flex&bison installation and simple use
1.wls installation
Here is wls, wls installation tutorial can refer to this one , pro-test is available, it comes with gcc after installation, but there is no related dependency, you need to run the following two commands
sudo apt-get update
sudo apt-get install build-essential
You may encounter some problems, you can refer to the error solutions on the Internet~
2. Install flex bison and try the first flex program
Install flex bison under the Ubuntu system, enter the following command
sudo apt-get install flex bison
It will be installed in a while, and then we will try our first flex program ( feb1-1.l), which refers to the second edition of the Chinese version of flex and bison (you can buy it and have a look!)
%{
int chars = 0;
int words = 0;
int lines = 0;
%}
%%
[a-zA-Z]+ {
words++; chars+= strlen(yytext);}
\n {
chars++; lines++;}
. {
chars++;}
%%
main(int argc, char** argv){
yylex();
printf("%d,%d,%d\n", lines, words, chars);
}
This program is C code, flex program contains three parts, each part is divided by %% lines
- The first part is the declaration part. The code between %{ and }% will be copied to the beginning of the generated C file as it is. In the chestnut above, we use variables that set the number of lines, word books, and characters
- The second part is the pattern matching part. Students who have learned regular expressions will definitely not be unfamiliar with them (regular expressions will not be introduced in detail here~). The beginning of each line corresponds to a pattern (represented by a regular expression) ), followed by the C language code that will be executed when the pattern is matched ( variable yytext is always set to point to the text entered in this match)
- The third part is our main program, which is responsible for calling the lexical analysis routine yylex() used by the flex body and outputting the result. In the absence of other changes, the lexical analyzer will read standard input.
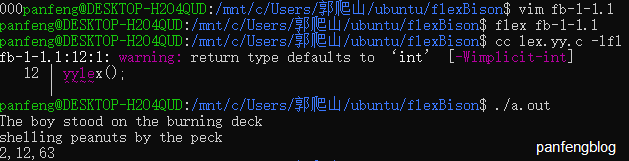
We first compile flex to generate C programs ( lex.yy.c)
flex fb-1-1.l
Then link it with the corresponding flex library file (-lfl) to generatea.out
cc lex.yy.c -lfl
Finally run the program
./a.out
Try to enter the following:
The boy stood on the burning deck
shelling peanuts by the peck
The output is (number of lines, number of words, number of characters)
2,12,63
Some instructions for flex regular expression matching:
- Default greedy match (matches longer strings)
- Match the first pattern in the program first
3. Let Flex and Bison work together
We now need to complete a simple calculator
First use to write a simple flex lexical analyzer, which does not display the definition token value, but directly includes the header file, because we want to call it directly in the syntax analyzer
File name: fb-1-5.l
%{
#include"fb-1-5.tab.h"
int yylval;
%}
%%
"+" {
return ADD;}
"-" {
return SUB;}
"*" {
return MUL;}
"/" {
return DIV;}
"|" {
return ABS;}
[0-9]+ {
yylval = atoi(yytext); return NUMBER;}
\n {
return EOL;}
[ \t] {
return EOL;}
. {
printf("Mystery character %c\n", *yytext);}
%%
Then the bison program part, the bison rule is basically BNF (refer to the compilation principle), the bison program is divided into three parts like flex:
- The first part is also a declaration first, and will be copied to the beginning of the target program, followed by the %token mark declaration to tell bison the token name in the parsing
- The second part is the rules defined by BNF, using a single colon: it means that, like flex, after matching each rule, the action code enclosed in curly braces will be executed . We generally use the action code to maintain the corresponding grammar Symbols are associated with semantic values. The value of the target symbol is represented by $$ in the action code, and the semantic value of the grammatical symbol on the right is $1, $2... until the end of this rule. The token value is always stored in yyval, which corresponds to our flex program above.
- The third part is the main program, which runs our syntax analysis program.
File name: fb-1-5.y
%{
#include<stdio.h>
%}
%token NUMBER
%token ADD SUB MUL DIV ABS
%token EOL
%%
calclist:
| calclist exp EOL {
printf("=%d\n", $2);}
;
exp: factor
| exp ADD factor {
$$ = $1 + $3;}
| exp SUB factor {
$$ = $1 - $3;}
;
factor: term
| factor MUL factor {
$$ = $1 * $3;}
| factor DIV term {
$$ = $1 / $3;}
;
term:NUMBER
| ABS term {
$$ = $2 >= 0? $2 : -$2;}
;
%%
main(int argc, int **argv){
yyparse();
}
yyerror(char *s)
{
fprintf(stderr, "error:%s\n", s);
}
Then jointly compile the flex and bison programs. Since the compilation steps are more complicated, we write a Makefile, run it vim Makefile, and write the following
fb-1-5:fb-1-5.l fb-1-5.y
bison -d fb-1-5.y
flex fb-1-5.l
cc -o $@ fb-1-5.tab.c lex.yy.c -lfl
Then we compile:
make
Get the program fb-1-5, just run it directly, a simple calculator is complete~
