首先,写上总结:
- select中部分常见错误 和 知识点:
- 当like后面匹配的字符串中不含有 通配字符时候,like 可以用 = 来替换。
- 匹配字符时候,’_'这个字符代表 一个字符(任意的一个),‘ %’代表任意个字符。
- '%‘使用时,可以代表0个字符,而’_'代表一个字符,并且至少要有一个字符与之对应。
- 不能用 = 来判断 NULL 值, NULL值在排序时候被当作最小的值来处理
- 聚合不能出现在where子句中,除非该聚合位于 HAVING 子句或选择列表所包含的子查询中,并且要对其进行聚合的列是外部引用。
在写之前我们看一下用到的表的结构和数据:

Course表如下:

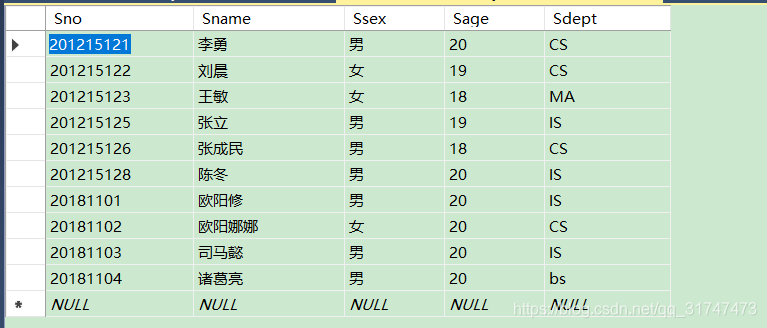
Student表如下:
SC表如下:

[例3.29] 査询学号为201215121的学生的详细情况。
这里我们用两种方法来写,代码如下:
--图中第一条结果
select * from Student where Sno like '201215121';
--图中第二条结果
select * from Student where Sno = '201215121';
结果如下图(结果相同):
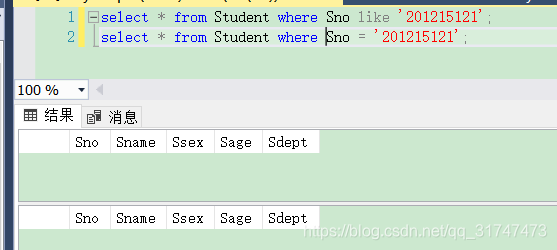
那么什么时候都可以用这两种方法吗?当 like 后面的匹配串中不含有通配符号,可以用 = 代替 like ,用 != 或 <> 运算符取代not like
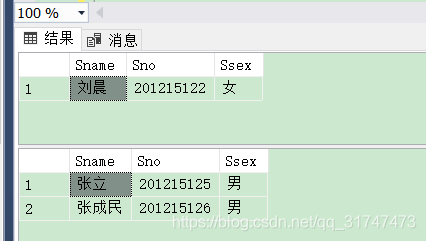
[例3.30] 査询所有姓刘的学生的姓名、学号和性别.
在此同时查询了姓张的同学来确保正确性,代码如下:
--图中第一条结果,姓刘的同学
select Sname, Sno , Ssex from Student where Sname like '刘%';
--图中第二条结果,姓张的同学
select Sname, Sno , Ssex from Student where Sname like '张%';
结果如下图:
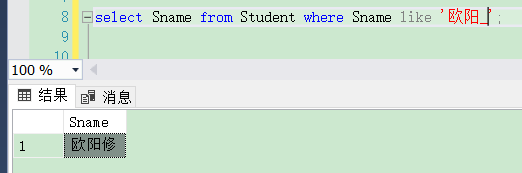
[例3.31] 査询姓“欧阳”且全名为三个汉字的学生的姓名.
代码如下:
select Sname from Student where Sname like '欧阳_';
结果如下图:
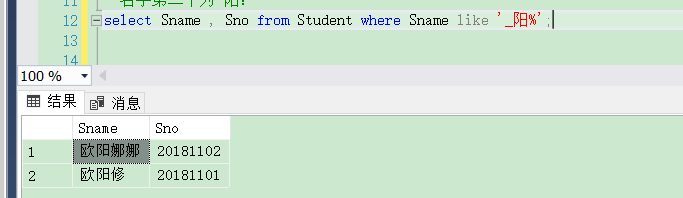
[例3.32] 査询名字中第二个字为“阳”的学生姓名和学号。
代码如下:
select Sname , Sno from Student where Sname like '_阳%';
结果如下图:
[例3.33] 査询所有不姓刘的学生的姓名、学号和性别。
代码如下:
select Sname , Sno , Ssex from Student where Sname not like '刘%';
结果如下图:

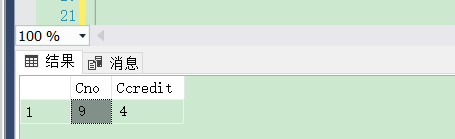
[例3.34] 査询DB_Design课程的课程号和学分。
代码如下:
select Cno , Ccredit from Course where Cname like 'DB\_Design' escape'\';
结果如下图:
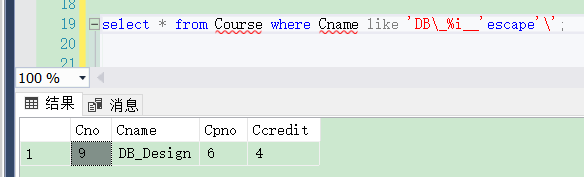
[例3.35] 查询以“DB_”开头,且倒数第三个字符为i的课程的详细情况。
代码如下:
select * from Course where Cname like 'DB\_%i__'escape'\';
结果如下图:
[例3.36] 某些学生选修课程后没有参加考试,所以有选课记录,但没有考试成绩。査询缺少成绩的学生的学号和相应的课程号。
我们在这里测试一下能不能用 = 来判断 null ,代码如下:
select Sno , Cno from SC where Grade is null;
--用等号判断null:
select Sno , Cno from SC where Grade = null;
结果如下图:
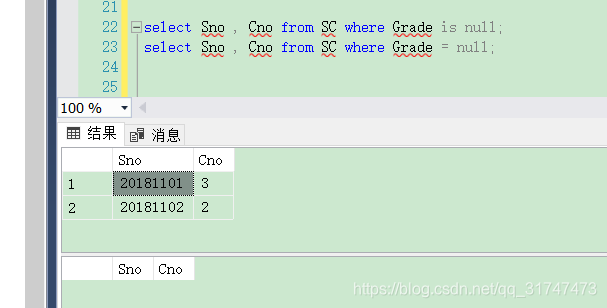
显然,不能用 = 来判断 NULL 值。
[例3.37] 査所有有成绩的学生学号和课程号。
是否能用 != 来判断null值呢?代码如下:
select Sno , Cno from SC where Grade is not null;
-- 用!= 来判断(不可以)
select Sno , Cno from SC where Grade != null;
结果如下图:
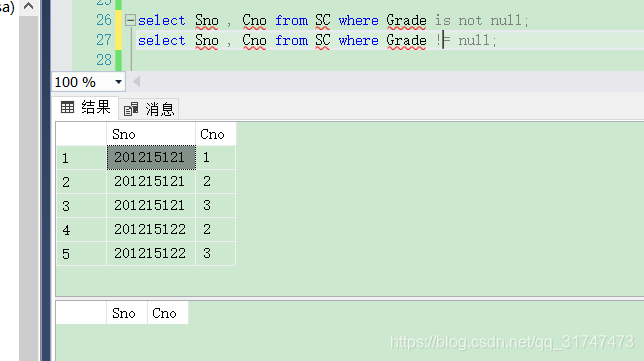
显然,也不可以用 != 来判断NULL值。
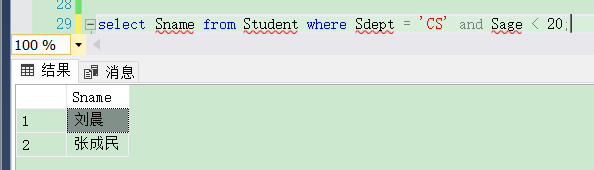
[例3.38] 查询计算机科学系年龄在20岁以下的学生姓名。
是否能用 != 来判断null值呢?代码如下:
select Sname from Student where Sdept = 'CS' and Sage < 20;
结果如下图:
[例3.39] 査询选修了 3号课程的学生的学号及其成绩,査询结果按分数的降序排列。
是否能用 != 来判断null值呢?代码如下:
select Sno , Grade from SC where Cno = '3' order by Grade desc;
结果如下图:
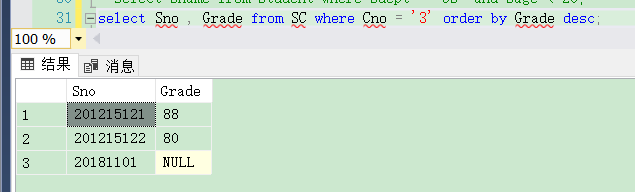
显然,对于 NULL 空值的处理 在降序时被排在了最后,那么升序时候呢?按逻辑应该是在最前面的,我们来试一下。代码如下:
select Sno , Grade from SC where Cno = '3' order by Grade asc;
结果如下:
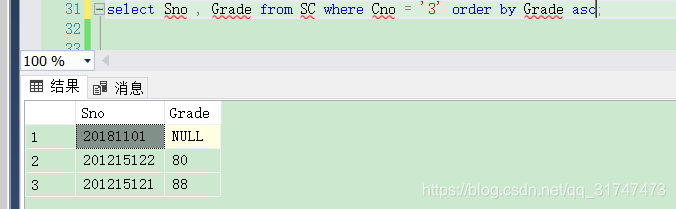
果然如我们推测的一般,NULL的值相当于被系统设定为最小
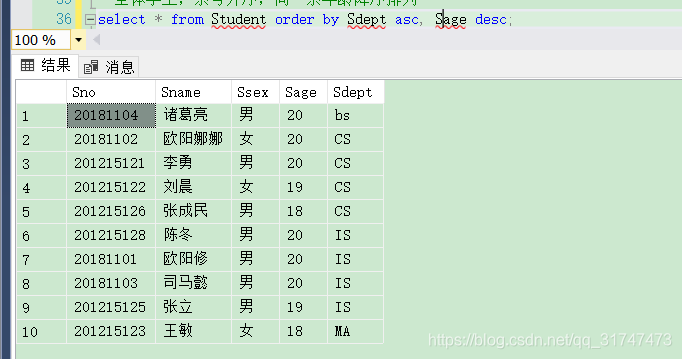
[例3.40] 査询全体学生情况,査询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列。
代码如下:
select * from Student order by Sdept asc, Sage desc;
结果如下图:
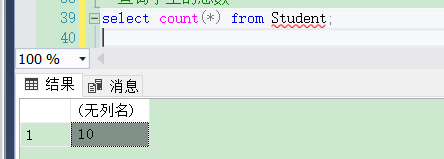
[例3.41] 査询学生总人数。
代码如下:
select count(*) from Student;
结果如下图:
[例3.42] 査询选修了课程的学生人数。
代码如下:
select count(distinct Sno) from Student;
结果如下图:

