文章目录
源码地址:https://github.com/nieandsun/concurrent-study.git
其实我感觉伪共享这个问题很多人都想到过
1 什么是伪共享
1.1 从疑问说起 — 难道JMM中不存在局部性原理???
下面这张图来自我的另一篇文章《【并发编程】— 并发编程中的可见性、原子性、有序性问题》,它描述了java线程与主内存之间的交互关系。但是相信每个人都会有这样的疑问: 难道线程1需要用到变量flag了,就只从主内存中取一个flag变量么???用到一个取一个,这样是不是太消耗性能了???学过mysql的应该都知道,mysql每次取数据会以页为单位进行 ,难道在那种情况下都会谈到的局部性原理,在线程与主内存的交互中就不适用了??? —> 其实这些问号,早就在我脑子里埋藏起来了,相信很多人应该也会有这些疑问。。。
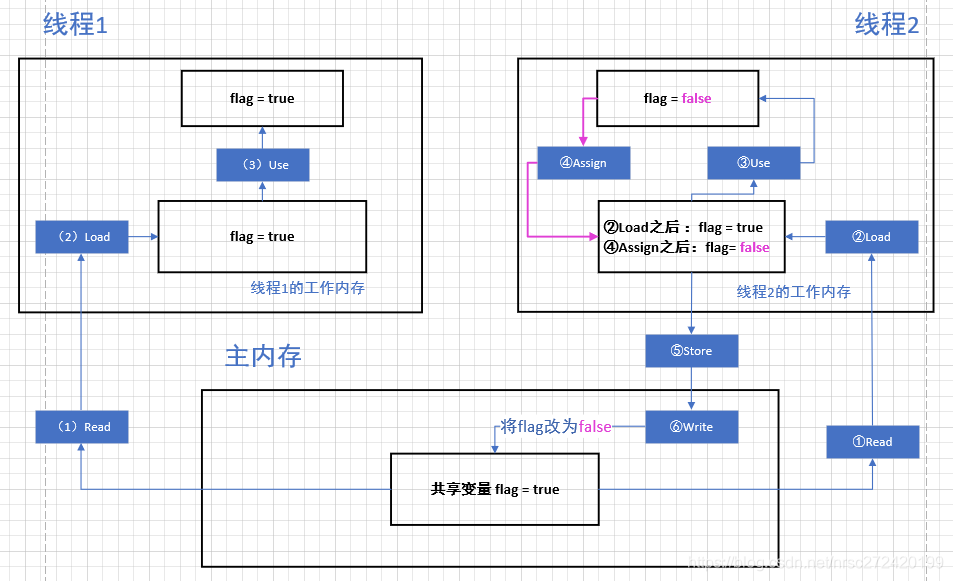
其实java的线程去主内存每次拉取数据,也并不是每次拉取一个变量,而是拉取一个缓存行的数据,那啥叫缓存行呢?
1.2 缓存行的概念
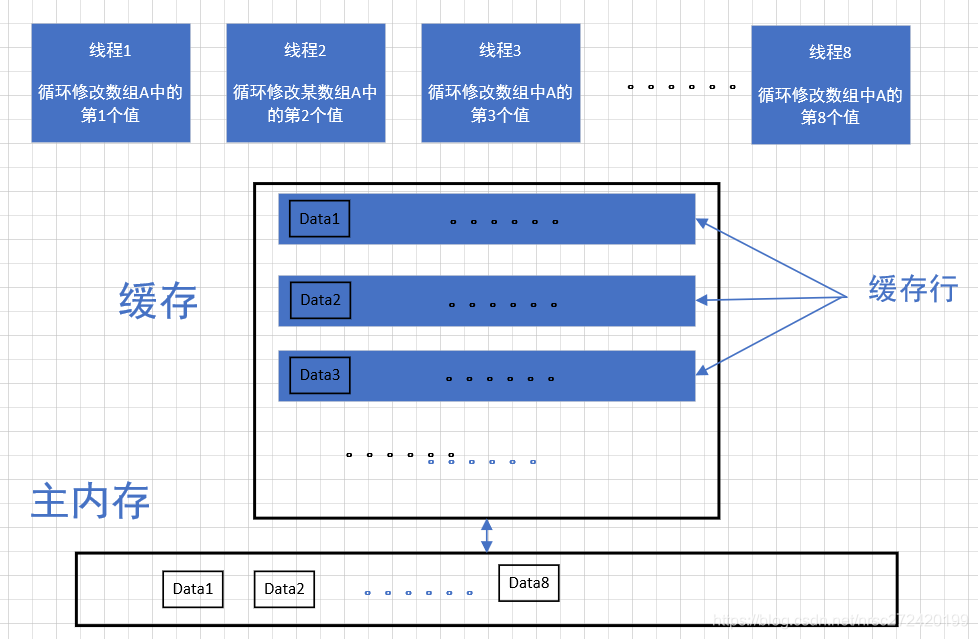
相信大家都知道,线程其实并不是直接从主内存里读取数据,而是经过缓存,并且现在的CPU一般都会有多级缓存,这里假如不考虑多级缓存,那java线程与主内存之间的交互应该可以用下图进行表示:
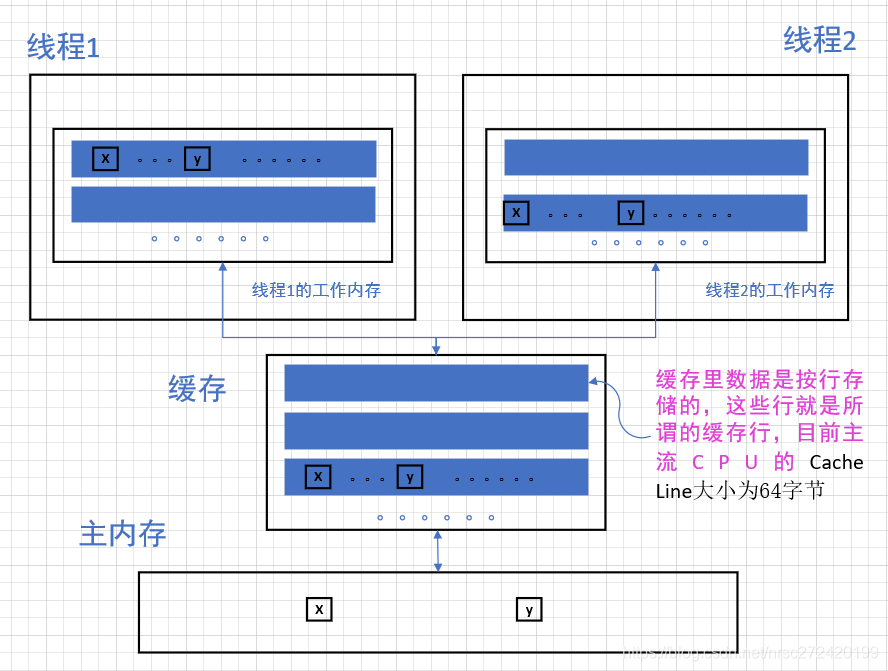
从上图我们可以看出,类似于学习mysql时提到的页的概念,缓存行(Cache Line)可以简单的理解为CPU Cache中的最小缓存单位。现今主流的CPU都不再是按字节访问内存,而是以64字节为单位的块(chunk)拿取,称为一个缓存行(cache line)。当你读一个特定的内存地址时,整个缓存行将从主内存读入到缓存。
当然我觉得可以想到的是主内存和缓存之间的交互,肯定也是一次读取一个数据块的内容,肯定不可能每次只读取一个变量!!!
1.3 伪共享(False Sharing)的概念 + 其可能引发的性能问题
首先明白了缓存行的概念的话,就应该可以想到:
一个缓存行可以存储多个变量(存满当前缓存行的字节数);而CPU对缓存的读取、修改又是以缓存行为最小单位的。
其实这样就产生了一个问题:
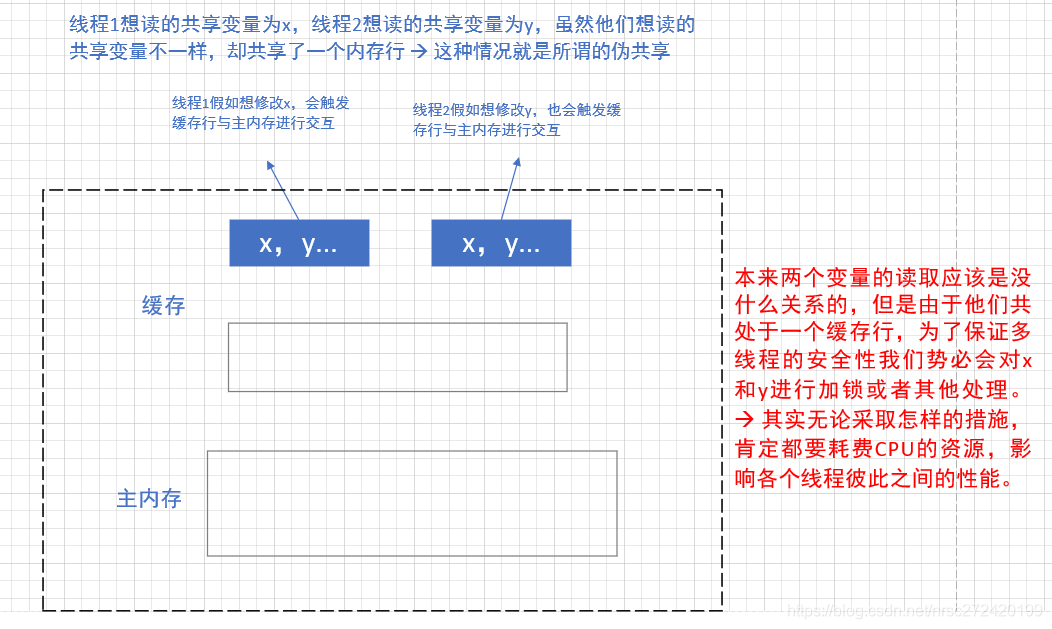
上面是我自己的理解,这里再给一个具体的定义 (来自于某公开课)
