Python crawler: advanced requests
Handle cookies
Generally speaking, the cookies we have to deal with need to log in. The process is that after the client logs in, it gets the cookie returned by the server, and then takes the cookie to request the url to get the relevant content. Therefore, the above two operations need to be connected, and the session can be used to make the request. A session can be considered as a series of requests, and cookies will not be lost during this process.
use session
import requests
# 会话
session = requests.session()
data = {
#填网页抓取后需要登陆的登陆参数名,比如
#“loginname”:"password"
}
#登录
url = ""
session.post(url,data=data)
#上面的session中是有cookie的
resp = session.get("XXXXX") # XXXX表示存储数据的请求网页,需要在开发者模式下的network中寻找相关数据
use cookies
Another way is not to use session. After logging in to the web page, obtain the cookie value of the requested page in developer mode, and add it to the headers for request.
import requests
resp = requests.get("XXXX",headers={
"Cookie":"XXXXXXXXX"
})
Use anti-leech to handle some anti-climbing
Anti-leech: It can be considered as traceability, who is the current upper level of the request. Referer anti-leeching is based on obtaining the referer header in the HTTP request, tracking the source according to the referer, and identifying and judging the source.
Example: Grab pear video
1. Analyze the source code, and find a srcurl at runtime. In fact, this srcurl is not the real address of the video, so we need to consider further. 2. Observation of customs
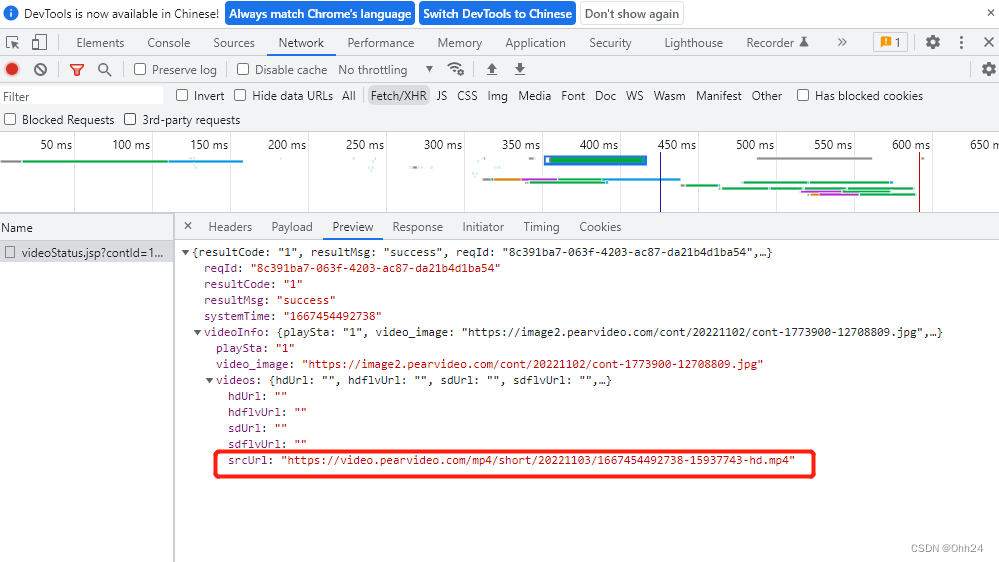
clearance shows that the real url address is to remove the first half of the last address and add systemtime The string "content" and the last part of the url to open the video


Code:
#1.拿到contID
#2.拿到videoStatus返回的json -> srcURL
#3.srcUL中的内容进行修整
#4.下载视频
import requests
url = "https://www.pearvideo.com/video_1773900"
contID = url.split("_")[1]
videoStatusUrl = "https://www.pearvideo.com/videoStatus.jsp?contId=1773900&mrd=0.3066916683965706"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
#防盗链
"Referer": "https://www.pearvideo.com/video_1773900"
}
resp = requests.get(videoStatusUrl,headers=headers)
dic =resp.json()
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime,f"cont-{contID}")
#下载视频
with open("a.mp4",mode="wb") as f:
f.write(requests.get(srcUrl).content)
proxy (deprecated)
proxies = {
"https": "https://XXXXXX"
}
requests.get("XXXXXX",proxies=proxies)