数据是数据分析师的招聘薪资,主要内容是进行数据读取,数据概述,数据清洗和整理,以及数据分析和可视化。
一、数据读取
import pandas as pd
import numpy as np
df = pd.read_csv("C:\\Users\\10237\\Desktop\\第四阶段培训excel\\DataAnalyst.csv",encoding = "gb2312")
df
| city | companyFullName | companyId | companyLabelList | companyShortName | companySize | businessZones | firstType | secondType | education | industryField | positionId | positionAdvantage | positionName | positionLables | salary | workYear | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 上海 | 纽海信息技术(上海)有限公司 | 8581 | ['技能培训', '节日礼物', '带薪年假', '岗位晋升'] | 1号店 | 2000人以上 | ['张江'] | 技术 | 数据开发 | 硕士 | 移动互联网 | 2537336 | 知名平台 | 数据分析师 | ['分析师', '数据分析', '数据挖掘', '数据'] | 7k-9k | 应届毕业生 |
| 1 | 上海 | 上海点荣金融信息服务有限责任公司 | 23177 | ['节日礼物', '带薪年假', '岗位晋升', '扁平管理'] | 点融网 | 500-2000人 | ['五里桥', '打浦桥', '制造局路'] | 技术 | 数据开发 | 本科 | 金融 | 2427485 | 挑战机会,团队好,与大牛合作,工作环境好 | 数据分析师-CR2017-SH2909 | ['分析师', '数据分析', '数据挖掘', '数据'] | 10k-15k | 应届毕业生 |
| 2 | 上海 | 上海晶樵网络信息技术有限公司 | 57561 | ['技能培训', '绩效奖金', '岗位晋升', '管理规范'] | SPD | 50-150人 | ['打浦桥'] | 设计 | 数据分析 | 本科 | 移动互联网 | 2511252 | 时间自由,领导nic | 数据分析师 | ['分析师', '数据分析', '数据'] | 4k-6k | 应届毕业生 |
| 3 | 上海 | 杭州数云信息技术有限公司上海分公司 | 7502 | ['绩效奖金', '股票期权', '五险一金', '通讯津贴'] | 数云 | 150-500人 | ['龙华', '上海体育场', '万体馆'] | 市场与销售 | 数据分析 | 本科 | 企业服务,数据服务 | 2427530 | 五险一金 绩效奖金 带薪年假 节日福利 | 大数据业务分析师【数云校招】 | ['商业', '分析师', '大数据', '数据'] | 6k-8k | 应届毕业生 |
| 4 | 上海 | 上海银基富力信息技术有限公司 | 130876 | ['年底双薪', '通讯津贴', '定期体检', '绩效奖金'] | 银基富力 | 15-50人 | ['上海影城', '新华路', '虹桥'] | 技术 | 软件开发 | 本科 | 其他 | 2245819 | 在大牛下指导 | BI开发/数据分析师 | ['分析师', '数据分析', '数据', 'BI'] | 2k-3k | 应届毕业生 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6871 | 北京 | 北京亿盛融华投资管理有限公司 | 151898 | NaN | 亿盛资本 | 150-500人 | NaN | 市场/商务/销售类 | 销售 | 大专 | 金融、教育 | 2469682 | 高薪双休五险一金时间自由朝九晚五 | 金融证券分析师 助理 | ['分析师', '金融', '证券'] | 10K-20K | 不限 |
| 6872 | 北京 | 北京亿盛融华投资管理有限公司 | 151898 | NaN | 亿盛资本 | 150-500人 | NaN | 产品/需求/项目类 | 项目管理 | 大专 | 金融、教育 | 2469686 | 高薪五险一金双休朝九晚五带薪年假20天 | 金融证券分析师 可培训 | ['项目管理', '专员', '助理', '实习生', '风控', '采购', '分析师',... | 15K-30K | 不限 |
| 6873 | 北京 | 北京亿盛融华投资管理有限公司 | 151898 | NaN | 亿盛资本 | 150-500人 | NaN | 其他 | 房地产|建筑业 | 大专 | 金融、教育 | 2470949 | 高薪五险一金双休朝九晚五无加班可培训 | 金融证券分析师 讲师 助理 | ['分析师', '职业培训', '教育', '培训', '金融', '证券', '股票', ... | 15K-30K | 不限 |
| 6874 | 北京 | 北京亿盛融华投资管理有限公司 | 151898 | NaN | 亿盛资本 | 150-500人 | NaN | 市场/商务/销售类 | 销售 | 大专 | 金融、教育 | 2465839 | 高薪 无加班 双休 五险一金 | 金融证券分析师助理讲师助理 | ['实习生', '主管', '经理', '顾问', '销售', '客户代表', '分析师',... | 10K-20K | 不限 |
