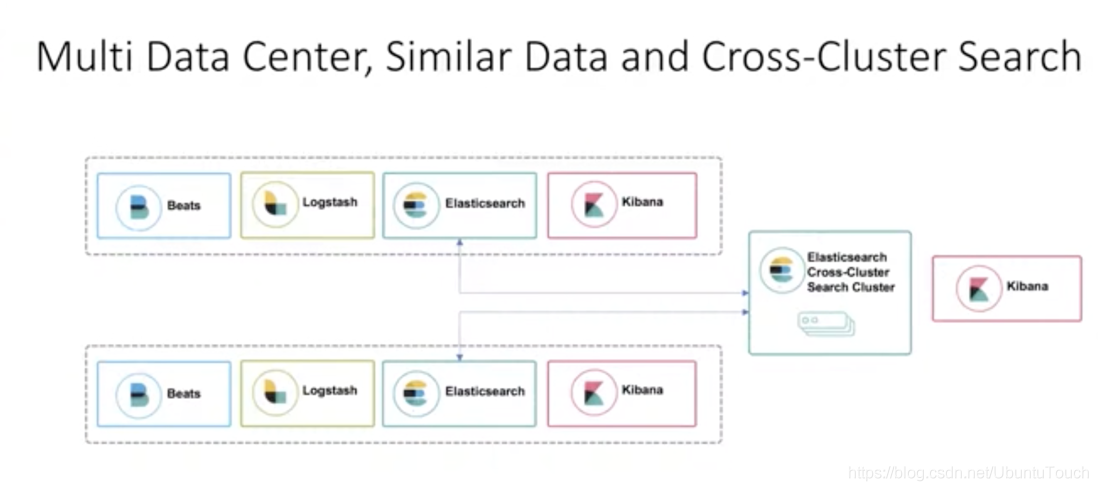
跨集群搜索(cross-cluster search)使您可以针对一个或多个远程集群运行单个搜索请求。 例如,您可以使用跨集群搜索来筛选和分析存储在不同数据中心的集群中的日志数据。

如上面所述,当我们的client向集群cluster_1发送请求时,它可以搜索自己本身的集群,同时也可以向另外的两个集群cluster_2及cluster_3发送请求。最后的结果由cluster_1返回给客户端。
目前支持的APIs:
跨集群搜索例子
注册remote cluster
要执行跨集群搜索,必须至少配置一个远程集群。在群集设置中配置了远程群集
- 使用cluster.remote属性
- 种子(seeds)是远程集群中的节点列表,用于在注册远程集群时检索集群状态
以下cluster update settings API请求添加了三个远程集群:cluster_one,cluster_two和cluster_three。
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster_one": {
"seeds": [
"127.0.0.1:9300"
]
},
"cluster_two": {
"seeds": [
"127.0.0.1:9301"
]
},
"cluster_three": {
"seeds": [
"127.0.0.1:9302"
]
}
}
}
}
}动手实践
安装集群
在今天的实践中,我们来设置两个集群:

在上面的描述中,我们配置了两个集群:cluster 1及cluster 2。它们位于同一个网路内,可以互相访问。如果你还没有安装好你的Elasticsearch集群的话,请参阅我之前的文章 “Elastic:菜鸟上手指南”安装好自己的Elasticsearch及Kiban。在安装时,我们必须注意的是:
- 把我们的Elasticsearch及Kibana分别解压,并安装于不同的两个目录中。这样它们的安装互相不干扰,从而能形成两个不同的集群,虽然它们集群的名字可以是一样的。为了方便,我们把两个集群的名字分别取为cluster_1及cluster_2。
- 我们可以分别对Elasticsearch的配置文件config/elasticsearch.yml做如上的配置。同时我们也需要对Kibana之中的config/kibana.yml做配置,这样使得cluster_1对应的Kibana的口地址为5601,而对于cluster_2的Kibana的口地址为5602。
在上面可能有很多人感到疑问:为啥我们还需要配置端口地址9300及9301?事实上,Elasticsearch中有两种重要的网络通信机制需要了解:
