1. The following are the parameters of all the methods in the python source code. There are many methods included, but we cannot use them all. Here I will use some parameters that I often use based on my own experience. to explain.
defrequest(method, url,**kwargs):"""Constructs and sends a :class:`Request <Request>`.
:param method: method for the new :class:`Request` object: ``GET``, ``OPTIONS``, ``HEAD``, ``POST``, ``PUT``, ``PATCH``, or ``DELETE``.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary, list of tuples or bytes to send
in the query string for the :class:`Request`.
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
object to send in the body of the :class:`Request`.
:param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
:param headers: (optional) Dictionary of HTTP Headers to send with the :class:`Request`.
:param cookies: (optional) Dict or CookieJar object to send with the :class:`Request`.
:param files: (optional) Dictionary of ``'name': file-like-objects`` (or ``{'name': file-tuple}``) for multipart encoding upload.
``file-tuple`` can be a 2-tuple ``('filename', fileobj)``, 3-tuple ``('filename', fileobj, 'content_type')``
or a 4-tuple ``('filename', fileobj, 'content_type', custom_headers)``, where ``'content-type'`` is a string
defining the content type of the given file and ``custom_headers`` a dict-like object containing additional headers
to add for the file.
:param auth: (optional) Auth tuple to enable Basic/Digest/Custom HTTP Auth.
:param timeout: (optional) How many seconds to wait for the server to send data
before giving up, as a float, or a :ref:`(connect timeout, read
timeout) <timeouts>` tuple.
:type timeout: float or tuple
:param allow_redirects: (optional) Boolean. Enable/disable GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD redirection. Defaults to ``True``.
:type allow_redirects: bool
:param proxies: (optional) Dictionary mapping protocol to the URL of the proxy.
:param verify: (optional) Either a boolean, in which case it controls whether we verify
the server's TLS certificate, or a string, in which case it must be a path
to a CA bundle to use. Defaults to ``True``.
:param stream: (optional) if ``False``, the response content will be immediately downloaded.
:param cert: (optional) if String, path to ssl client cert file (.pem). If Tuple, ('cert', 'key') pair.
:return: :class:`Response <Response>` object
:rtype: requests.Response
Usage::
>>> import requests
>>> req = requests.request('GET', 'https://httpbin.org/get')
>>> req
<Response [200]>
"""# By using the 'with' statement we are sure the session is closed, thus we# avoid leaving sockets open which can trigger a ResourceWarning in some# cases, and look like a memory leak in others.with sessions.Session()as session:return session.request(method=method, url=url,**kwargs)
2. Query parameters
1. I just give an example here, for example, a website is as follows
2. In this kind of URL address here. ? in front ofurl. BackBinary numbers are query parameters。
3. Of course, this kind of query parameters can also be constructed through keyword parameters. For example, the meaning of the following two codes is the same.
4. Of course, you must have noticed how the value of the query has changed. In fact, it has not changed. It just has different names in different places. This is because of the url encoding: DefaultChinese characters are not supported in the http protocol, and will be automatically url-encodedHis components:%letter and number.
3. Request parameters (the request sent by post can only be viewed with code, and cannot be found directly on the web page)
1. When we send post requests, we often use this construction method. For example, when we send dynamic data, here I take KFC as an example.
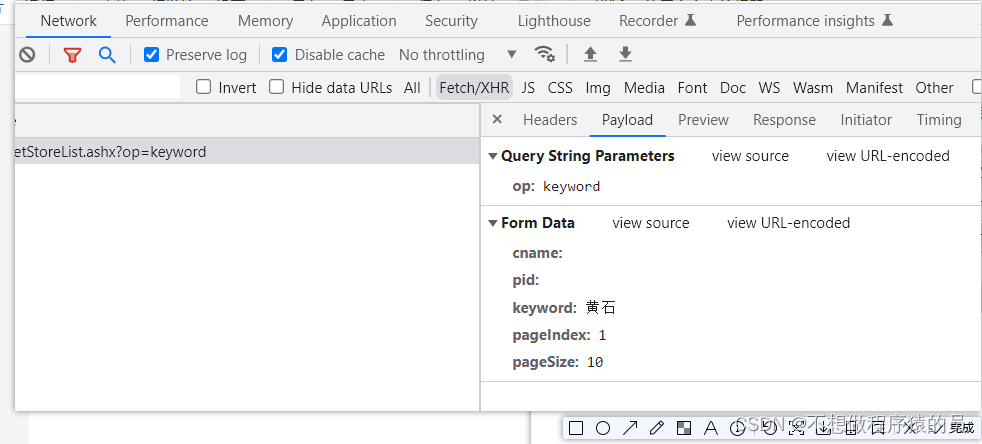
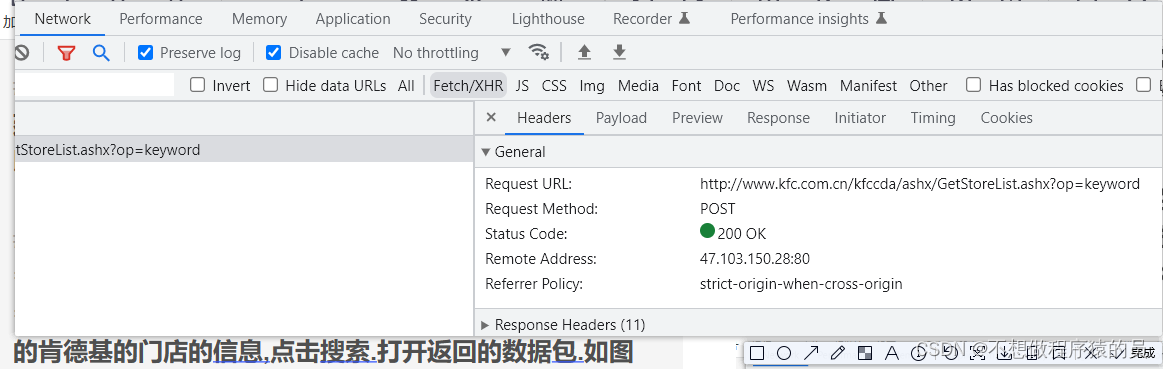
2 First, we open the official website of KFC, click therestaurant search, and then open the developer toolbar first, clickNetwork, and then clickFetch/XHRThen go to the input box to enter the information of the KFC store in the place you want to query, click Search. Open the returned data package. As shown in the figure
3. Form Data is the information of the returned request parameters, we use data to build, the following is the code, the code is the most direct way.
1. This is the parameter for building an agent. In our later learning process, we will face the risk of IP being blocked. At this time, we will use other people's IP to obtain data.