内存对齐
1、CPU 存取原理
CPU 并不是以字节为单位存取数据的。CPU把内存当成是一块一块的,块的大小可以是2,4,8,16字节大小,因此CPU在读取内存时是一块一块进行读取的。每次内存存取都会产生一个固定的开销,减少内存存取次数将提升程序的性能。所以 CPU 一般会以 2/4/8/16/32 字节为单位来进行存取操作。我们将上述这些存取单位也就是块大小称为(memory access granularity)内存存取粒度。
![]()
![]()
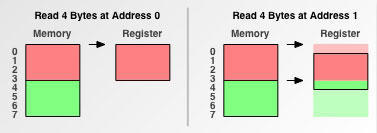
例如:在一个存取粒度为 4 字节的内存中,先从地址 0 读取 4 个字节到寄存器,然后从地址 1 读取 4 个字节到寄存器。
当从地址 0 开始读取数据时,是读取对齐地址的数据,直接通过一次读取就能完成。当从地址 1 读取数据时读取的是非对齐地址的数据。需要读取两次数据才能完成。
而且在读取完两次数据后,还要将 0-3 的数据向上偏移 1 字节,将 4-7 的数据向下偏移 3 字节。最后再将两块数据合并放入寄存器。
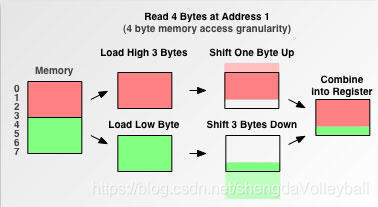
对一个内存未对齐的数据进行了这么多额外的操作,这对 CPU 的开销很大,大大降低了CPU性能。所以有些处理器才不情愿为你做这些工作。
内存对齐原则
1:数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第
一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要
从该成员大小或者成员的子成员大小(只要该成员有子成员,比如说是数组,
结构体等)的整数倍开始(比如int为4字节,则要从4的整数倍地址开始存
储。
2:结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从
其内部最大元素大小的整数倍地址开始存储.(struct a里存有struct b,b
里有char,int ,double等元素,那b应该从8的整数倍开始存储.)
3:收尾工作:结构体的总大小,也就是sizeof的结果,.必须是其内部最大
成员的整数倍.不足的要补齐。
例:
1、
struct StructTwo {
double b; //8字节
char a; //1字节
short d; //2字节 + 1
int c; //4字节
} MyStruct3;
b(8)最大是8,不足8的补齐。a(1)后面是d(2), 加起来是3,后面在有的话需要在2的倍数的起始位置开始也就是4。所以c(4)和a、d排在一起。
b(8) + [a(1)+d(2)+1+c(4)]= 16;
2、
struct StructTwo {
double b; //8字节
char a; //1字节
int c; //4字节 +3
short d; //2字节 +6
} MyStruct2;
MyStruct2
b(8),最大是8,不足8的补齐。a(1)后面是c(4), 加起来是5,后面在有的话需要在4的倍数的起始位置开始也就是8,满了。所以d(2)自己再补齐6。
b(8) + [a(1)+c(4)+3] + d(2)+6 = 24;
3、
struct StructTwo {
char a; //1字节
struct MyStruct2; //24字节 8-31
int c; //4字节 32-35
short d; //2字节 +2 36-37
} MyStruct3;
MyStruct3
MyStruct2 中的 b(8),最大是8,不足8的补齐。a(1) 后面 结构体所以a(1)自己补齐+7。 MyStruct2 结构体是24。 c(4) + d(2)=6 再补齐2。
[a(1)+7] + 24 + [c(4)+ d(2)+2] = 40;
4、
struct StructTwo {
int c; //4字节
} MyStruct4;
struct StructTwo {
char a; //1字节
struct MyStruct4; //4字节 8-31
int c; //4字节 32-35
short d; //2字节 +2 36-37
} MyStruct5;
MyStruct5
MyStruct4 中的 c(4),最大是4,不足4的补齐。同时要满足从4的整数倍开始排列。a(1) 后面 还有7字节,MyStruct4 从4字节开始排,同时自身是4字节,所以a(1)+3+ MyStruct4 =8。 c(4) + d(2)=6 再补齐2。
[a(1)+3+4] + [c(4)+ d(2)+2] = 16;
