文件压缩有两大好处,节约磁盘空间,加速数据在网络和磁盘上的传输
前面hadoop的版本经过重新编译之后,可以看到hadoop已经支持所有的压缩格式了,剩下的问题就是该如何选择使用这些压缩格式来对MapReduce程序进行压缩
可以使用bin/hadoop checknative 来查看编译之后的hadoop支持的各种压缩,如果出现openssl为false,那么就在线安装一下依赖包
bin/hadoop checknative
yum install openssl-devel

hadoop支持的压缩算法
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|---|
| DEFLATE | 无 | DEFLATE | .deflate | 否 |
| Gzip | gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | bzip2 | bz2 | 是 |
| LZO | lzop | LZO | .lzo | 否 |
| LZ4 | 无 | LZ4 | .lz4 | 否 |
| Snappy | 无 | Snappy | Snappy扩展名 | 否 |
各种压缩算法对应使用的java类
| 压缩格式 | 工具 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DeFaultCodec |
| gzip | org.apache.hadoop.io.compress.GZipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
常见的压缩速率比较
| 压缩算法 | 原始文件大小 | 压缩后的文件大小 | 压缩速度 | 解压缩速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO-bset | 8.3GB | 2GB | 4MB/s | 60.6MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/S | 74.6MB/s |
snappy比以上压缩算法都要快
如何开启压缩
在代码中进行设置压缩
设置map阶段的压缩
Configuration configuration = new Configuration();
configuration.set("mapreduce.map.output.compress","true");
configuration.set("mapreduce.map.output.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
设置reduce阶段的压缩
configuration.set("mapreduce.output.fileoutputformat.compress","true");
configuration.set("mapreduce.output.fileoutputformat.compress.type","RECORD");
configuration.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
代码:
MoreFileMap
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class MoreFileMap extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取所属的文件名称
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String filename = fileSplit.getPath().getName();
context.write(new Text(filename), value);
}
}
MoreFilReduce
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MoreFilReduce extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//遍历获去每一条数据
for (Text value : values) {
context.write(key, value);
}
}
}
MoreFileDriver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MoreFileDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
//设置map使用的压缩算法
conf.set("mapreduce.map.output.compress","true");
conf.set("mapreduce.map.output.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
//设置reduce使用的压缩算法
conf.set("mapreduce.output.fileoutputformat.compress","true");
conf.set("mapreduce.output.fileoutputformat.compress.type","RECORD");
conf.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
Job job = Job.getInstance(conf, "MoreFile");
job.setJarByClass(MoreFileDriver.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("aaaa"));
job.setMapperClass(MoreFileMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(MoreFilReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("cccc"));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new MoreFileDriver(), args);
}
}
集群中的文件

打包代码
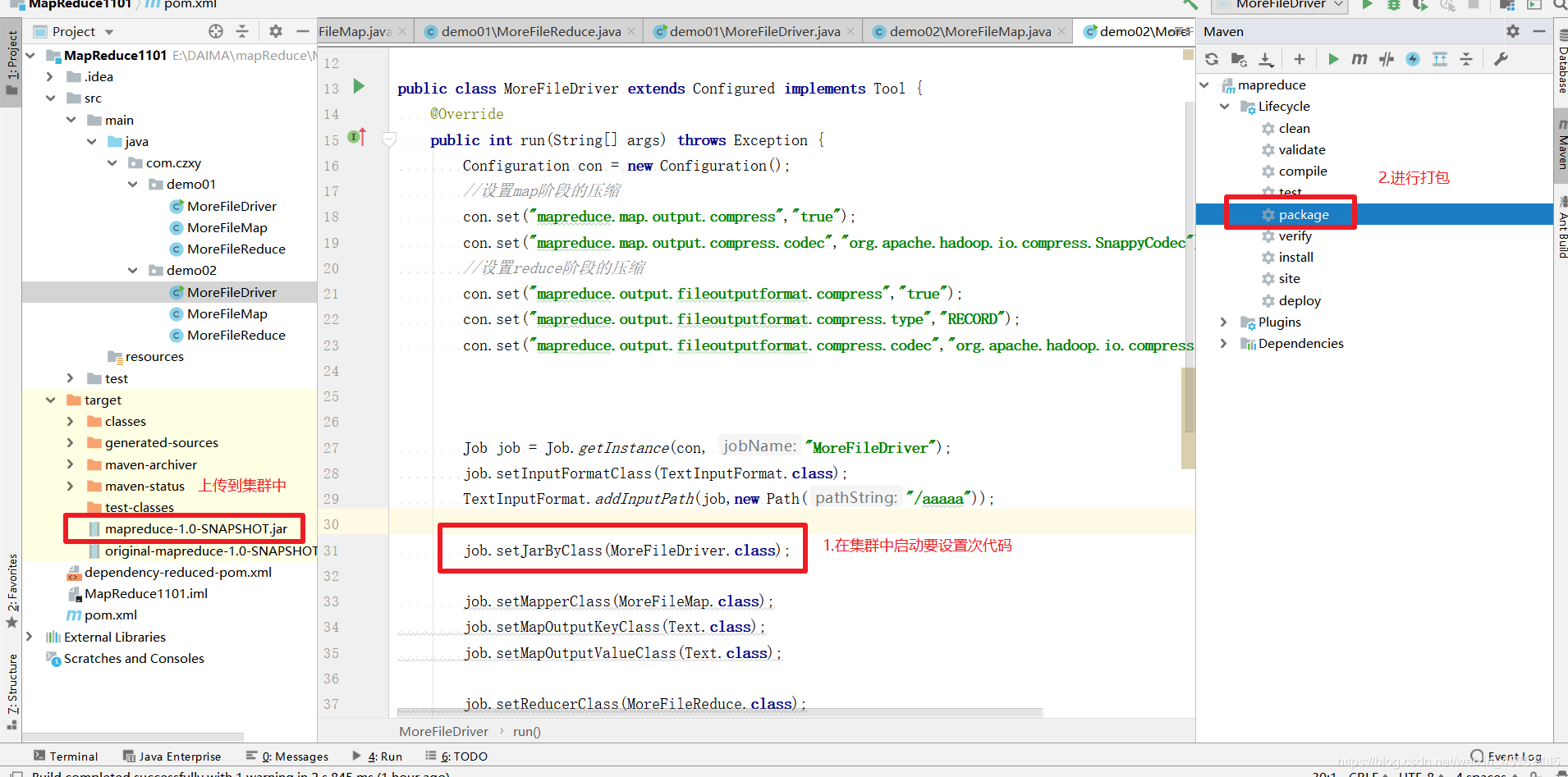
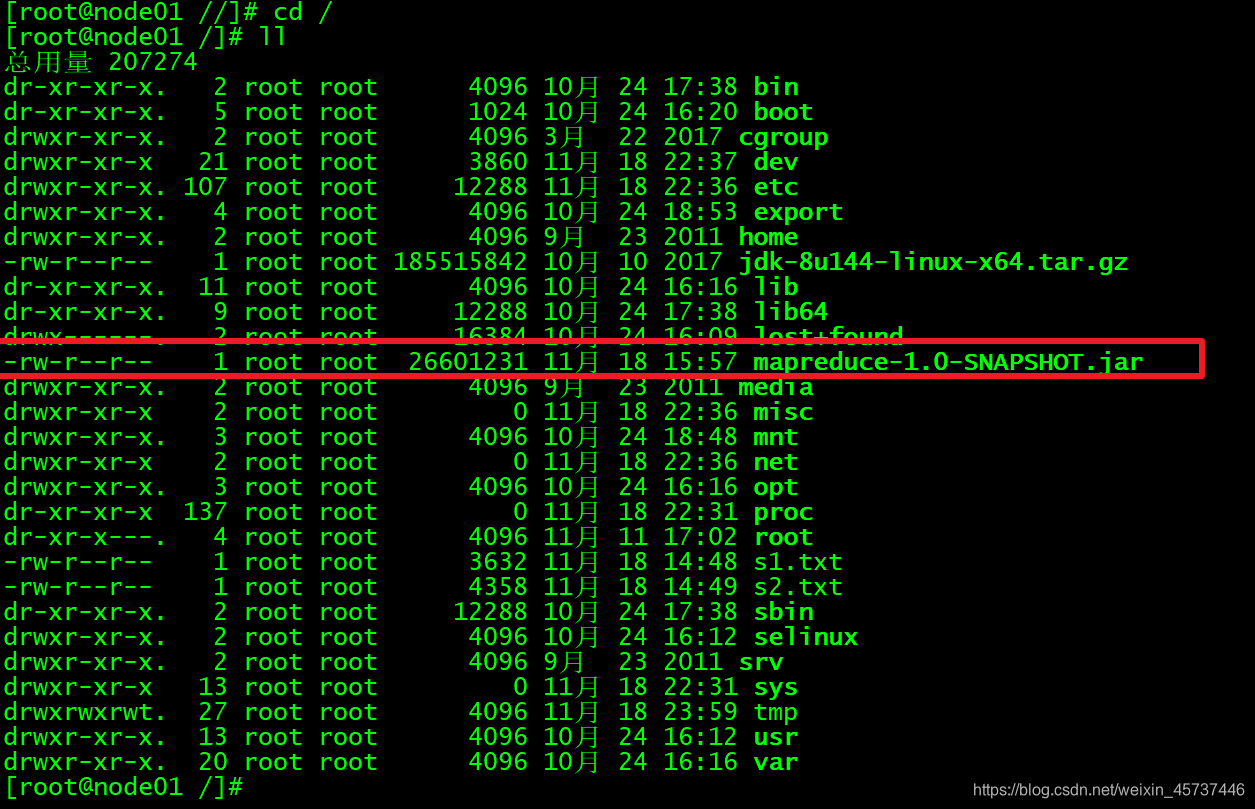
上传Jar包
执行Jar包

mapreduce-1.0-SNAPSHOT ---上传的jar包
com.czxy.demo02.MoreFileDriver ---包名
运行结果

更好资源:大萝卜博客网 新人建站 求支持