| 6875 | 北京 | 北京亿盛融华投资管理有限公司 | 151898 | NaN | 亿盛资本 | 150-500人 | NaN | 金融类 | 风控 | 不限 | 金融、教育 | 2471674 | 挑战高薪,挑战自我 | 1W五险双休诚聘金融分析师助理可兼职 | ['分析师', '金融'] | 8K-15K | 不限 |
6876 rows × 17 columns
二、数据浏览
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6876 entries, 0 to 6875
Data columns (total 17 columns):
city 6876 non-null object
companyFullName 6876 non-null object
companyId 6876 non-null int64
companyLabelList 6170 non-null object
companyShortName 6876 non-null object
companySize 6876 non-null object
businessZones 4873 non-null object
firstType 6869 non-null object
secondType 6870 non-null object
education 6876 non-null object
industryField 6876 non-null object
positionId 6876 non-null int64
positionAdvantage 6876 non-null object
positionName 6876 non-null object
positionLables 6844 non-null object
salary 6876 non-null object
workYear 6876 non-null object
dtypes: int64(2), object(15)
memory usage: 913.3+ KB
这里列举出了数据集拥有的各类字段,一共有6876个,其中companyLabelList,businessZones,firstType,secondType,positionLables都存在为空的情况。公司id和职位id为数字,其他都是字符串。
因为数据集的数据比较多,如果我们只想浏览部分的话,可以使用head函数,显示头部的数据,默认5,也可以自由设置参数,如果是尾部数据则是tail。
df.head()
| city | companyFullName | companyId | companyLabelList | companyShortName | companySize | businessZones | firstType | secondType | education | industryField | positionId | positionAdvantage | positionName | positionLables | salary | workYear | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 上海 | 纽海信息技术(上海)有限公司 | 8581 | ['技能培训', '节日礼物', '带薪年假', '岗位晋升'] | 1号店 | 2000人以上 | ['张江'] | 技术 | 数据开发 | 硕士 | 移动互联网 | 2537336 | 知名平台 | 数据分析师 | ['分析师', '数据分析', '数据挖掘', '数据'] | 7k-9k | 应届毕业生 |
| 1 | 上海 | 上海点荣金融信息服务有限责任公司 | 23177 | ['节日礼物', '带薪年假', '岗位晋升', '扁平管理'] | 点融网 | 500-2000人 | ['五里桥', '打浦桥', '制造局路'] | 技术 | 数据开发 | 本科 | 金融 | 2427485 | 挑战机会,团队好,与大牛合作,工作环境好 | 数据分析师-CR2017-SH2909 | ['分析师', '数据分析', '数据挖掘', '数据'] | 10k-15k | 应届毕业生 |
| 2 | 上海 | 上海晶樵网络信息技术有限公司 | 57561 | ['技能培训', '绩效奖金', '岗位晋升', '管理规范'] | SPD | 50-150人 | ['打浦桥'] | 设计 | 数据分析 | 本科 | 移动互联网 | 2511252 | 时间自由,领导nic | 数据分析师 | ['分析师', '数据分析', '数据'] | 4k-6k | 应届毕业生 |
| 3 | 上海 | 杭州数云信息技术有限公司上海分公司 | 7502 | ['绩效奖金', '股票期权', '五险一金', '通讯津贴'] | 数云 | 150-500人 | ['龙华', '上海体育场', '万体馆'] | 市场与销售 | 数据分析 | 本科 | 企业服务,数据服务 | 2427530 | 五险一金 绩效奖金 带薪年假 节日福利 | 大数据业务分析师【数云校招】 | ['商业', '分析师', '大数据', '数据'] | 6k-8k | 应届毕业生 |
