感谢
感谢姜昱华同学的总结,本文是基于他的资料扩充而来的。
前言
本文挂一漏万,作者才疏学浅。如有错漏,欢迎指正;因此暴毙,概不负责。
软件测试的基本思想
首先,我觉得得整明白两件事。
第一个,测试的目的是什么?我觉得是尽早发现并修复bug以确保质量。
第二个,什么是bug?在这里我们不讨论所谓的“bug由测试定义”,我们只讨论出现什么情况之后可以认为有bug。一个认可度比较高的定义是这样:
1)软件未实现产品说明书要求的功能
2)软件出现了产品说明书指明不应该出现的错误
3)软件实现了产品说明书未提到的功能
4)软件未实现产品说明书虽未明确提及但应该实现的目标
5)软件难以理解、不易使用、运行缓慢或者从测试员的角度看最终用户会认为不好
我概括了一下,大概就三点:做多了(实现了额外功能),做少了(没做必须做的功能,没做应该做的功能),做歪了(出现了不能出现的问题,用户觉得不好)。
可以看到,测试是基于文档的质量保障措施。哪怕软件出现了不符合常识的行为,只要文档上说这是功能,那就是功能。后面我们会基于这个假设进行讨论,并且我们也能感觉到,文档是贯穿整个软件测试的,甚至可以说,软件测试就是输入一份文档输出另一份文档的过程,而自动化测试大概就是把这个生成文档的过程交给机器去做了。
给一个相对“官方”的定义:
自动化测试就是把以人为驱动的测试行为转化为机器执行的一种过程。
软件生命周期
- 计划(其实就是立项)
- 问题定义
- 可行性研究
- 需求
- 设计
- 体系结构设计
- 详细设计
- 构造
- 编码
- 构建
- 集成
- 测试
- 交付
- 安装
- 部署
- 维护
可以看到,这是一个完整的瀑布过程,对应于软件测试的V模型,也就是业务需求-系统需求-体系结构设计-详细设计-编码-单元测试-集成测试-验收测试这么一个过程,构成了一个V字形。
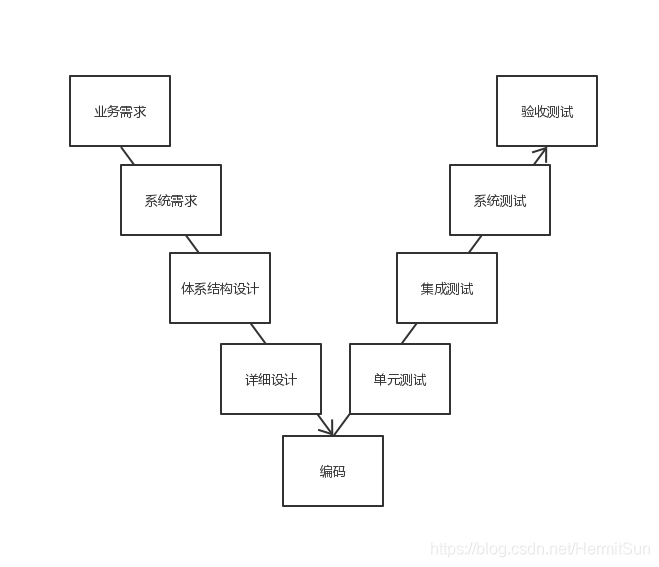
这是我调整之后的V模型,我不认同市面上的那种编码和单元测试对应的图,编码应该是一个独立的过程。我们前面说了,测试是输入文档输出文档的过程,代码又不是文档,哪来的一一对应关系。
这个模型的优点很明显,流程清晰,体现出了层次关系和对应关系,并且强调了测试的重要性。但是缺点更明显,因为是类似于瀑布模型的过程,是一个串行的过程,每一个阶段完全依赖于上一个阶段,这也就意味着对需求和设计的测试和验证会被推迟,而到那个时候再改就来不及了。我甚至可以说,这个模型违背了测试尽早发现并修复bug这个基本的要求。并且由于是串行的,完全不支持迭代和并行,也难以应对变更。同时,因为这种先后的依赖关系,每一阶段对上一阶段的文档要求都很高(别忘了我们对测试的“定义”),而通常情况下因为时间紧都会忽略文档的问题(或者到最后疯狂补文档,相信各位都有这样的经历),直接影响下一阶段的测试活动的正常进行。基本上瀑布模型有什么问题,这个V模型就有什么问题。