一个缓存行可以存储多个变量(存满当前缓存行的字节数);而CPU对缓存的修改又是以缓存行为最小单位的,在多线程情况下,如果需要修改“共享同一个缓存行的变量”,就会无意中影响彼此的性能,这就是伪共享(False Sharing)。
2 如何避免伪共享 — 数据填充
可以使用
数据填充的方式来避免伪共享,即单个数据填充满一个CacheLine。这本质是一种空间换时间的做法。
2.1 不使用数据填充时的效率验证
我们可以按照下图进行设计程序:
- 预先生命数组A;
- 按理说如果不进行缓存行的填充,
数组中A的数据很有可能在一个缓存行,如下图; - 那多个线程对数组A中的值进行修改就会发生伪共享问题
执行时间应该较慢。
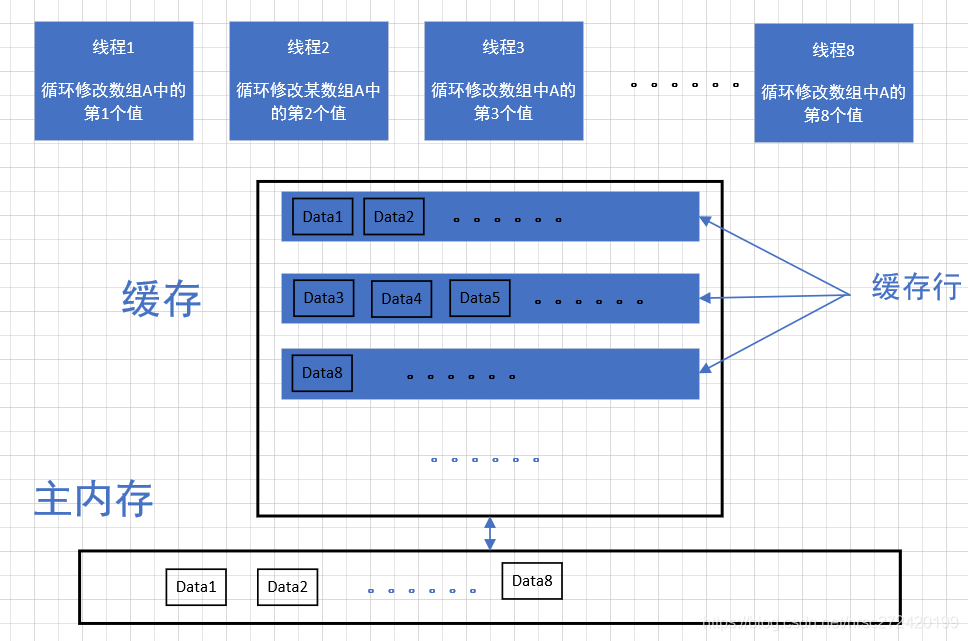
- 按照上图写出的代码如下:
package com.nrsc.ch1.base.falsesharing;
/**
* 类说明:伪共享1
*/
public class FalseSharing implements Runnable {
//获取CPU逻辑处理器的个数
public final static int NUM_THREADS =
Runtime.getRuntime().availableProcessors();
//循环次数
public final static long ITERATIONS = 500L * 1000L * 1000L;
//long型数组的下标
private final int arrayIndex;
//构造函数,用来初始化arrayIndex
public FalseSharing(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
//内部类,里面有一个volatile修饰的变量
public final static class VolatileLong {
public volatile long value = 0L;
}
/*数组大小和CPU逻辑处理器的个数*/
private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
static {
/*将数组初始化*/
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
}
/***
* 本类为Runnable类,该方法为Runnable的run()方法--- 访问数组
*/
@Override
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