| 4 | 上海 | 上海银基富力信息技术有限公司 | 130876 | ['年底双薪', '通讯津贴', '定期体检', '绩效奖金'] | 银基富力 | 15-50人 | ['上海影城', '新华路', '虹桥'] | 技术 | 软件开发 | 本科 | 其他 | 2245819 | 在大牛下指导 | BI开发/数据分析师 | ['分析师', '数据分析', '数据', 'BI'] | 2k-3k | 应届毕业生 |
df.tail()
| city | companyFullName | companyId | companyLabelList | companyShortName | companySize | businessZones | firstType | secondType | education | industryField | positionId | positionAdvantage | positionName | positionLables | salary | workYear | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6871 | 北京 | 北京亿盛融华投资管理有限公司 | 151898 | NaN | 亿盛资本 | 150-500人 | NaN | 市场/商务/销售类 | 销售 | 大专 | 金融、教育 | 2469682 | 高薪双休五险一金时间自由朝九晚五 | 金融证券分析师 助理 | ['分析师', '金融', '证券'] | 10K-20K | 不限 |
| 6872 | 北京 | 北京亿盛融华投资管理有限公司 | 151898 | NaN | 亿盛资本 | 150-500人 | NaN | 产品/需求/项目类 | 项目管理 | 大专 | 金融、教育 | 2469686 | 高薪五险一金双休朝九晚五带薪年假20天 | 金融证券分析师 可培训 | ['项目管理', '专员', '助理', '实习生', '风控', '采购', '分析师',... | 15K-30K | 不限 |
| 6873 | 北京 | 北京亿盛融华投资管理有限公司 | 151898 | NaN | 亿盛资本 | 150-500人 | NaN | 其他 | 房地产|建筑业 | 大专 | 金融、教育 | 2470949 | 高薪五险一金双休朝九晚五无加班可培训 | 金融证券分析师 讲师 助理 | ['分析师', '职业培训', '教育', '培训', '金融', '证券', '股票', ... | 15K-30K | 不限 |
| 6874 | 北京 | 北京亿盛融华投资管理有限公司 | 151898 | NaN | 亿盛资本 | 150-500人 | NaN | 市场/商务/销售类 | 销售 | 大专 | 金融、教育 | 2465839 | 高薪 无加班 双休 五险一金 | 金融证券分析师助理讲师助理 | ['实习生', '主管', '经理', '顾问', '销售', '客户代表', '分析师',... | 10K-20K | 不限 |
| 6875 | 北京 | 北京亿盛融华投资管理有限公司 | 151898 | NaN | 亿盛资本 | 150-500人 | NaN | 金融类 | 风控 | 不限 | 金融、教育 | 2471674 | 挑战高薪,挑战自我 | 1W五险双休诚聘金融分析师助理可兼职 | ['分析师', '金融'] | 8K-15K | 不限 |
三、数据清洗
数据集中,最主要的脏数据是薪资这块,后续我们要拆成单独的两列。
看一下是否有重复的数据。
len(df.positionId.unique())
5031
unique函数可以返回唯一值,数据集中positionId是职位ID,值唯一。配合len函数计算出唯一值共有5031个,说明有多出来的重复值。
使用drop_duplicates清洗掉。
df_duplicates = df.drop_duplicates(subset = "positionId",keep = "first")
drop_duplicates函数通过subset参数选择以哪个列为去重基准。keep参数则是保留方式,first是保留第一个,删除后余重复值,last还是删除前面,保留最后一个。duplicated函数功能类似,但它返回的是布尔值。
df_duplicates.head()
| city | companyFullName | companyId | companyLabelList | companyShortName | companySize | businessZones | firstType | secondType | education | industryField | positionId | positionAdvantage | positionName | positionLables | salary | workYear | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 上海 | 纽海信息技术(上海)有限公司 | 8581 | ['技能培训', '节日礼物', '带薪年假', '岗位晋升'] | 1号店 | 2000人以上 | ['张江'] | 技术 | 数据开发 | 硕士 | 移动互联网 | 2537336 | 知名平台 | 数据分析师 | ['分析师', '数据分析', '数据挖掘', '数据'] | 7k-9k | 应届毕业生 |
