参考 https://blog.csdn.net/songhaifengshuaige/article/details/79575308
准备工作
1.下载hadoop3.0.0的压缩包,我有压缩包就放在我的csdn上了,bin也是更新过的,不用再更新了。
链接:https://pan.baidu.com/s/14HjD8qLyyfcscxTlsCIy3w
提取码:e432
(这个是我自己加的百度云链接,与参考的链接作者无关)
2.解压缩到D: 盘(这里必须一致,不然下面的就没意义了)
3、配置环境变量:
添加HADOOP_HOME配置:
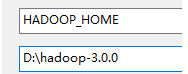
添加HADOOP_SUER_NAME
在Path中添加如下:
![]()
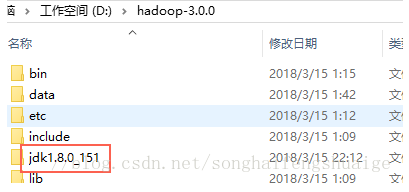
4、Hadoop需要依赖JDK,考虑其路径中不能有空格,故直接安装如下目录:
Hadoop配置 :
1、修改D:/hadoop-3.0.0/etc/hadoop/core-site.xml配置:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2、修改D:/hadoop-3.0.0/etc/hadoop/mapred-site.xml配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3、在D:/hadoop-3.0.0目录下创建data目录,作为数据存储路径:
![]()
在D:/hadoop-3.0.0/data目录下创建datanode目录;
在D:/hadoop-3.0.0/data目录下创建namenode目录;
4、修改D:/hadoop-3.0.0/etc/hadoop/hdfs-site.xml配置:
<configuration>
<!-- 这个参数设置为1,因为是单机版hadoop -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/hadoop-3.0.0/data/namenode</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/D:/hadoop-3.0.0/data/snn</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>/D:/hadoop-3.0.0/data/snn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/hadoop-3.0.0/data/datanode</value>
</property>
</configuration>
5、修改D:/hadoop-3.0.0/etc/hadoop/yarn-site.xml配置:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
6、修改D:/hadoop-3.0.0/etc/hadoop/hadoop-env.cmd配置
找到"set JAVA_HOME=%JAVA_HOME%"替换为"set JAVA_HOME=D:\hadoop-3.0.0\jdk1.8.0_151"
至此配置完成.
启动服务
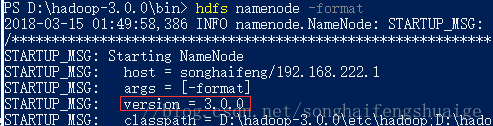
1、D:\hadoop-3.0.0\bin> hdfs namenode -format
2、通过start-all.cmd启动服务: D:\hadoop-3.0.0\sbin\start-all.cmd
![]()
3、此时可以看到同时启动了如下4个服务:
Hadoop Namenode
Hadoop datanode
YARN Resourc Manager
YARN Node Manager

HDFS应用
1、通过http://127.0.0.1:8088/即可查看集群所有节点状态:

2、访问http://localhost:9870/即可查看文件管理页面:
进入文件管理页面:
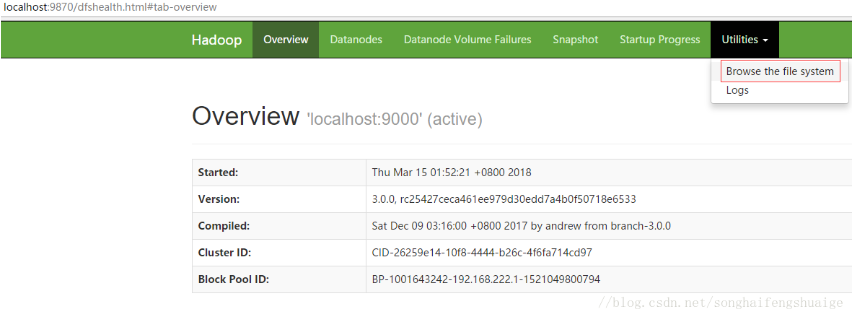
创建目录:

上传文件
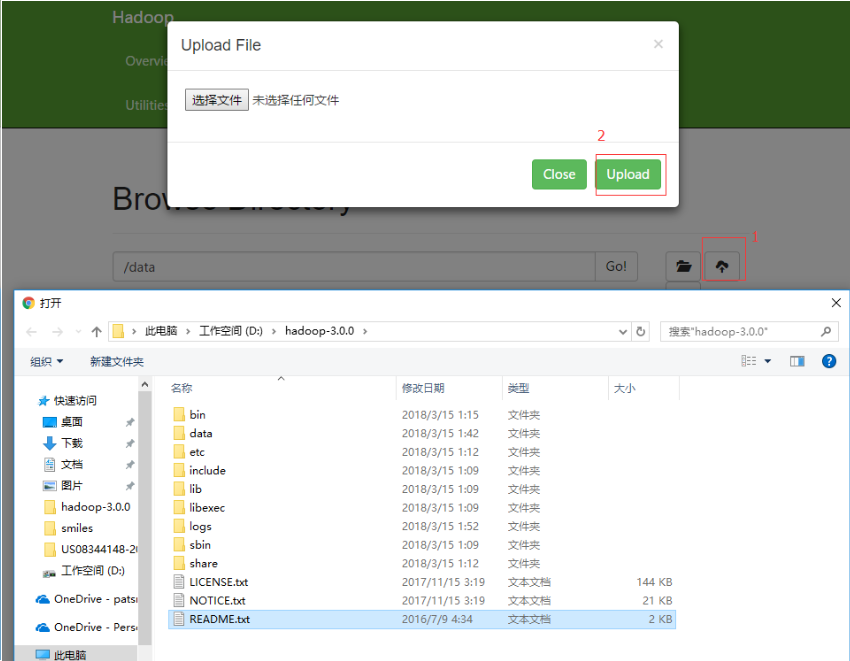
上传成功
在上传的时候出现 “Couldn't find datanode to write file. Forbidden” 错误时,是datanode没有启动成功。
输入jps发现没有datanode线程。
现给出原因和解决方案
原因
当我们使用hadoop namenode -format格式化namenode时,会在namenode数据文件夹(这个文件夹为自己配置文件中dfs.name.dir的路径)中保存一个current/VERSION文件,记录clusterID,datanode中保存的current/VERSION文件中的clustreID的值是上一次格式化保存的clusterID,这样,datanode和namenode之间的ID不一致。
解决方法
如果dfs文件中有重要的数据,那么在dfs/name目录下找到一个current/VERSION文件,记录clusterID并复制。然后dfs/data目录下找到一个current/VERSION文件,将其中clustreID的值替换成刚刚复制的clusterID的值即可;
总结
其实,每次运行结束Hadoop后,都应该关闭Hadoop.
|
下次想重新运行Hadoop,不用再格式化namenode,直接启动Hadoop即可
|
Note:在之前的版本中文件管理的端口是50070,在3.0.0中替换为了9870端口。
3、通过hadoop命令行进行文件操作:
mkdir命令创建目录:hadoop fs -mkdir hdfs://localhost:9000/user
如下新增的user目录
(先在D:盘目录下创建一个11.txt的文件,里面随便写点东西就行)
put命令上传文件:hadoop fs -put D:\11.txt hdfs://localhost:9000/user/
如下上传文件
ls命令查看指定目录文件列表:hadoop fs -ls hdfs://localhost:9000/user/
