Logstash是一种开源数据处理管道,它从一个或多个输入中提取事件,对其进行转换,然后将每个事件发送至一个或多个输出。 一些Logstash实现可能具有多行代码,并且可能处理来自多个输入源的事件。 为了使此类实现更具可维护性,我将展示如何通过从模块化组件创建管道来提高代码的可重用性。
写这篇文章的动机
Logstash通常有必要将通用的处理逻辑子集应用于来自多个输入源的事件。通常通过以下两种方式之一来实现:
- 在单个管道中处理来自多个不同输入源的事件,以便可以将通用逻辑轻松应用于来自所有源的所有事件。在这样的实现中,除了通用逻辑之外,通常还有大量的条件逻辑。因此,此方法可能会导致Logstash实现复杂且难以理解。
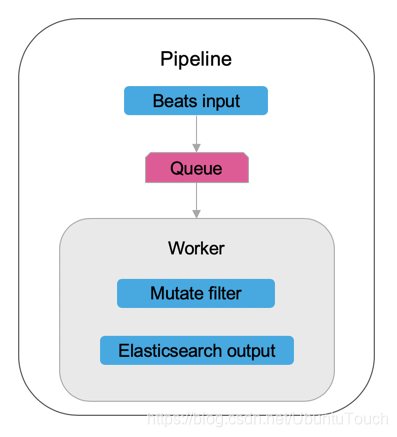
- 执行一个唯一的管道来处理来自每个唯一输入源的事件。这种方法需要将通用功能复制和复制到每个管道中,这使得难以维护代码的通用部分。

本博客中介绍的技术通过将模块化管道组件存储在不同的文件中,然后通过组合这些组件来构造管道,从而解决了上述方法的缺点。此技术可以减少流水线复杂性并可以消除代码重复。
模块化管道建设
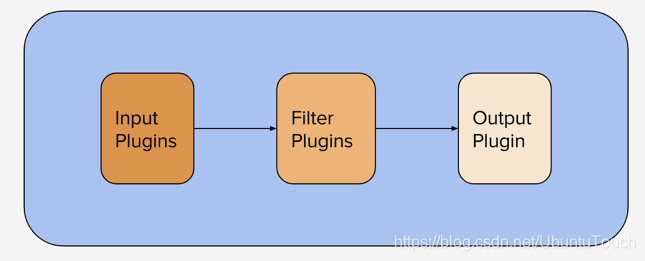
Logstash配置文件由Logstash管道执行的输入,过滤器和输出组成:
在更高级的设置中,通常有一个Logstash实例执行多个管道。 默认情况下,当启动不带参数的Logstash时,它将读取一个名为pipelines.yml的文件,并将实例化指定的管道。
Logstash输入,过滤器和输出可以存储在多个文件中,可以通过指定glob表达式来选择这些文件以将其包含在管道中。 匹配全局表达式的文件将按字母顺序组合。 由于过滤器的执行顺序通常很重要,因此在文件名中包括数字标识符以确保文件按所需顺序组合可能会有所帮助。
在下面,我们将定义两个独特的管道,这些管道是几个模块化Logstash组件的组合。 我们将Logstash组件存储在以下文件中:
- 输入声明:01_in.cfg,02_in.cfg
- 过滤器声明:01_filter.cfg,02_filter.cfg,03_filter.cfg
- 输出声明:01_out.cfg
然后使用glob表达式,在pipelines.yml中定义管道,使其由所需组件组成,如下所示:
- pipeline.id: my-pipeline_1
path.config: "<path>/{01_in,01_filter,02_filter,01_out}.cfg"
- pipeline.id: my-pipeline_2
path.config: "<path>/{02_in,02_filter,03_filter,01_out}.cfg"在上述管道配置中,两个管道中都存在文件02_filter.cfg,该文件演示了如何在两个文件中定义和维护两个管道共有的代码,以及如何由多个管道执行这些代码。
测试管道
在本节中,我们提供文件的具体示例,这些文件将被合并到上述pipelines.yml中定义的唯一管道中。 然后,我们使用这些文件运行Logstash,并显示生成的输出。
配置文件
input file:01_in.cfg
该文件定义了作为生成器的输入。 生成器输入旨在测试Logstash,在这种情况下,它将生成一个事件。
input {
generator {
lines => ["Generated line"]
count => 1
}
}Input file: 02_in.cfg
该文件定义了一个侦听stdin的Logstash输入。
