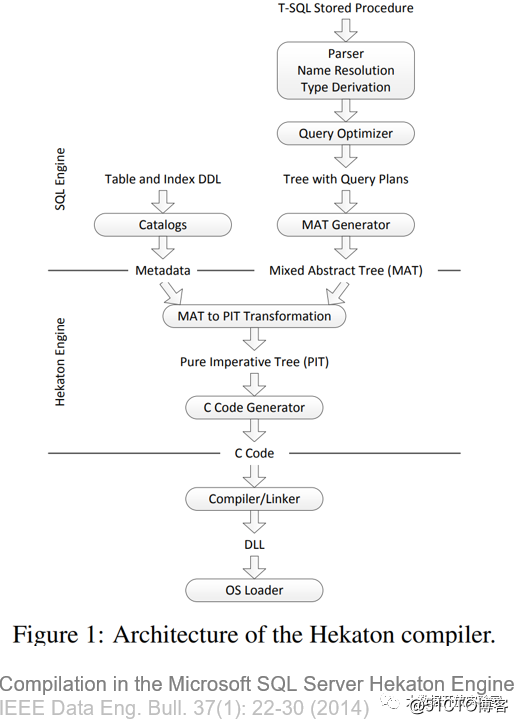
HyPer and MemSQL compiled query processing
HyPer's compilation method is to compile each segment of the query tree according to the dividing point of the Pipeline. MemSQL uses LLVM to compile and compiles MPI language into code. 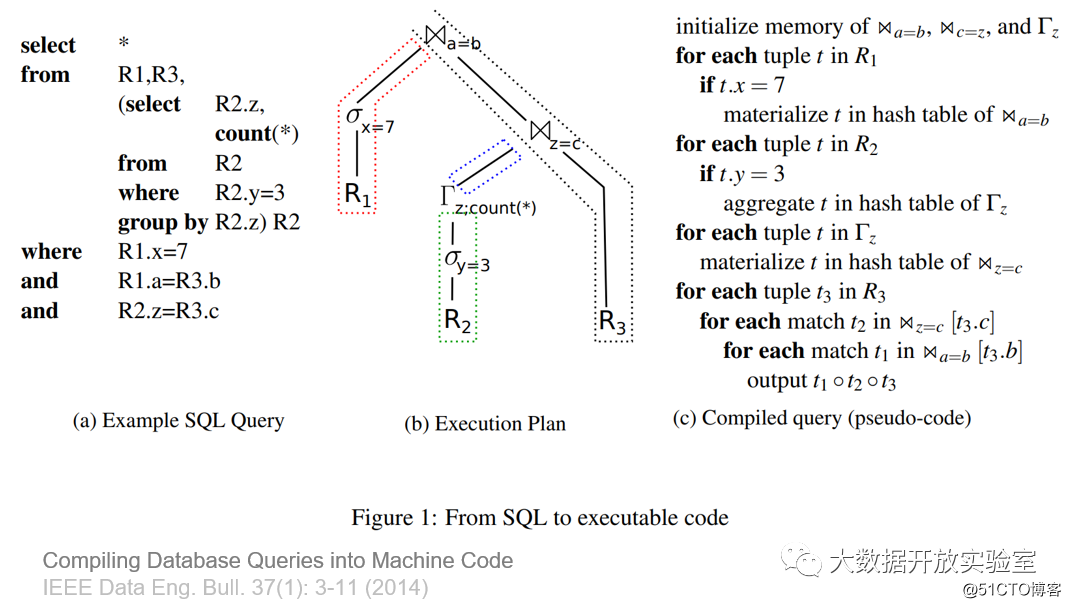
The figure below is a test of MemSQL performance. When it is not compiled and executed, MemSQL takes 0.05 seconds to execute the same query twice; if compiled and executed, it takes 0.08 seconds for the first time, but only 0.02 seconds for re-execution.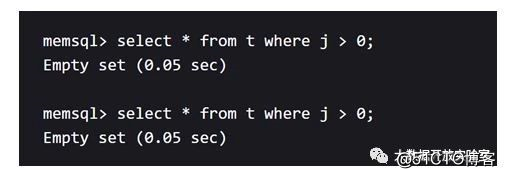

**— Other memory database systems—
**
In addition to the several in-memory databases mentioned earlier, there are other well-known in-memory DBMSs.
i) SolidDB : A hybrid database system that was born in 1992. It also has an optimization engine based on disk and memory. It uses a VTRIE (Variable-length Trie) tree index and a pessimistic lock mechanism for concurrency control, and is restored through Snapshot Checkpoints.
ii) Oracle Times Ten : In the early days, it was a research project called Smallbase by HP Labs. It was acquired by Oracle in 2005. Now it is mostly used as the front-end memory acceleration engine for large database systems. Oracle Times Ten supports flexible deployment, with independent DBMS engine and RDBMS-based transaction cache; it supports Memory Repository when working in BI, and uses Locking for concurrency control; uses row-level latching to handle write conflicts, and uses Write-Ahead Logging and Checkpoint mechanism improves durability.
iii) Altibase : Founded in South Korea in 1999, it is widely used in telecommunications, finance and manufacturing. Altibase stores records on Page, uses Page as the granularity to checkpoint and is compatible with traditional DBMS engines; supports multi-version concurrency control, uses pre-written log records and checkpoints to achieve persistence and recovery capabilities, and Checkpoints Page data through Latching-Free .
