A, Impala and Hive relations
impala is based on the analysis of large data query engine hive, hive direct use of meta-database metadata, meaning impala metadata stored in metastore hive of them, and the vast majority of impala compatible hive sql syntax. So you need to install impala, it must be installed hive, hive to ensure a successful installation, and need to start hive of metastore service.
Hive metadata comprising meta information database, table, etc. created with Hive. Metadata is stored in a relational database, such as Derby, MySQL like.
Metastore service client connections, metastore go to connect MySQL database to access metadata. With metastore service, you can have multiple simultaneous client connections, and these clients do not need to know the MySQL database user name and password, only need to connect metastore the service.
nohup hive --service metastore >> ~/metastore.log 2>&1 &
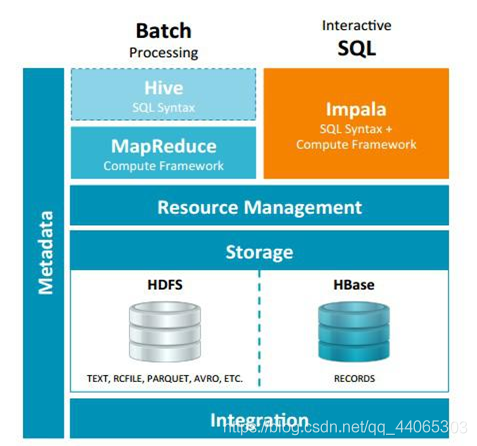
Hive suitable for long batch query and analysis, and the Impala is suitable for real-time interactive SQL queries. Hive can first use the data conversion process, after use Impala rapid data analysis on the results of the data set Hive treatment.
Two, Impala and Hive similarities and differences
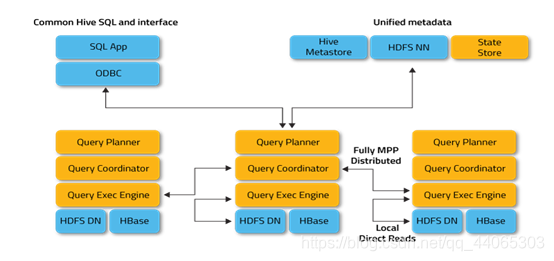
Hive Impala and data query tools are built on top of Hadoop vary to adapt to the focus, but the client uses the Impala view Hive have many in common, the data table metadata, ODBC / JDBC Driver, SQL syntax, flexible file format, storage resource pools.
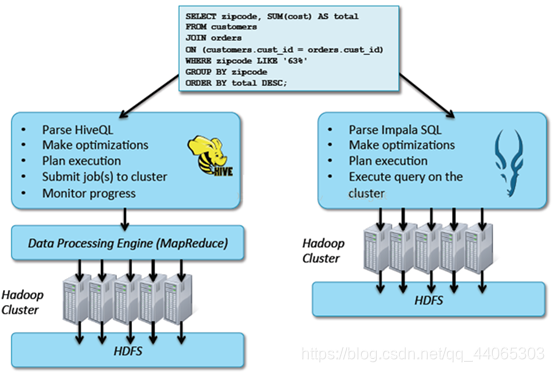
But the Impala with the biggest difference Hive optimization is: do not use MapReduce parallel computing , although MapReduce is a very good parallel computing framework, but it is more batch-oriented model, rather than for the interactive SQL execution. Compared with MapReduce, Impala put into a whole query execution plan tree , rather than a series of MapReduce tasks, after the implementation of the distribution plan, Impala use pull data acquisition methods get results, the results of data collection by passing the composition execution tree streaming , the step of reducing the intermediate results written to disk, and then read data from the disk overhead. Impala way to avoid using the services you need to start every query execution overhead, compared Hive that is not the MapReduce start time.
1, Impala optimization techniques used
Run the code generated using LLVM to generate specific code for a particular query, reduce the overhead of function calls while using Inline way to speed up the execution efficiency. (C ++ characteristics)
Full use of the available hardware instruction (SSE4.2).
Better IO scheduling, disk location where the data block Impala know better able to exploit the advantages of multi-disk, while Impala supports direct data block read and native code to calculate checksum.
The best performance can be obtained by selecting an appropriate data storage format (Impala supports multiple storage formats).
Maximum use of memory, intermediate results do not write the disk, timely delivery way to stream over the network.
2, the implementation plan
Hive : depends on the implementation of MapReduce framework, the implementation plan is divided into map-> shuffle-> reduce-> map->model. If a Query is compiled into several rounds of MapReduce, then there will be more to write intermediate results. Because the characteristics of the frame itself MapReduce performed, excessive intermediate process increases the overall execution time of the Query.
Impala : The Plan of Implementation of the performance of a full implementation plan tree can be more natural to distribute to various Impalad implementation plan to execute the query, but do not like the Hive as it combined into a pipeline type map-> reduce model, in order to ensure Impala better concurrency and avoid unnecessary intermediate sort and shuffle.
3, the data flow
Hive : using push manner, each computing node proactively pushed after completion of the calculation data to the subsequent node.