- HTTP:用于HTTP通信绑定的地址和端口,这是Elasticsearch REST API公开的方式
- transport:用于集群内节点之间的内部通信

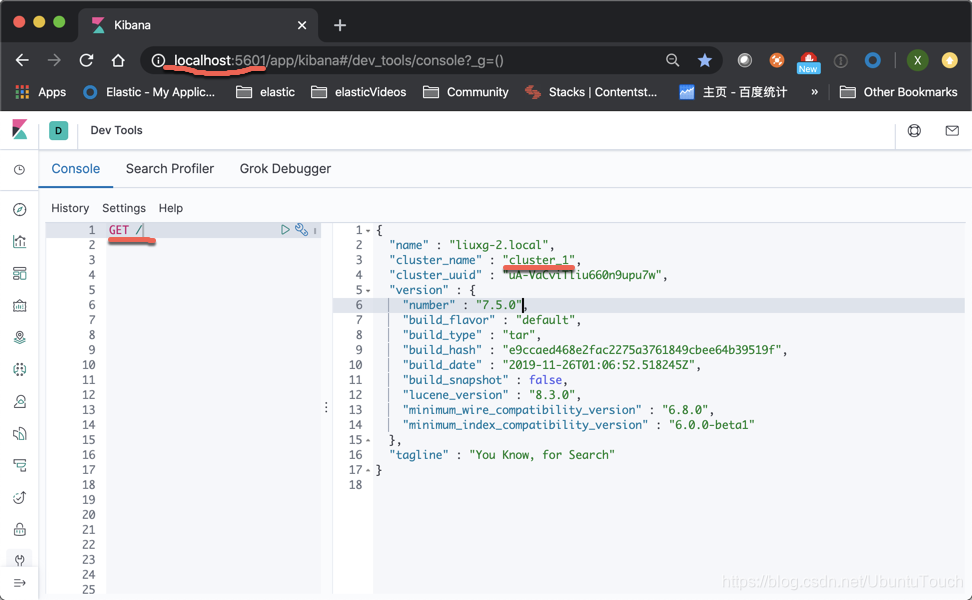
等我们安装好我们的两个集群我们可以通过如下的方法来查看:
cluster_1
cluster_2
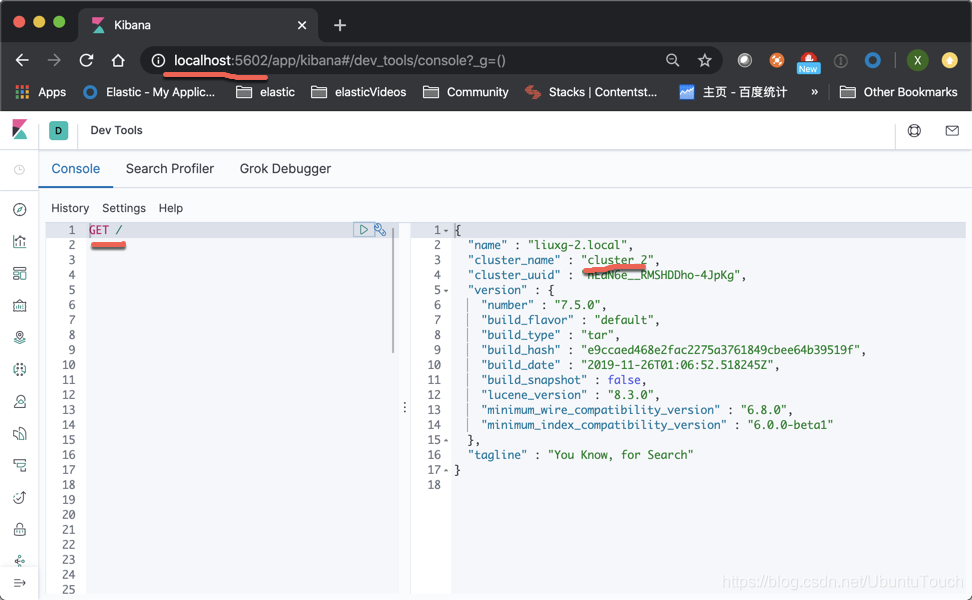
如果我们能够同时看到上面的两个集群的画面,则表明我们的集群已经设置正确。
搜索
我们接下来进行配置。我们在kibana_2,也既是端口地址为5602的Kibana。我们打入如下的命令:
PUT _cluster/settings
{
"persistent": {
"cluster.remote": {
"remote_cluster": {
"seeds": [
"127.0.0.1:9300"
]
}
}
}
}在上面,我们在cluster_2里配置可以连接到cluster_1的这样设置。因为cluster_1的transport口地址是9300。
我们可以看到如下的返回信息:

我们接下来使用如下的命令来检查我们的连接状态:
GET _remote/info我们可以看到如下的响应信息:
{
"remote_cluster" : {
"seeds" : [
"127.0.0.1:9300"
],
"connected" : true,
"num_nodes_connected" : 1,
"max_connections_per_cluster" : 3,
"initial_connect_timeout" : "30s",
"skip_unavailable" : false
}
}它表明我们的连接是成功的。
这个时候我们在Kibana_1中创建如下的twitter索引:
POST _bulk
{"index":{"_index":"twitter","_id":1}}
{"user":"张三","message":"今儿天气不错啊,出去转转去","uid":2,"age":20,"city":"北京","province":"北京","country":"中国","address":"中国北京市海淀区","location":{"lat":"39.970718","lon":"116.325747"}, "DOB": "1999-04-01"}
{"index":{"_index":"twitter","_id":2}}
