SeaweedFS is an efficient distributed file storage system. The earliest design prototype refers to Facebook's Haystack, which has the ability to quickly read and write small data blocks. This article will help readers make a more suitable choice by comparing the design and function differences between SeaweedFS and JuiceFS.
SeaweedFS system structure
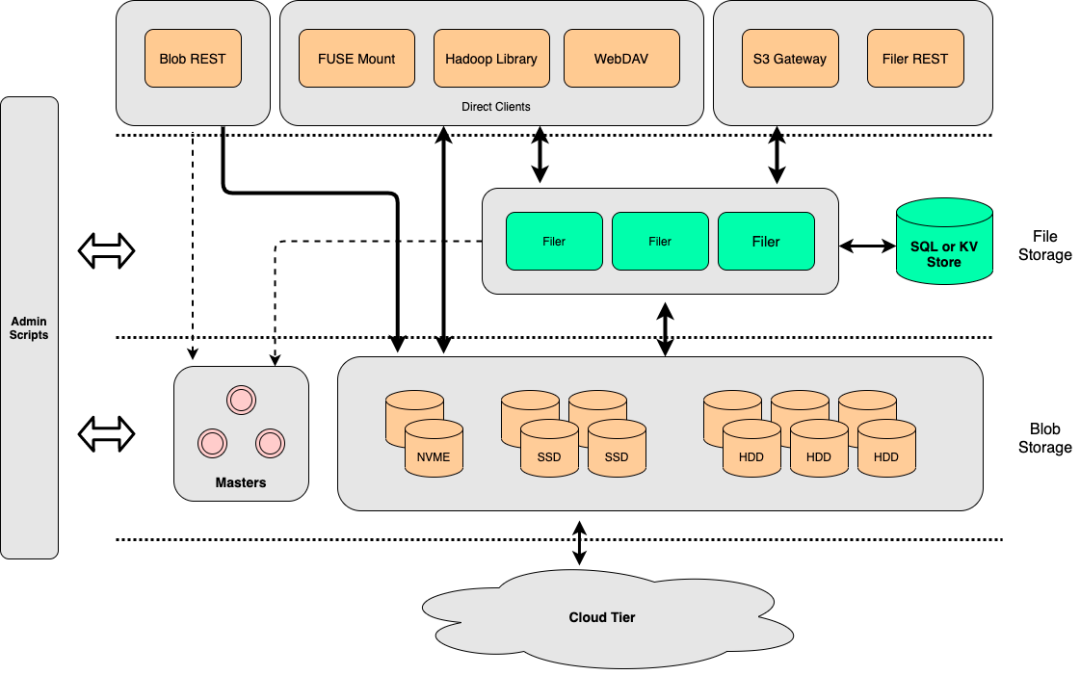
SeaweedFS consists of 3 parts, the Volume Server for underlying file storage, the Master Server for cluster management, and an optional Filer component that provides more features upwards.
Volume Server 与 Master Server
In terms of system operation, Volume Server and Master Server serve for file storage together. Volume Server focuses on data writing and reading, while Master Server tends to be a cluster and Volumes management service.
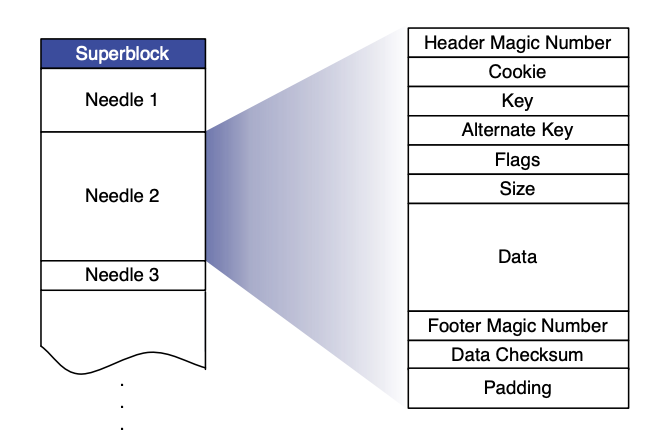
When reading and writing data, the implementation of SeaweedFS is similar to that of Haystack. A Volume created by the user is a large disk file (Superblock in the figure below). In this Volume, all files written by the user (Needle in the figure below) will be merged into this large disk file.
Before starting to write data, the caller needs to apply to SeaweedFS (Master Server), and then SeaweedFS will return a File ID (composed of Volume ID and offset) according to the current data volume. During the writing process, a And the basic metadata information (file length, Chunk and other information) is also written; when the writing is completed, the caller needs to associate and save the file and the returned File ID in an external system (such as MySQL) . When reading data, since the File ID already contains all the information for calculating the file position (offset), the content of the file can be read efficiently.
Filer
On top of the above-mentioned underlying storage unit, SeaweedFS provides a component called Filer. By connecting Volume Server and Master Server downward, it provides a wealth of functions and features (such as POSIX support, WebDAV, S3 interface, etc.). Like JuiceFS, Filer also needs to connect to an external database to save metadata information.
For the convenience of explanation, the SeaweedFS referred to below includes the Filer component.
JuiceFS system structure
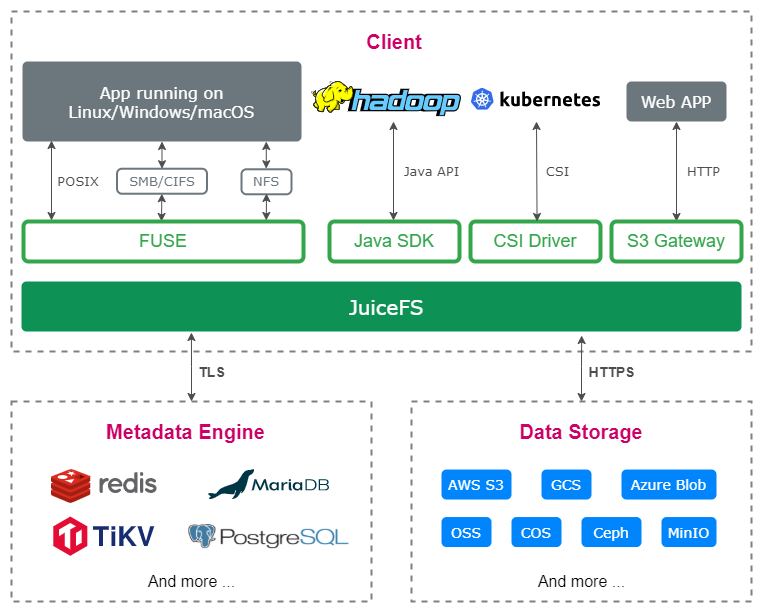
JuiceFS adopts a separate storage architecture for "data" and "metadata". The file data itself will be segmented and stored in object storage (such as Amazon S3), while the metadata will be stored in a database of the user's choice (such as Redis, MySQL). By sharing the same database and object storage, JuiceFS implements a distributed file system with strong consistency guarantee, and also has many features such as "full POSIX compatibility" and "high performance".
metadata comparison
Both SeaweedFS and JuiceFS support storing metadata information of the file system through an external database. In terms of database support, SeaweedFS supports up to 24 databases. JuiceFS has high requirements for database transaction capabilities (see below), and currently supports 3 types of transaction databases in total.
atomic operation
In order to ensure the atomicity of all metadata operations, JuiceFS needs to use a database with transaction processing capabilities at the implementation level. However, SeaweedFS only enables the transaction of some databases (SQL, ArangoDB and TiKV) when performing the rename operation, and has lower requirements for the transaction capability of the database. At the same time, since Seaweed FS does not lock the original directory or file when copying metadata during the rename operation, the updated data in the process may be lost.
changelog
SeaweedFS will generate a change log for all metadata operations, and this log can be further used for data replication (see below), operation auditing and other functions, while JuiceFS has not yet implemented this feature.
storage comparison
As mentioned above, the data storage of SeaweedFS is implemented by Volume Server + Master Server, which supports features such as "merged storage" and "erasure code" of small data blocks. The data storage of JuiceFS is based on the object storage service, and related features are also provided by the object storage selected by the user.
file split
When storing data, both SeaweedFS and JuiceFS will split the file into several small blocks and persist them to the underlying data system. SeaweedFS splits files into 8MB blocks, and for very large files (more than 8GB), it will also save the Chunk index to the underlying data system. JuiceFS is first disassembled into 64MB Chunk, and then disassembled into 4MB Object. Through the concept of an internal Slice, the performance of random write, sequential read, and repeated write is optimized. (For details, see Read Clearing Request Processing Flow )
Hierarchical storage
For newly created Volumes, SeaweedFS will store data locally, while for older Volumes, SeaweedFS supports uploading them to the cloud to separate hot and cold data . In this regard, JuiceFS needs to rely on external services.
data compression
JuiceFS supports using LZ4 or ZStandard to compress all written data, while SeaweedFS chooses whether to compress according to the extension and file type of the written file.
storage encryption
JuiceFS supports encryption in transit (encryption in transit) and encryption at rest (encryption at rest). When the user enables static encryption, the user needs to pass a self-managed key, and all written data will be based on this key. encryption. See " Data Encryption " for details.
SeaweedFS also supports encryption in transit and encryption at rest. After data encryption is enabled, all data written to the Volume Server will be encrypted with a random key, and the corresponding random key information will be managed by the "Filer" that maintains "metadata".
access agreement
POSIX Compatibility
JuiceFS is fully compatible with POSIX , while SeaweedFS is only partially POSIX compatible ( "Issue 1558" and Wiki ), and the function is still being improved.