后来为了解决发现需求和设计上的问题太迟的问题,就整了一个W模型。这个W模型是把两个V叠在一起,第一个V是软件的生命周期,第二个V是软件的测试过程,对生命周期的每一个阶段都进行的验证和测试。这个的优点就是解决了之前的问题,从一开始就进行测试,能够满足尽早发现并修复bug的要求。但是整个流程还是瀑布式的,仍然存在不能迭代、不能并行、难以变更和对文档要求高的问题。
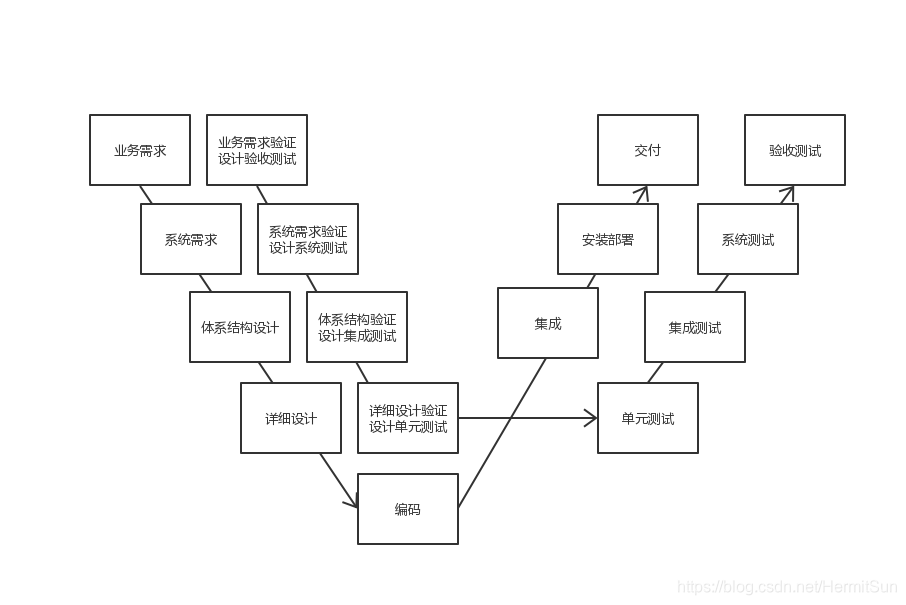
不知道你有没有觉得不妥,反正我是觉得不妥,因为测试放在哪里都感觉怪怪的。当然那些大师们早就想到了,所以他们最后把测试分离出来,作为一个独立于软件的开发活动,并且形成了H模型,理论上解决了这些问题。至于H模型好不好用么……
(图片来自百度百科,为了不影响图片内容去掉了水印)
软件测试的技术与过程
测试的关键活动
测试需求、测试计划、测试用例设计、(测试自动化)、测试执行、测试评审和总结
可以发现,这个是和开发活动一一对应的。
一图胜千言,这张图的概括真的很好。
测试的质保手段
别忘了软件开发的质保手段:评审、测试、度量。
相应的,测试的质保手段是指定测试计划(准备)、测试过程中进行数据分析和度量(度量)、测试之后进行评审和总结(评审)、回归测试(再次测试)。
持续的软件测试
我印象中的持续集成
开发人员提交代码,测试人员提交用例到版本控制服务器上,然后版本控制服务器通知(或者说触发吧)CI服务器进行构建、测试并且生成测试结果,然后测试人员拿到测试结果进一步精化形成测试报告给予反馈。
开发和测试的持续集成通过在完成所有开发之后替换传统的测试实践,来提高软件质量并减少交付耗时。它允许开发团队尽早检测和定位问题,因为开发人员需要每天(或更频繁地)将代码集成到代码仓库中,然后自动验证每次集成。
一些更加详细的解释
可以阅读理想化的DevOps流程,作者季长冰。读了几篇感觉他这个最好。
软件测试中的若干问题
诸如verification(验证)和validation(确认)的区别之类的名词解释不在这里赘述。
边界值测试
边界值分析
健壮性测试
最坏情况测试
特殊值测试
随机测试
静态测试
静态测试
什么是静态测试?不执行代码。动态测试呢?执行代码。
代码审查和走查
审查较正式,逐行读代码,并且需要形成报告;走查非正式,借助用例模拟程序执行过程,记录发现的问题
内容
基于需求、基于设计、基于代码
结构性测试
按照结构化程序设计的理论,程序只有三种控制结构:顺序、循环、分支。而在我看来,循环是给程序重复进行顺序执行的能力,顺序执行本身又不需要进行特殊处理(我们只需要按照语句的先后顺序来执行就行了),所以在结构覆盖上,我们需要着重关注的是对分支结构的覆盖。
事实上,我感觉程序的复杂度是取决于分支结构的数量的,至少在图上是这样;分支越多,圈复杂度越高。
图覆盖
VC:顶点覆盖(0-PC)
EC:边覆盖(1-PC)
因为DC要求遍历每条分支,所以EC和DC其实是等价的。
EPC:边对覆盖(2-PC,覆盖所有长度为2的路径)
核心是要找到所有的判定结点和循环体,并且全部覆盖。比如,在下面这张图中:
我们需要注意TR = { [1,3,4], [1,3,5], [2,3,4], [2,3,5], [3,5,6], [3,5,7], [5,6,5], [6,5,6], [6,5,7] }的情况。也就是覆盖了判定结点3、5和循环体6(循环的始结点5被我放进了判定结点里)。
n-PC:n路径覆盖(覆盖所有长度为n的路径)
CPC:全路径覆盖(∞-PC)
主路径覆盖
主路径的出现是为了解决图中的环路(loop)问题。因为如果有环路,路径数目是无限的,CPC就无法实现。
简单路径(simple path):没有重复结点的路径,或者环路。如果是环路,又叫做Round-Trip Path往返路径。
A path from node ni to nj is simple if no node appears more than once, except possibly the first and last nodes are the same.
主路径:最长的简单路径
A simple path that does not appear as a proper subpath of any other simple path.
PPC主路径覆盖:覆盖图中所有的主路径。
PPC和EPC不等价,也没有什么包含关系。因为,对于一个指向自己的结点v和旁边直接相连的结点v’来说,EPC会覆盖[v, v, v’],但PPC不会,因为[v, v, v’]并不是一条主路径,甚至连主路径都不是。
主路径的特点,始点是入口、循环头、循环体,终点是出口、循环头、循环体。一般来说,只要让每个循环执行0次、1次和2次(然后进行排列组合),就能实现主路径覆盖。
基本路径覆盖
独立路径independent path:包含和其他路径不相同的顶点或边的路径。
A path through the system is independent from other paths only if it includes some vertices or edges that are not covered in the other path.