{"user":"老刘","message":"出发,下一站云南!","uid":3,"age":22,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区台基厂三条3号","location":{"lat":"39.904313","lon":"116.412754"}, "DOB": "1997-04-01"}
{"index":{"_index":"twitter","_id":3}}
{"user":"李四","message":"happy birthday!","uid":4,"age":25,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区","location":{"lat":"39.893801","lon":"116.408986"}, "DOB": "1994-04-01"}
{"index":{"_index":"twitter","_id":4}}
{"user":"老贾","message":"123,gogogo","uid":5,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区建国门","location":{"lat":"39.718256","lon":"116.367910"}, "DOB": "1989-04-01"}
{"index":{"_index":"twitter","_id":5}}
{"user":"老王","message":"Happy BirthDay My Friend!","uid":6,"age":26,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区国贸","location":{"lat":"39.918256","lon":"116.467910"}, "DOB": "1993-04-01"}
{"index":{"_index":"twitter","_id":6}}
{"user":"老吴","message":"好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid":7,"age":28,"city":"上海","province":"上海","country":"中国","address":"中国上海市闵行区","location":{"lat":"31.175927","lon":"121.383328"}, "DOB": "1991-04-01"}我们可以在Kibana_1中通过如下的命令来检查twitter索引是否已经被成功创建:
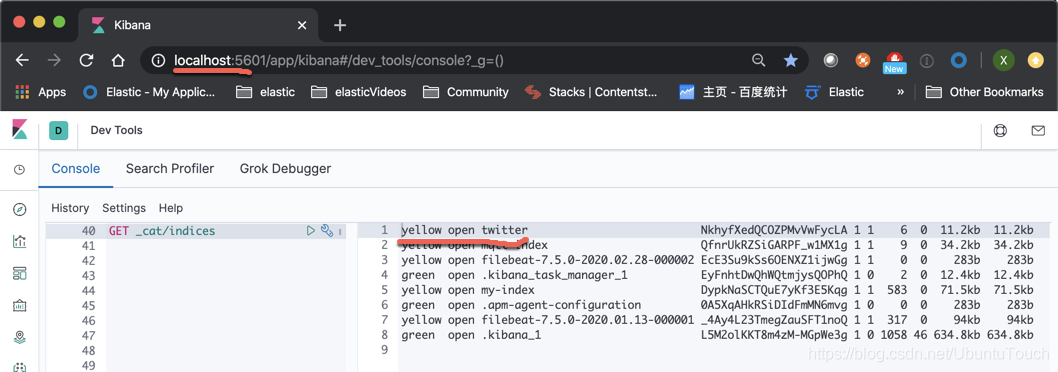
在上面,我们可以看到我们已经成功地在cluster_1上创建了twitter索引,那么我们怎么在cluster_2上对这个进行搜索呢?
