One, EXPLAIN
To do MySQL optimization, we must make good use of EXPLAIN to view the SQL execution plan.
Here is a simple example, label (1,2,3,4,5) the data we want to focus on

- Type column, connection type. A good SQL statement must at least reach the range level. Put an end to all levels
- The key column, the index name used. If no index is selected, the value is NULL. Mandatory indexing can be adopted
- key_len column, index length
- rows column, the number of scanning rows. This value is an estimate
- Extra column, detailed description. Note that the common unfriendly values are: Using filesort, Using temporary
Two, the value of IN in the SQL statement should not be too many
MySQL has made corresponding optimization for IN, that is, all the constants in IN are stored in an array, and this array is sorted. However, if the value is large, the consumption is relatively large. Another example: select id from table_name where num in(1,2,3) For continuous values, do not use in if you can use between; or use connection to replace.
Three, the SELECT statement must specify the field name
SELECT * increases a lot of unnecessary consumption (cpu, io, memory, network bandwidth); increases the possibility of using a covering index; when the table structure changes, the pre-break also needs to be updated. So it is required to connect the field name directly after the select.
4. When only one piece of data is needed, use limit 1
This is to make the type column in EXPLAIN reach const type
5. If the index is not used in the sort field, try to sort as little as possible
6. If there is no index in other fields in the restriction conditions, use or as little as possible
If one of the fields on both sides of or is not an index field, and other conditions are not an index field, the query will not be indexed. Many times use union all or union (when necessary) instead of "or" to get better results
Seven, try to use union all instead of union
The main difference between union and union all is that the former needs to combine the result set and then perform unique filtering operation, which will involve sorting, increase a lot of CPU operations, increase resource consumption and delay. Of course, the prerequisite for union all is that there is no duplicate data in the two result sets.
8. Do not use ORDER BY RAND()
select id from `table_name` order by rand() limit 1000;
The above sql statement can be optimized as
select id from `table_name` t1 join (select rand() * (select max(id) from `table_name`) as nid) t2 ont1.id > t2.nid limit 1000;
Nine, distinguish between in and exists, not in and not exists
select * from 表A where id in (select id from 表B)
The above sql statement is equivalent to
select * from 表A where exists(select * from 表B where 表B.id=表A.id)
The main reason for distinguishing between in and exists is the change in the driving order (this is the key to performance changes). If it is exists, then the outer table is the driving table and is accessed first. If it is IN, then the subquery is executed first. So IN is suitable for the case where the outer surface is large and the inner surface is small; EXISTS is suitable for the case where the outer surface is small and the inner surface is large.
Regarding not in and not exists, it is recommended to use not exists, not just for efficiency issues, not in may have logic problems. How to efficiently write a SQL statement that replaces not exists?
Original sql statement
select colname … from A表 where a.id not in (select b.id from B表)
Efficient sql statement
select colname … from A表 Left join B表 on where a.id = b.id where b.id is null
The retrieved result set is shown in the figure below, the data in table A is not in table B

10. Use reasonable paging methods to improve the efficiency of paging
select id,name from table_name limit 866613, 20
When using the above sql statement for paging, someone may find that as the amount of table data increases, directly using limit paging query will become slower and slower.
The optimization method is as follows: you can take the id of the maximum number of rows on the previous page, and then limit the starting point of the next page according to this maximum id. For example, in this column, the largest id on the previous page is 866612. sql can be written as follows:
select id,name from table_name where id> 866612 limit 20
11. Segment query
In some user selection pages, some users may select a time range that is too large, causing slow queries. The main reason is too many scan lines. At this time, you can use the program, segment to query, loop traversal, and merge the results for display.
As shown in the following figure, this sql statement can use segmented query when the scanned rows are more than millions of levels.

