免责声明:原创文章,仅用于学习,希望看到文章的朋友,不要随意用于商业,本作者保留当前文章的所有法律权利。欢迎评论,点赞,收藏,转发!
关于亚马逊的爬虫,针对不同的使用场合,前前后后写了有六七个了,今天拿出其中一个爬虫,也是相对其他几个爬虫难度稍微大一些的,这个爬虫用到了我之前没有使用过的一个爬虫手法,虽然头疼了一天半的时间,不过最终还是写出来了!
先上爬到结果,一睹芳容!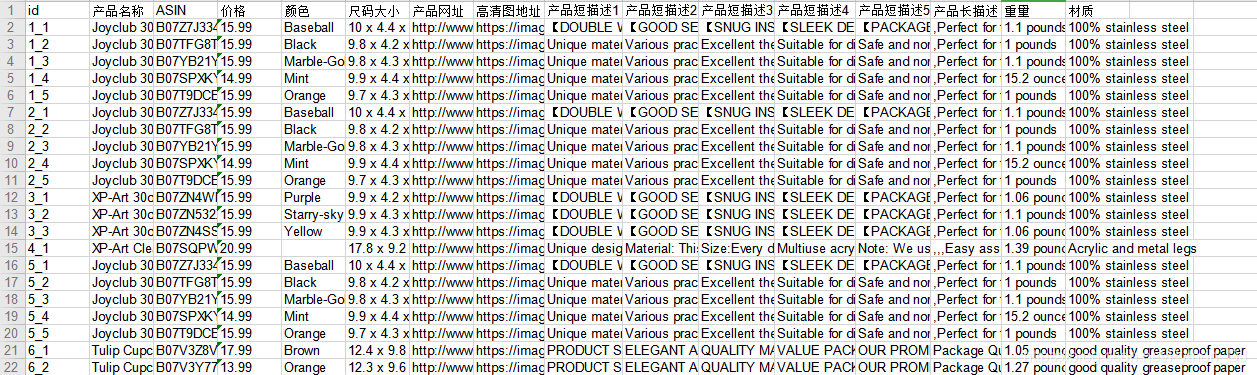
# settings.py我也就是修改了一下请求头,没有别的什么参数好设置的
DEFAULT_REQUEST_HEADERS = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding'