一、扩容的基本思路
JDK1.8中,ConcurrentHashMap最复杂的部分就是扩容/数据迁移,涉及多线程的合作和rehash。我们先来考虑下一般情况下,如何对一个Hash表进行扩容。
1、扩容思路
Hash表的扩容,一般都包含两个步骤:
①table数组的扩容
table数组的扩容,一般就是新建一个2倍大小的槽数组,这个过程通过由一个单线程完成,且不允许出现并发。
②数据迁移
所谓数据迁移,就是把旧table中的各个槽中的结点重新分配到新table中。比如,单线程情况下,可以遍历原来的table,然后put到新table中。
这一过程通常涉及到槽中key的rehash,因为key映射到桶的位置与table的大小有关,新table的大小变了,key映射的位置一般也会变化。
ConcurrentHashMap在处理rehash的时候,并不会重新计算每个key的hash值,而是利用了一种很巧妙的方法。我们在上一篇说过,ConcurrentHashMap内部的table数组的大小必须为2的幂次,原因是让key均匀分布,减少冲突,这只是其中一个原因。另一个原因就是:
当table数组的大小为2的幂次时,通过key.hash & table.length-1这种方式计算出的索引i,当table扩容后(2倍),新的索引要么在原来的位置i,要么是i+n。
我们来看个例子: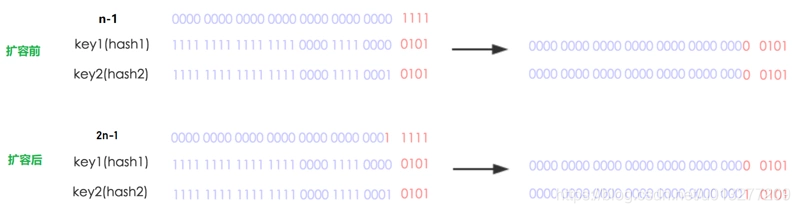
上图中:
扩容