12. Avoid the null value judgment of the field in the where clause
The judgment of null will cause the engine to give up using the index and perform a full table scan.
13. It is not recommended to use% prefix fuzzy query
For example, LIKE "%name" or LIKE "%name%", this kind of query will cause the index to fail and perform a full table scan. But you can use LIKE "name%".
How to query %name%?
As shown in the figure below, although an index is added to the secret field, the result of the explain is not used

So how to solve this problem, the answer: use full-text index
We often use select id, fnum, fdst from table_name where user_name like'%zhangsan%'; in our queries. For such statements, ordinary indexes cannot meet the query requirements. Fortunately, in MySQL, there is a full-text index to help us.
The sql syntax for creating a full-text index is:
ALTER TABLE `table_name` ADD FULLTEXT INDEX `idx_user_name` (`user_name`);
The sql statement that uses the full-text index is:
select id,fnum,fdst from table_name where match(user_name) against('zhangsan' in boolean mode);
Note: Before you need to create a full-text index, please contact the DBA to determine whether it can be created. At the same time, it should be noted that the difference between the query statement and the ordinary index
14. Avoid expression operations on fields in the where clause
such as
select user_id,user_project from table_name where age*2=36;
Arithmetic operations are performed on the fields in the middle, which will cause the engine to abandon the use of indexes, it is recommended to change to
select user_id,user_project from table_name where age=36/2;
15. Avoid implicit type conversion
The type conversion that occurs when the type of the column field in the where clause is inconsistent with the type of the passed parameter, it is recommended to determine the type of the parameter in the where
[Image upload failed...(image-bd63df-1553758116677)]
16. For the joint index, the leftmost prefix rule must be observed
For example, the index contains fields id, name, school, you can use the id field directly, or the order of id, name, but name; school cannot use this index. Therefore, you must pay attention to the order of the index fields when creating a joint index. Commonly used query fields are placed at the top
17. If necessary, you can use force index to force the query to go to an index
有的时候MySQL优化器采取它认为合适的索引来检索sql语句,但是可能它所采用的索引并不是我们想要的。这时就可以采用force index来强制优化器使用我们制定的索引。
18. Pay attention to the range query statement
For the joint index, if there is a range query, such as between, >, <and other conditions, the subsequent index fields will become invalid.
19. About JOIN optimization
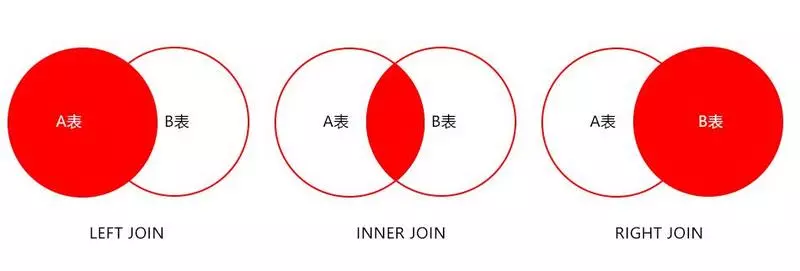
- LEFT JOIN A table is the driving table
- INNER JOIN MySQL will automatically find the table with less data to drive the table
- RIGHT JOIN B table is the driving table
Note: There is no full join in MySQL, you can use the following way to solve
select * from A left join B on B.name = A.name
where B.name is null
union all
select * from B;
Try to use inner join and avoid left join
There are at least two tables participating in the joint query, and generally there are differences in size. If the connection method is inner join, MySQL will automatically select the small table as the driving table without other filtering conditions, but the left join follows the principle of left driving right in the selection of driving table, that is, the table name on the left of left join For the driving table.
Reasonable use of indexes
The index field of the driven table is used as the restricted field of on.
Use small tables to drive large tables
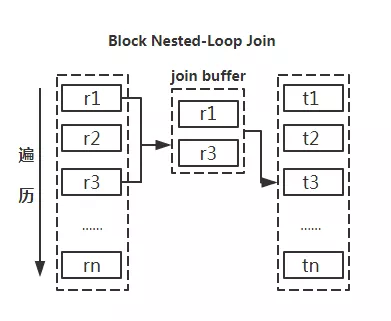
It can be seen intuitively from the schematic diagram that if the drive table can be reduced, the number of loops in the nested loop can be reduced to reduce the total amount of IO and the number of CPU operations.
Clever use of STRAIGHT_JOIN
Inner join is the driving table selected by mysql, but in some special cases, another table needs to be selected as the driving table, such as group by, order by, etc. "Using filesort" and "Using temporary". STRAIGHT_JOIN is used to force the connection order. The table name on the left of STRAIGHT_JOIN is the driving table, and the right is the driven table. A prerequisite for using STRAIGHT_JOIN is that the query is an inner join, which is an inner join. STRAIGHT_JOIN is not recommended for other links, otherwise the query results may be inaccurate.

This method may sometimes reduce the time by 3 times.
Only the above optimization schemes are listed here. Of course, there are other optimization methods. You can explore and try, thank you for your attention.