S3 protocol
JuiceFS implements the function of S3 gateway through MinIO S3 gateway . It provides an S3-compatible RESTful API for files in JuiceFS, and can use s3cmd, AWS CLI, MinIO Client (mc) and other tools to manage files stored on JuiceFS when it is inconvenient to mount.
SeaweedFS currently supports about 20 S3 APIs, covering commonly used requests such as read, write, query, and delete, and has also made functional extensions for some specific requests (such as Read). For details, see Amazon-S3- API .
WebDAV protocol
Both JuiceFS and SeaweedFS support the WebDAV protocol.
HDFS Compatibility
JuiceFS is fully compatible with HDFS API . Not only compatible with Hadoop 2.x and Hadoop 3.x, but also compatible with various components in the Hadoop ecosystem. SeaweedFS provides basic compatibility with HDFS API , but does not yet support some operations (such as turncate, concat, checksum and extended attributes, etc.).
CSI driver
Both JuiceFS and SeaweedFS provide "Kubernetes CSI Driver" to help users use the corresponding file system in the Kubernetes ecosystem.
extensions
client cache
JuiceFS has a variety of client-side caching strategies, covering all parts from metadata to data caching, allowing users to tune according to their own application scenarios ( details ), while SeaweedFS does not have client-side caching capabilities.
Cluster data replication
For data replication between multiple clusters, SeaweedFS supports two asynchronous replication modes, "Active-Active" and "Active-Passive". Both modes achieve consistency between data in different clusters by passing the changelog and reapplying the mechanism For each changelog, there will be a signature information to ensure that the same modification will not be cycled multiple times. In the Active-Active mode with more than 2 nodes in the cluster, some operations of SeaweedFS (such as renaming directories) will be subject to some restrictions.
JuiceFS does not natively support data synchronization between clusters, and needs to rely on the metadata engine and object storage's own data replication capabilities.
Data cache on the cloud
SeaweedFS can be used as a cache for object storage on the cloud, and supports manual data preheating through commands. Modifications to cached data are asynchronously synchronized to object storage. JuiceFS needs to store files in object storage in chunks, and does not yet support caching acceleration for data already in object storage.
recycle bin
JuiceFS enables the recycle bin function by default, which will automatically move the files deleted by the user to the .trash directory under the JuiceFS root directory, and keep the data for a specified time before cleaning up the data. SeaweedFS does not support this feature yet.
Operation and maintenance tool
JuiceFS provides two sub-commands, juciefs stats and juicefs profile, which allow users to view the current or replay performance indicators for a certain period of time in real time. At the same time, JuiceFS also develops the metrics interface externally, and users can easily connect monitoring data to Prometheus and Grafana.
SeaweedFS realizes two ways of connecting Prometheus and Grafana at the same time , Push and Pull , and provides an interactive tool of weed shell to facilitate users to perform a series of operation and maintenance tasks (such as viewing the current cluster status, listing file lists, etc.).
other
-
In terms of release time, SeaweedFS was released in April 2015 and currently has a total of 16.4K stars, while JuiceFS was released in January 2021 and has a total of 7.3K stars so far.
-
In terms of projects, both JuiceFS and SeaweedFS adopt the more commercially friendly Apache License 2.0. SeaweedFS is mainly maintained by Chris Lu, while JuiceFS is mainly maintained by Juicedata.
-
Both JuiceFS and SeaweedFS are written in Go language.
comparison list
| SeaweedFS | JuiceFS | |
|---|---|---|
| metadata | multi-engine | multi-engine |
| Atomicity of metadata operations | not guaranteed | Guaranteed by database transactions |
| change log | have | none |
| data storage | Include | external service |
| erasure code | support | Rely on external services |
| data merge | support | Rely on external services |
| file split | 8MB | 64MB + 4MB |
| Hierarchical storage | support | Rely on external services |
| data compression | Supported (based on extension) | Support (global setting) |
| storage encryption | support | support |
| POSIX Compatibility | basic | whole |
| S3 protocol | basic | basic |
| WebDAV protocol | support | support |
| HDFS Compatibility | basic | whole |
| CSI driver | support | support |
| client cache | not support | support |
| Cluster data replication | Two-way asynchronous, multi-mode | not support |
| Data cache on the cloud | Support (manual sync) | not support |
| recycle bin | not support | support |
| Operation and maintenance tool | supply | supply |
| release time | 2015.4 | 2021.1 |
| main maintainer | Personal (Chris Lu) | Company (Juicedata Inc) |
| language | Go | Go |
| open source agreement | Apache License 2.0 | Apache License 2.0 |
If you are helpful, please pay attention to our project Juicedata/JuiceFS ! (0ᴗ0✿)