public static void main(final String[] args) throws Exception {
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException {
/*创建和CPU数相同的线程*/
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads) {
t.start();
}
/*等待所有线程执行完成*/
for (Thread t : threads) {
t.join();
}
}
}
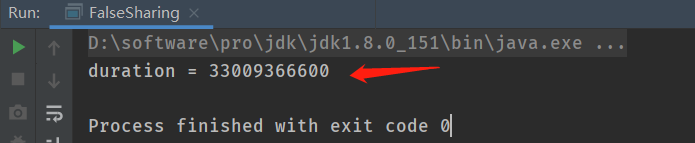
该程序在我电脑上的运行时间为:33009366600毫秒
2.2 手动进行数据填充的效率验证
进行数据填充后,数组A中每一个数据的大小就都为一个缓存行的大小了,也就是说每一个数据占据一个缓存行,如下图
这样的话,多个线程之间就没有影响了,所以执行效率从理论上来说肯定会加快
这种方式在Java7以后可能失效。但是从测试结果看padding仍然起作用。
填充方法:将2.1中的VolatileLong内部类,修改为如下类即可:
//内部类,里面有一个volatile修饰的变量
// long padding避免false sharing
// 按理说jdk7以后long padding应该被优化掉了,但是从测试结果看padding仍然起作用
public final static class VolatileLongPadding {
public long p1, p2, p3, p4, p5, p6, p7; //填充数据
public volatile long value = 0L; //我们实际要用的数据
volatile long q0, q1, q2, q3, q4, q5, q6;//填充数据
}
说实话,这里我有点不是很理解,按说一个long型变量占64位,即8个字节,而缓存行的大小为64个字节,这样的话,其实我只要多加7个无用的数据进行填充就好了,为什么这里会加了14个,且前面的没有volatile 修饰,后面的却有。
其实经过测试,我发现下面这种方式和上面这种方式执行时间差不多:
//内部类,里面有一个volatile修饰的变量
// long padding避免false sharing
// 按理说jdk7以后long padding应该被优化掉了,但是从测试结果看padding仍然起作用
public final static class VolatileLongPadding {