input {
stdin {}
}Filter file: 01_filter.cfg
filter {
mutate {
add_field => { "filter_name" => "Filter 01" }
}
}Filter file: 02_filter.cfg
filter {
mutate {
add_field => { "filter_name" => "Filter 02" }
}
}Filter file: 03_filter.cfg
filter {
mutate {
add_field => { "filter_name" => "Filter 03" }
}
}Output file: 01_out.cfg
output {
stdout { codec => "rubydebug" }
}执行管道
不带任何选项启动Logstash将执行我们先前定义的pipelines.yml文件。 运行Logstash,如下所示:
./bin/logstash由于管道my-pipeline_1正在执行生成器以模拟输入事件,因此Logstash完成初始化后,我们应该看到以下输出。 这表明01_filter.cfg和02_filter.cfg的内容已按预期由该管道执行。
{
"@timestamp" => 2020-02-29T02:44:40.024Z,
"host" => "liuxg-2.local",
"sequence" => 0,
"message" => "Generated line",
"@version" => "1",
"filter_name" => [
[0] "Filter 01",
[1] "Filter 02"
]
}当另一个名为my-pipeline_2的管道正在等待stdin上的输入时,我们尚未看到该管道处理的任何事件。 在运行Logstash的终端中键入内容,然后按Return键为此管道创建一个事件。 完成此操作后,您应该会看到类似以下的内容:
hello, the world!
{
"message" => "hello, the world!",
"@version" => "1",
"@timestamp" => 2020-02-29T02:48:26.142Z,
"host" => "liuxg-2.local",
"filter_name" => [
[0] "Filter 02",
[1] "Filter 03"
]
}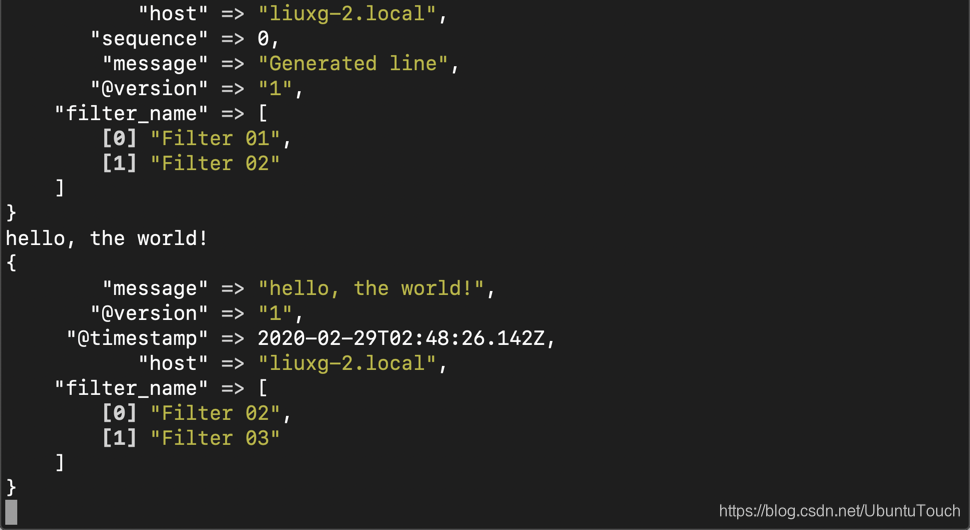
从上面我们可以看到,按预期应用了02_filter.cfg和03_filter.cfg的逻辑。
执行顺序
请注意,Logstash不会注意glob表达式中文件的顺序。 它仅使用glob表达式确定要包含的文件,然后按字母顺序对其进行排序。 这就是说,即使我们要更改my-pipeline_2的定义,以使03_filter.cfg出现在02_filter.cfg之前的glob表达式中,每个事件也会在03_filter.cfg中定义的过滤器之前通过02_filter.cfg中的过滤器。
结论
使用全局表达式可以使Logstash管道由模块化组件组成,这些组件存储为单独的文件。 这样可以提高代码的可维护性,可重用性和可读性。
附带说明,除了本博客中记录的技术之外,还应考虑管道到管道的通信,以查看它是否可以改善Logstash实现模块。
参考:
【1】https://www.elastic.co/blog/how-to-create-maintainable-and-reusable-logstash-pipelines