我们在Kibana_2里,打入如下的命令:
GET remote_cluster:twitter/_search我们将看到如下的输出:

从上面我们可以看出来,我们可以对位于cluster_1的twitter索引进行搜索。
对remote索引进行分析
cluster_1
在Kibana_1中,我们通过如下的方法来加载我们的测试数据:
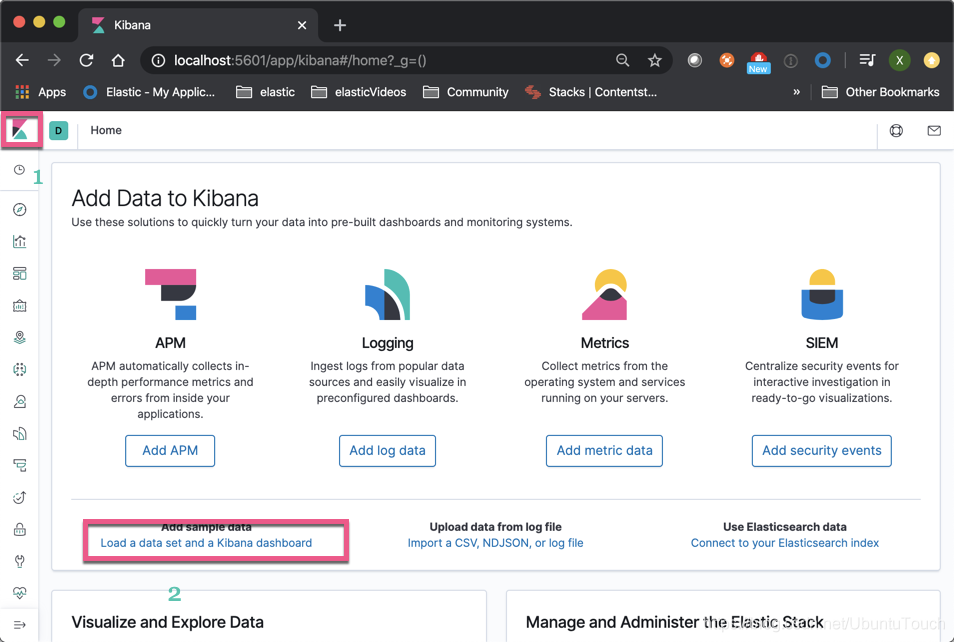
然后点击“Add data”:

这样在cluster_1中,我们已经成功地加载了Sample flight data索引。
cluster_2
我们打开Kibana_2,并创建一个为cluster_1中的Sample flight data的index pattern