public long p1, p2, p3, p4, p5, p6, p7; //填充数据
public volatile long value = 0L; //我们实际要用的数据
//volatile long q0, q1, q2, q3, q4, q5, q6; //填充数据
}
但是按照下面的这种方式,执行时间差不多是上面两种方式的2倍左右。
//内部类,里面有一个volatile修饰的变量
// long padding避免false sharing
// 按理说jdk7以后long padding应该被优化掉了,但是从测试结果看padding仍然起作用
public final static class VolatileLongPadding {
// public long p1, p2, p3, p4, p5, p6, p7; //填充数据
public volatile long value = 0L; //我们实际要用的数据
volatile long q0, q1, q2, q3, q4, q5, q6; //填充数据
}
为什么会这样呢??? 欢迎有识之士留言告知!!!
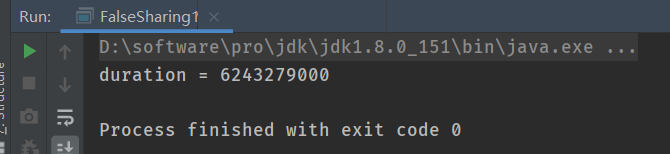
该程序在我电脑上的运行时间为:6243279000毫秒 —> 可以看到执行时间差不多仅为2.1的1/5
2.3 通过java8新特性@sun.misc.Contended注解进行数据填充的效率验证
填充方法:将2.1中的VolatileLong内部类,修改为如下类即可:
/**
* jdk8新特性,Contended注解避免false sharing
* Restricted on user classpath
* VM options: -XX:-RestrictContended
*/
@sun.misc.Contended
public final static class VolatileLongAnno {
public volatile long value = 0L;
}
同时要注意: 需要在jvm启动时设置-XX:-RestrictContended参数才可以生效
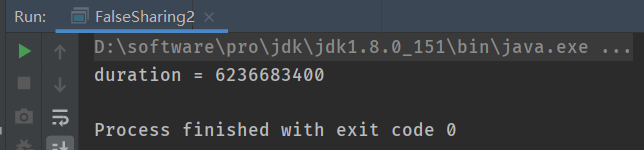
该程序在我电脑上的运行时间为:6236683400毫秒 —> 可以看到执行时间和手动进行数据填充差不多
多说一句,JDK的ConcurrentHashMap中就使用了 @sun.misc.Contended注解
由2.1、2.2、2.3可知数据填充确实能解决伪共享问题。