| 1 | 上海 | 上海点荣金融信息服务有限责任公司 | 23177 | ['节日礼物', '带薪年假', '岗位晋升', '扁平管理'] | 点融网 | 500-2000人 | ['五里桥', '打浦桥', '制造局路'] | 技术 | 数据开发 | 本科 | 金融 | 2427485 | 挑战机会,团队好,与大牛合作,工作环境好 | 数据分析师-CR2017-SH2909 | ['分析师', '数据分析', '数据挖掘', '数据'] | 10k-15k | 应届毕业生 |
| 2 | 上海 | 上海晶樵网络信息技术有限公司 | 57561 | ['技能培训', '绩效奖金', '岗位晋升', '管理规范'] | SPD | 50-150人 | ['打浦桥'] | 设计 | 数据分析 | 本科 | 移动互联网 | 2511252 | 时间自由,领导nic | 数据分析师 | ['分析师', '数据分析', '数据'] | 4k-6k | 应届毕业生 |
| 3 | 上海 | 杭州数云信息技术有限公司上海分公司 | 7502 | ['绩效奖金', '股票期权', '五险一金', '通讯津贴'] | 数云 | 150-500人 | ['龙华', '上海体育场', '万体馆'] | 市场与销售 | 数据分析 | 本科 | 企业服务,数据服务 | 2427530 | 五险一金 绩效奖金 带薪年假 节日福利 | 大数据业务分析师【数云校招】 | ['商业', '分析师', '大数据', '数据'] | 6k-8k | 应届毕业生 |
| 4 | 上海 | 上海银基富力信息技术有限公司 | 130876 | ['年底双薪', '通讯津贴', '定期体检', '绩效奖金'] | 银基富力 | 15-50人 | ['上海影城', '新华路', '虹桥'] | 技术 | 软件开发 | 本科 | 其他 | 2245819 | 在大牛下指导 | BI开发/数据分析师 | ['分析师', '数据分析', '数据', 'BI'] | 2k-3k | 应届毕业生 |
df_duplicates.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 5031 entries, 0 to 6766
Data columns (total 17 columns):
city 5031 non-null object
companyFullName 5031 non-null object
companyId 5031 non-null int64
companyLabelList 4529 non-null object
companyShortName 5031 non-null object
companySize 5031 non-null object
businessZones 3535 non-null object
firstType 5027 non-null object
secondType 5028 non-null object
education 5031 non-null object
industryField 5031 non-null object
positionId 5031 non-null int64
positionAdvantage 5031 non-null object
positionName 5031 non-null object
positionLables 5007 non-null object
salary 5031 non-null object
workYear 5031 non-null object
dtypes: int64(2), object(15)
memory usage: 707.5+ KB
接下来加工salary薪资字段。目的是计算出薪资下限以及薪资上限。薪资内容没有特殊的规律,既有小写k,也有大小K,还有「k以上」这种写法,k以上只能上下限默认相同。
我们定义了个cut_word函数,它查找「-」符号所在的位置,并且截取薪资范围开头至K之间的数字,也就是我们想要的薪资下限。apply将cut_word函数应用在salary列的所有行。
但是[k以上]这类没有“-”怎么处理呢?find函数找不到该符号会返回-1,所以这里使用一个if函数加以判断
因为python大小写敏感,我们用upper函数将k都转换为K,然后以K作为截取。
薪资上限topsalary的思路也相近,只是变成截取后半部分。在cut_word函数增加了新的参数用以判断返回bottom还是top。
def cut_word(word,method):
position = word.find ("-")
if position != -1:
bottomsalary = word[:position-1]
topsalary = word[position+1:len(word)-1]
else:
bottomsalary = word[:word.upper().find("K")]
topsalary = bottomsalary
if method == "bottom":
return bottomsalary
else:
return topsalary
df_duplicates["bottomsalary"] = df_duplicates.salary.apply(cut_word,method = "bottom")
D:\anaconda\lib\site-packages\ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
"""Entry point for launching an IPython kernel.