圈复杂度CC = E - V + 2,或者判定结点数量 + 1。
对于无环图来说,圈复杂度CC = E - V + P,P为图中的组件数(组件就是图中每一个连通的部分);而对于有向图来说,圈复杂度CC = E - V + 2P。
因为通常来说,一段代码转换成的有向图只有一个组件,所以直接就是E - V + 2了。
根据圈复杂度确定基本路径的集合(路径数目 === 圈复杂度CC,也就是说这个集合的大小等于圈复杂度)。集合内的路径对应的矩阵应当线性无关(否则就可以互相表示)。
逻辑覆盖
第一篇文章写的时间有点久了,可能会有错误,欢迎指正。
移动应用测试
特点
- 网络多样:2G到5G,还有WLAN
- 手势操作:而不是点击
- 易被中断:电话、短信、断电、锁屏
- 迭代快:经常更新
- 碎片化与兼容性:品牌、传感器、屏幕、定制、界面、系统
- 终端性能:耗电量、CPU、帧率
问题
- 碎片化带来的兼容问题:传感器、屏幕、各品牌定制的系统和界面
- 用户容忍度低(也算是一个嵌入式的实时设备吧),更关注终端性能和易用性
- 工具链不完善,模拟器环境和真实环境不同,导致自动化程度相对较低
深度遍历
按照树状结构,自动遍历APP所有控件覆盖各种异常分支
众包测试
测试人员利用互联网把测试工作分配出去——有一群人有专业的知识和能力完成测试工作并提交给测试人员——测试人员检查后验收
移动应用自动化
前提
- 需求变动不频繁
- 项目周期足够长
- 自动化测试脚本可重复使用
- 测试对象能尽可能的被自动化
优点
- 提高测试效率和降低测试成本
- 实现快速的回归测试、加快测试进度从而加快产品发布进度
- 更多的测试,提高测试覆盖率
- 保证一致性
- 提高测试的可靠性,避免人为因素
缺点
时间周期长,对测试人员技术要求高
常见框架
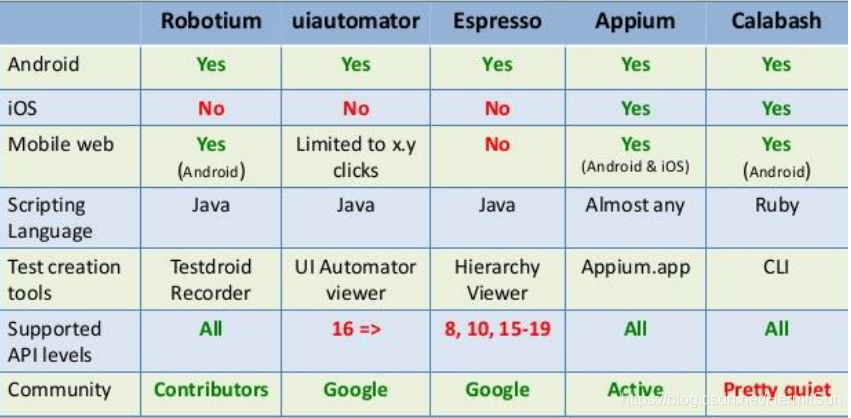
实践
内容和优化策略
α测试和β测试
α(开发环境)β(真实用户环境)
都是验收测试
控制方式
机械臂控制、硬件信号仿真、软件控制
脚本录制的实现原理
脚本录制 + 回放,可以了解一下LIRAT,基于定位和图像识别的自动化测试系统。
任务
这里说说缺陷报告自动化生成。
背景
- 自动化测试成为主流
- 自动化测试优势明显
- 效率高
- 批量处理
- 可重复执行
- 人工审核日志效率低
- 重复劳动
- 同样的缺陷,不同的表达方式
- 定位和复现错误难
- 可读性差,分析不深入
- 没有上下文难以复现
任务
- 提高报告可读性
- 定位缺陷,构建缺陷模型
- 操作截图
- 性能参数
- 堆栈信息
- 测试路径
- 缺陷分类、去重
在整个生命周期中的地位
生成测试报告,也就是在测试的最后的总结评估阶段了。
AI测试
两个性质
可迁移性:找bug
(对抗样本带来的)鲁棒性:修bug
我还是喜欢“健壮性”这个名词。
三种范数
0范数:0的个数
2范数:平方和开根号
无穷范数:max
四种类型
白盒定向、白盒非定向、黑盒定向、黑盒非定向
了解(不了解)模型结构,指定(随机)类别攻击