* iv) P Time* : Originated in South Korea in the 21st century, it was sold to SAP in 2005 and is now part of SAP HANA. P Time has excellent performance processing, uses differential encoding (XOR) for log records, adopts a mixed storage layout, and supports a database management system that is larger than memory (Larger-than-Memory).
— Summary of this article—
Each database system is designed for a specific hardware environment. Disk-based database systems face the design of a single CPU core, small memory, and slow disk. The in-memory database uses memory as the main memory and does not need to repeatedly read and write to the disk. Disk I/O is no longer a performance bottleneck, but other bottlenecks must be solved, such as: 1. Locking/Latching overhead; 2. Cache-Line Miss, That is, if the data structure is not well defined or is not well organized in memory, it cannot match the CPU's hierarchical cache, which will result in poor computing performance; 3. Pointer Chasing, which requires another pointer to explain, or check another table to check Going to the record address is also the main performance overhead. In addition, there are costs such as Predicate Evaluation calculation, large number of copies during data migration/storage, and network communication between distributed system applications and database systems.
In this column, we introduced the characteristics of traditional disk-based DBMS and in-memory databases, and discussed the similarities and differences between in-memory databases and disk-based databases in terms of data organization, indexing, concurrency control, statement processing compilation, and persistence. Introduced:
1. Data organization : In the memory database, records are divided into fixed-length and variable-length management, without continuous data storage, and pointers are used to replace the indirect access of Page ID + Offset;
- Index optimization : Consider Latch-Free technologies such as in-memory Cach Line optimization, fast memory access, and index updates without logging, etc.;
3. Concurrency control : pessimistic and optimistic concurrency control methods can be used, but the difference from traditional disk-based databases is that the in-memory database lock information and data binding, instead of a separate Lock Table management;
-
Query processing : There is little difference between sequential access and random access performance in the memory database scenario. Can improve query performance through compilation and execution;
- Persistence : Logging is still done through WAL (Write-Ahead Logging), and lightweight logs are used. The content of log records is as small as possible. The purpose is to reduce the delay of log writing to disk.
Since the 1970s, the in-memory database has experienced theoretical maturity, production, and market verification. With the emergence of high-concurrency, high-traffic, and low-latency platforms such as Internet seckill, mobile payment, and short video platforms, huge demands and challenges are put forward for database performance. At the same time, the memory itself has been continuously improved in terms of capacity and unit price friendliness, and the recent development of non-volatile storage (NVM) has promoted the development of in-memory databases. These factors make in-memory databases have a broad market and landing opportunities in the future.
Note: The relevant content of this article refers to the following materials:
-
Pavlo, Andrew & Curino, Carlo & Zdonik, Stan. (2012). Skew-aware automatic database partitioning in shared-nothing, parallel OLTP systems. Proceedings of the ACM SIGMOD International Conference on Management of Data. DOI: 10.1145/2213836.2213844.
-
Kemper, Alfons & Neumann, Thomas. (2011). HyPer: A hybrid OLTP&OLAP main memory database system based on virtual memory snapshots. Proceedings - International Conference on Data Engineering. 195-206. DOI: 10.1109/ICDE.2011.5767867.
-
Faerber, Frans & Kemper, Alfons & Larson, Per-Åke & Levandoski, Justin & Neumann, Tjomas & Pavlo, Andrew. (2017). Main Memory Database Systems. Foundations and Trends in Databases. 8. 1-130. DOI: 10.1561/1900000058.
-
Sikka, Vishal & Färber, Franz & Lehner, Wolfgang & Cha, Sang & Peh, Thomas & Bornhövd, Christof. (2012). Efficient Transaction Processing in SAP HANA Database –The End of a Column Store Myth. DOI: 10.1145/2213836.2213946.
- Diaconu, Cristian & Freedman, Craig & Ismert, Erik & Larson, Per-Åke & Mittal, Pravin & Stonecipher, Ryan & Verma, Nitin & Zwilling, Mike. (2013). Hekaton: SQL server's memory-optimized OLTP engine. 1243-1254. DOI: 10.1145/2463676.2463710.