Requests to say today about the module to crawl Web content decoding mode
The difference is response.text and response.content
First of all to climb to get to find the page on the web page coding
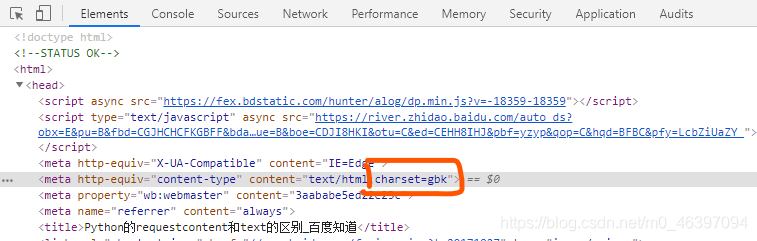
Get coding web pages can continue to write code for it
1. Use content output
print(response.content.decode('utf-8')) #decode('utf-8')的意思是以utf-8的编码的方式解码为Unicode2. Using text output
response.encoding = 'utf-8' #为请求的网页指定该网页的编码方式,这样text输出的时候,就不会瞎猜编码方式,而解出乱七八糟的鬼
print(response.text)Reference code (response above are from the inside to the reference code)
import requests
kw = {'wd':'巴基斯坦'}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# params 接收一个字典或者字符串的查询参数,字典类型自动转换为url编码,不需要urlencode()
#这就是requests库的其中一个方便的地方
response = requests.get("http://www.baidu.com/s", params = kw, headers = headers)
# 查看响应内容,response.text 返回的是Unicode格式的数据
print(response.text)
# 查看响应内容,response.content返回的字节流数据
print(response.content)
# 查看完整url地址
print(response.url)
# 查看响应头部字符编码
print(response.encoding)
# 查看响应码
print(response.status_code)
Some see here have doubts, then I use print (response.encoding) to view the encoding of web pages
Then again not decode it? ? ? Why not? ? ? Why not? ? ? (You say you are not able to get my spasms)
Answer: Of course it is OK ha ha ha ha ha ha (so this is a big egg, so there are two ways to get to the page encoding it)
But sometimes it may be wrong: for example climbing Baidu with print (response.encoding) get is a single-byte ISO-8859-1 encoding
But I went to the Baidu website Press F12 to view indeed 'utf-8' encoding, then I determined to use utf-8 decoding, because the single-byte code can not be represented Chinese Oh!
So sometimes goes wrong, you can try these two methods (currently I know is that these two friends, because I was a white)
All of them are love brains hotties ..... hee hee hee hee (say so do not give me "like"?)
----------------------------------------------------------------------------------------------
Of course, someone will ask you, this code breaking things do not quite understand, can you help me sort sort
Ha ha ha ha ha ha, give me some more praise praise praise praise
Knowledge big run:
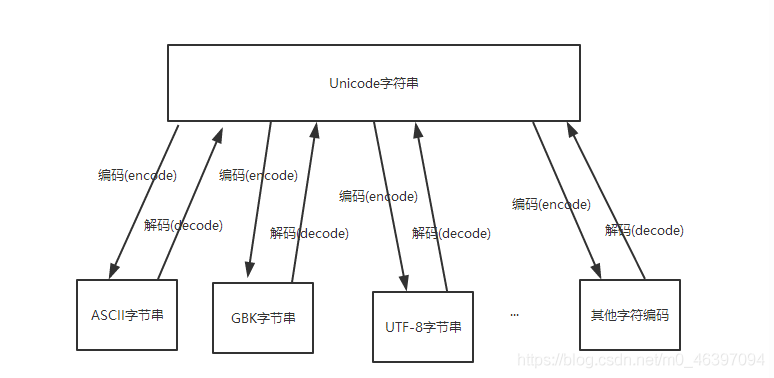
encode () and decode () and mean difference
English decoding means decode, encode English meaning is coded
Python string representation is internally unicode encoding , therefore, when doing transcoding, as typically required in order to unicode intermediate code , that is, first decoding other encoded string (decode) into unicode, and from unicode encoding (encode) to another encoding.
Action is to decode the encoded character string converted into another unicode encoding, such as str101.decode ( 'utf-8'), shows a conversion utf-8 encoded string of bytes to unicode encoding str101
The role is to encode unicode string encoded into other coding, such as str101.encode ( 'gb2312'), indicates to convert the unicode string str101 encoded into encoded gb2312
This means it is almost ha ha ha ha ha
Finally, offer a treasure map (helpful to you handsome Way, remember to give me a set of praise ah)