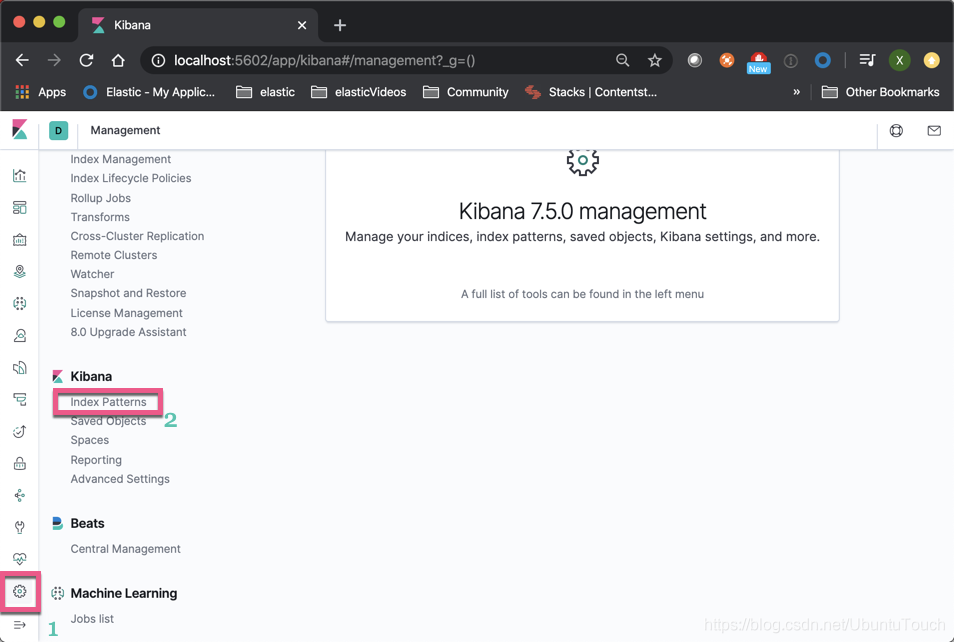
点击“Create index pattern”:
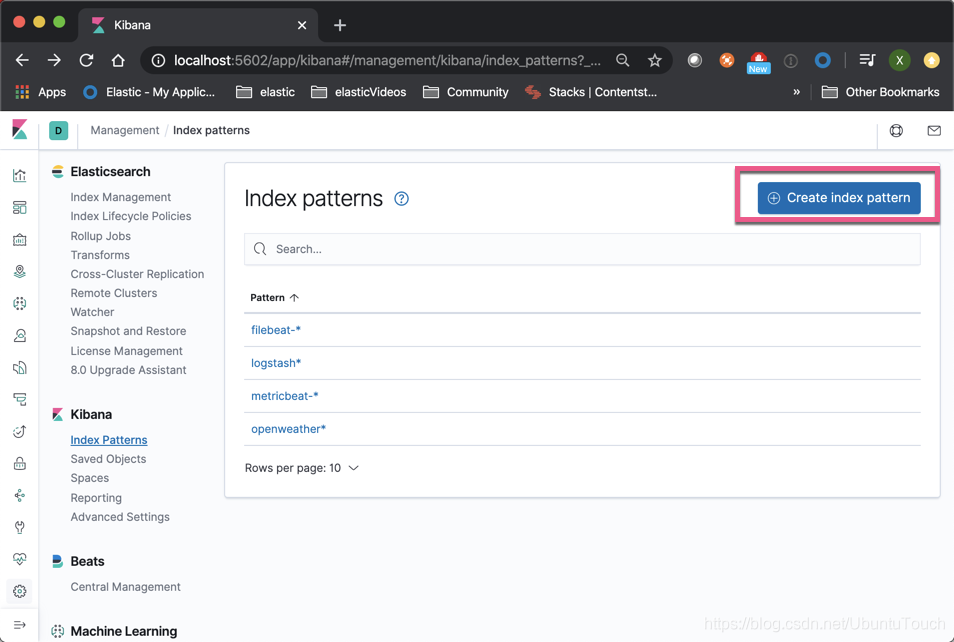
输入我们想要的索引。注意在前面加上remote_cluster:
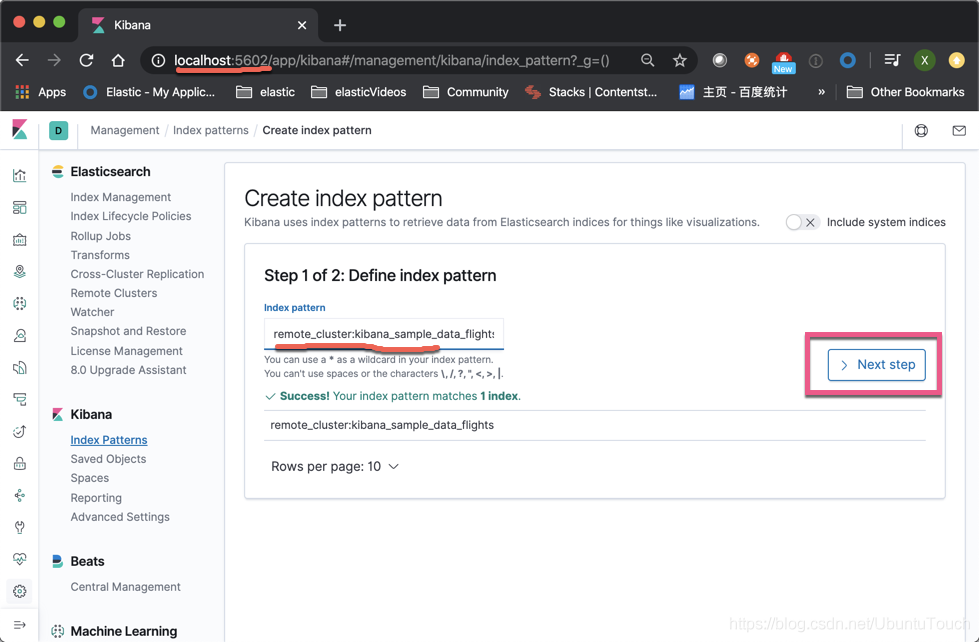
在上面,如果我们有本地和远程相同类型的索引(比如,我们针对不同地区的服务器来收集数据),我们可以使用逗号“,”把所有的索引放在一起做成一个index pattern,比如就像:remote_cluster:kibana_sample_data_flights, my_local_index。
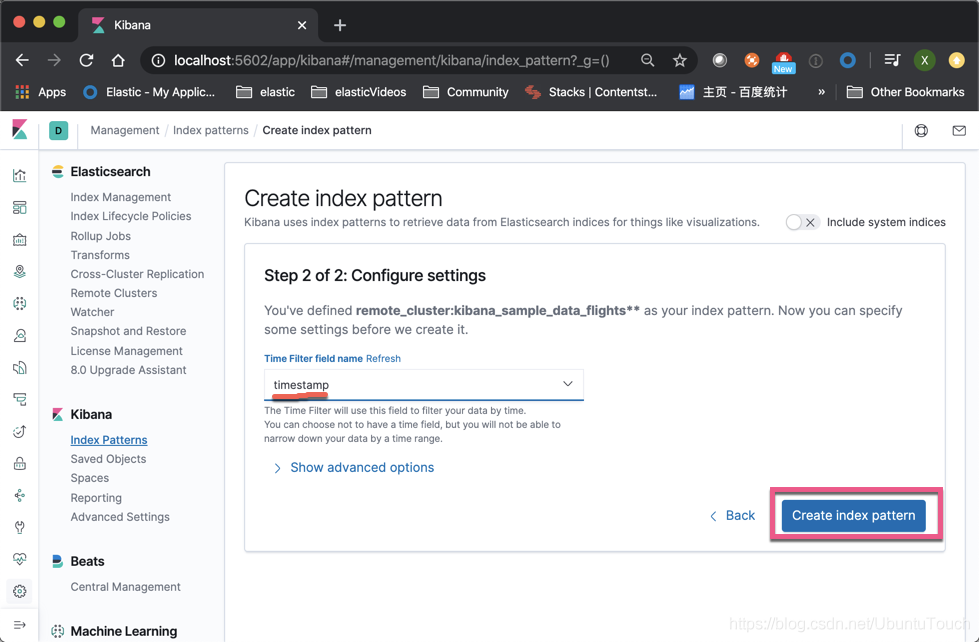
点击“Create index pattern”:

这样,我们就创建了位于cluster_1里的索引的一个index pattern。我们点击右上角的星号,并使之成为我们的默认的index。
我们点击Kibana_2左上角的Discover:

因为我们的默认的index是remote_cluster:kibana_sample_data_flights,所以我们的Discover默认的情况先显示的是所有关于位于cluster_1上的kibana_sample_data_flights索引数据。我们可可以在cluster_2对这些数据进行分析。
参考:
【1】https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-cross-cluster-search.html