Impala : use pull mode, subsequent to the data node to the front getNext active node, in this way the data can be streamed back to the client, and as long as there is a data to be processed, can show up immediately, without waiting for all processing is complete, more in line with interactive SQL queries.
4, memory usage
Hive : during execution if the memory does not fit all the data, the external memory will be used to ensure complete Query can be performed sequentially. MapReduce end of each round, the intermediate results are also written in HDFS, MapReduce is also due to the characteristics of the execution architecture, shuffle process there will be a local disk write operations.
Impala : in the face does not fit the data memory, version 1.0.1 is the direct returns an error, without the use of external memory, future versions should be improved. This process is currently using the Query Impala were subject to certain restrictions, you is best used in conjunction with the Hive.
5, scheduling
Hive : task scheduling depends on the scheduling policy of Hadoop.
Impala : scheduling done by yourself, there is only one scheduler simple-schedule, it will try to meet local, process data scanned data as close to the physical machine where the data itself. The scheduler is still relatively simple, can be seen in SimpleScheduler :: GetBackend in, there is no consideration load, network status IO scheduling. But the Impala has statistical analysis of the performance of the implementation process, we should later will use these statistics to schedule it.
6, fault-tolerant
Hive : relies on Hadoop fault tolerance.
Impala : In the query process, no fault logic, if a failure occurs during execution, an error is returned directly (which is related to the design of the Impala, Impala because positioning in real-time queries, query was unsuccessful, and then check just once, and then check once the cost is very low).
7, applicability
Hive : complex batch query tasks, data conversion tasks.
Impala : real-time data analysis, because the problem does not support the UDF, can handle domain has certain limitations, in conjunction with the Hive, the result of the Hive data sets in real time analysis.
Three, Impala architecture
Impala mainly by Impalad , State Store , Catalogd and CLI composition .
1、Impalad
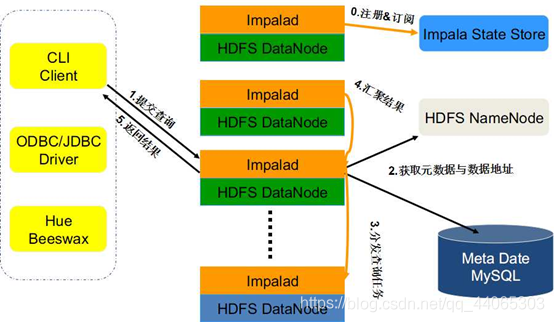
Impalad : and DataNode run on the same node, represented by Impalad process, it receives client queries ( receiving Impalad query request to Coordinator , Coordinator through the JNI call java explain SQL front-end query, generate a query plan tree, and then through the scheduler the distributed execution plan with the corresponding data of other Impalad execution ), read and write data, queries executed in parallel, and the results are transferred via the network back to the Coordinator stream, returned to the client by the Coordinator. Meanwhile Impalad also stay connected with the State Store, used to determine which Impalad is healthy and can accept the new job.
Start the three ThriftServer in Impalad: beeswax_server (connection client), hs2_server (borrow Hive metadata), be_server (Impalad internal use) and a ImpalaServer service.
2、Impala State Store
State Store Impala : health status and location tracking information Impalad cluster, represented by statestored process, it is registered to handle subscriptions and to maintain a heartbeat connection with the Impalad Impalad by creating multiple threads, each Impalad will be cached in a State Store the information, when the State Store offline (Impalad found State Store is offline, will enter recovery mode, repeatedly registered, when the State Store rejoins the cluster, automatically return to normal, update cached data) because Impalad have State Store cache can still be work, but because some Impalad fails, cached data can not be updated, resulting in the execution plan assigned to the Impalad failure, resulting query fails.
3、CLI
CLI: available to the user query command-line tool used (Impala Shell achieved using python), while Impala also offers Hue, JDBC, ODBC use interface.
4, Catalogd (directory)
Catalogd : As the access gateway metadata, metadata information acquired from other external Hive Metastore catalog, the catalog into impala their structure. When impalad ddl command execution on behalf of its execution by catalogd, the update by statestored broadcast.
Four, Impala query processing
Impalad into Java C ++ front-end and back-end processing, to accept Impalad client that is connected to analyze the user's query SQL execution plan tree as the query Coordinator, Coordinator calls the Java front end through JNI.
Java execution plan tree produced at the tip of the data format returns to the C ++ Thrift rear end (Coordinator) ( execution plan into a plurality of stages, each stage is called a PlanFragment each PlanFragment may, when executed by a plurality of Impalad parallel execution instance ( some PlanFragment only by a Impalad execution example, such polymerization operation) , the whole execution plan for an execution plan tree ).
Coordinator according to the execution plan, the data storage information ( Impala by libhdfs with HDFS interact hdfsGetHosts by obtaining the position information of the node where the method of data block file ), by a scheduler (now only simple-scheduler, using the round-robin algorithm) :: Coordinator Exec to generate the execution plan tree assigned to the appropriate back-end actuator Impalad execution (query using LLVM code generation, compile, execute), get results by calling the GetNext () method.
If the insert statement, the result will be calculated by libhdfs HDFS write back when all input data is depleted, the implementation of the end, after the cancellation of the query service.