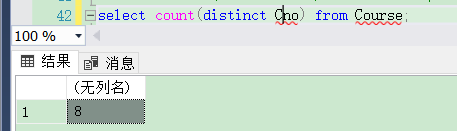
同理,我们可以查询课程一共有几个,代码如下:
select count(distinct Cno) from Course;
运行结果如下:
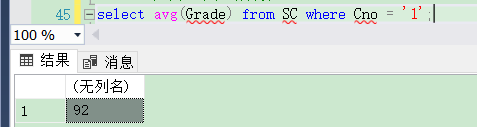
[例3.43] 计算选修1号课程的学生平均成绩。
代码如下:
select avg(Grade) from SC where Cno = '1';
结果如下图:
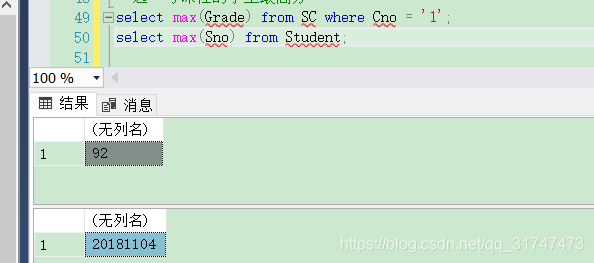
[例3.44] 査询选修1号课程的学生最高分数。
这里我们顺手查了一个学生学号的最大值,代码如下:
--选1号课程的最高分
select max(Grade) from SC where Cno = '1';
--学生学号的最大值
select max(Sno) from Student;
结果如下图:
[例3.45] 査询学生20181101 选修课程的总学分数。
代码如下:
--选1号课程的最高分
select sum(Ccredit) from SC,Course where Sno = '20181101' and SC.Cno = Course.Cno;
结果如下图:

如果此学生选修课总成绩为NULL或者没有此学生会发生什么情况呢?代码如下:
--学生不存在时候
select sum(Ccredit) from SC,Course where Sno = '2018' and SC.Cno = Course.Cno;
--学生选修课成绩为NULL
select sum(Ccredit) from SC,Course where Sno = '20181103' and SC.Cno = Course.Cno;
结果为:

不会报错,输出为null。
[例3.46] 求各个课程号及相应的选课人数。
代码如下:
select Cno , count(Sno) from SC group by Cno;
结果如下图:
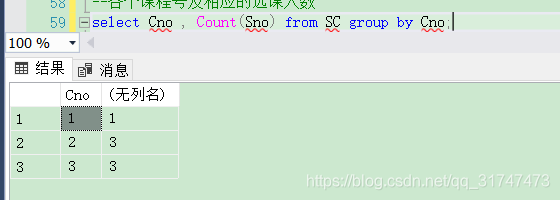
这里分别查了每一个相同课程号的课程共有几个。
[例3.47] 査询选修了三门以上课程的学生学号。
容易知道,我们的表中没有选修三门课以上的同学,所以一起查询选修两门课以上的可以对比,代码如下:
--选修三门课以上的
select Sno from SC group by Sno having count(*) > 3;
--选修两门课以上的
select Sno from SC group by Sno having count(*) > 2;
结果如下图:
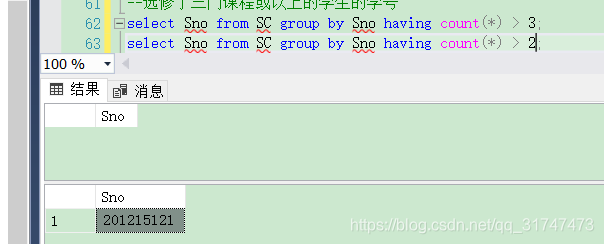
没有结果时候,不会输出任何值。
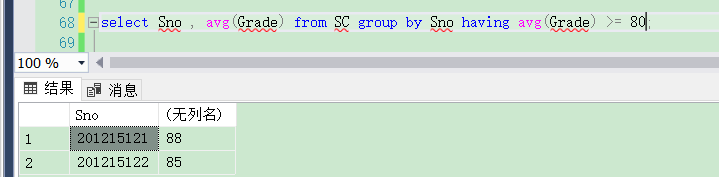
[例3.48] 査询平均成绩大于等于90分的学生学号和平均成绩。
最容易想到的就是下面的方法:
select Sno , avg(Grade) from SC where avg(Grade) >= 90 group by Sno;
但是我们可以看到,错误,报错为:聚合不应出现在 WHERE 子句中,除非该聚合位于 HAVING 子句或选择列表所包含的子查询中,并且要对其进行聚合的列是外部引用。

因为where子句中不能用聚集函数作为条件表达式的,要怎么写呢?请看下面(没有成绩大于90的,我就改为了大于80的),代码如下:
select Sno , avg(Grade) from SC group by Sno having avg(Grade) >= 80;
结果如下: