Elasticsearch负载均衡策略发生死锁解决方案
一、问题描述与解决方案
1、问题产生的背景
es集群版本:elasticsearch-5.5.3
HEAD插件索引集群显示(red/yellow)。四个节点的集群,索引有大量写入,同时有大量删除操作,删除操作是在单个index(mapping分片数量为4)中执行delete_by_query接口后台执行task的方式实现。集群在负载均衡的时候有线程死锁了,导致分片未分配成功SHARD UNASSINGED。
报错信息:
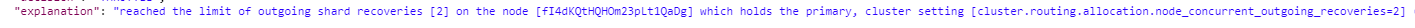 该报错信息源码位置
该报错信息源码位置
reached the limit of outgoing shard recoveries [%d] on the node [%s] which holds the primary,cluser setting [cluster.routing.allocation.node_concurrent_outgoing_recoveries=2]
2、解决方案
在集群设置cluster.routing.allocation.node_concurrent_recoveries这个参数,大于最大分片数量。此参数默认值为2。
二、集群分片分配时的相关设置(译文)
原文链接:Cluster level shard allocation
集群分片分配
分片分配是将分片分配给节点的过程。这可能发生在初始恢复、副本分配、重新平衡期间(分片均衡分配),或者在添加或删除节点时。
分片分配设置
下面的动态设置可以控制分片的分配和恢复:
1.cluster.routing.allocation.enable
为特定类型的分片启用或者禁用分配:
- all-(默认设置)允许所有类型的分片分配。
- primaries-仅仅允许主分片分配
- new_primaries-仅允许新索引的主分片进行分片分配。
- none-任何索引都不允许任何类型的分片分配。
- 此设置不会影响重启节点时本地主分片的恢复。如果重新启动的节点的分配id与集群状态下的一个活动分配id匹配,则该节点拥有未分配的主碎片的副本,该节点将立即恢复该主节点。
2.cluster.routing.allocation.node_concurrent_incoming_recoveries
允许在一个节点上发生多少个并发的传入分片恢复。传入恢复是在节点上分配目标分片(很可能是复制,除非正在重新定位碎片)的恢复。默认为2。
3.cluster.routing.allocation.node_concurrent_outgoing_recoveries
允许在一个节点上执行多少并发传出分片恢复。传出恢复是在节点上分配源分片(很可能是主分片,除非正在重新定位分片)的恢复。默认为2。
4.cluster.routing.allocation.node_concurrent_recoveries
快捷设置:cluster.routing.allocation.node_concurrent_incoming_recoveries 和 cluster.routing.allocation.node_concurrent_outgoing_recoveries.
5.cluster.routing.allocation.node_initial_primaries_recoveries
虽然副本的恢复是通过网络进行的,但是在节点重新启动之后,未分配的主节点的恢复使用本地磁盘中的数据。这些应该是快速的,以便更多的初始主恢复可以在同一节点上并行进行。默认为4。
6.cluster.routing.allocation.same_shard.host
允许执行检查,以防止在单个主机上分配同一分片的多个实例(基于主机名和主机地址)。默认值为false,这意味着在默认情况下不执行任何检查。此设置仅适用于在同一台计算机上启动多个节点的情况。
分片重新平衡分配设置
以下动态设置可用于控制集群中分片的重新平衡:
1.cluster.routing.rebalance.enable
为特定类型的碎片启用或禁用重新平衡:
- all-(默认设置)允许重新平衡所有节点。
- primaries-仅允许主分片重新平衡。
- -replicas-仅允许副分片重新平衡。
- none-任何索引都不允许任何类型的分片重新平衡分配。
2.cluster.routing.allocation.allow_rebalance
指定什么时候允许碎片再平衡:
- always-总是允许。
- indices_primaries_active-只有当集群中的所有主分片都被分配时。
- indices_all_active(默认设置)只有当集群中所有主分片和副分片都被分配时。
3.cluster.routing.allocation.cluster_concurrent_rebalance
允许控制集群范围内允许多少并发分片重新平衡。默认为2。注意,此设置仅控制由于集群中的不平衡而导致的并发碎片重定位的数量。此设置不限制由于分配筛选或强制感知而导致的分片重定位。
启发式分片平衡分配
当不允许重新平衡操作时,任何节点的权值与任何其他节点的权值之间的距离都超过balance.threshold时,集群就处于平衡状态。
1.cluster.routing.allocation.balance.shard
定义在节点上分片分配总数的权重因子(浮点数)。默认值0.45f。这增加了均衡集群中所有节点上分片配置数量相等的趋势。
2.cluster.routing.allocation.balance.index
为分配给特定节点(浮点数)的每个索引的分片数定义权重因子。默认0.55f。这增加了使集群中所有节点的每个索引的碎片数量相等的趋势。
3.cluster.routing.allocation.balance.threshold
应该执行的操作的最小优化值(非负浮点数)。默认为1.0度。提高这个值将导致集群在优化碎片平衡方面的积极性降低。