df_duplicates["topsalary"] = df_duplicates.salary.apply(cut_word,method = "top")
D:\anaconda\lib\site-packages\ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
"""Entry point for launching an IPython kernel.
此时df_duplicates已经增加了两个字段,一个是bottomsalary,一个是topsalary,也就是最低和最高薪资
再分别把它们的数据类型转换成数字“int”,并计算平均薪资
df_duplicates.bottomsalary.astype("int")
0 7
1 10
2 4
3 6
4 2
..
6054 15
6330 15
6465 30
6605 4
6766 15
Name: bottomsalary, Length: 5031, dtype: int32
df_duplicates.topsalary.astype("int")
0 9
1 15
2 6
3 8
4 3
..
6054 25
6330 30
6465 40
6605 6
6766 30
Name: topsalary, Length: 5031, dtype: int32
注意,到这里为止只是把两列的数据类型预览为数字而已,其本身真正的数据类型并没有发生变化,要想改变其本身的数据类型,需要重新对其进行赋值,如下操作:
df_duplicates["bottomsalary"] = df_duplicates.bottomsalary.astype("int")
df_duplicates["topsalary"] = df_duplicates.topsalary.astype("int")
D:\anaconda\lib\site-packages\ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
"""Entry point for launching an IPython kernel.
D:\anaconda\lib\site-packages\ipykernel_launcher.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
此时两列的数据类型才更改为数字,使用lambda匿名函数计算平均薪资如下,lambda x: ******* ,前面的lambda x:理解为输入,后面的星号区域则是针对输入的x进行运算。案例中,因为同时对top和bottom求平均值,所以需要加上x.bottomSalary和x.topSalary。其中axis=1是对行进行操作,axis=0是对列进行操作。
df_duplicates.avgsalary = df_duplicates.apply(lambda x:(x.bottomsalary+x.topsalary)/2,axis=1)
df_duplicates.avgsalary
0 8.0
1 12.5
2 5.0
3 7.0
4 2.5
...
6054 20.0
6330 22.5
6465 35.0
6605 5.0
6766 22.5
Name: avgsalary, Length: 5031, dtype: float64
df_duplicates.head()
| city | companyFullName | companyId | companyLabelList | companyShortName | companySize | businessZones | firstType | secondType | education | industryField | positionId | positionAdvantage | positionName | positionLables | salary | workYear | bottomsalary | topsalary | avgsalary | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 上海 | 纽海信息技术(上海)有限公司 | 8581 | ['技能培训', '节日礼物', '带薪年假', '岗位晋升'] | 1号店 | 2000人以上 | ['张江'] | 技术 | 数据开发 | 硕士 | 移动互联网 | 2537336 | 知名平台 | 数据分析师 | ['分析师', '数据分析', '数据挖掘', '数据'] | 7k-9k | 应届毕业生 | 7 | 9 | 8.0 |
| 1 | 上海 | 上海点荣金融信息服务有限责任公司 | 23177 | ['节日礼物', '带薪年假', '岗位晋升', '扁平管理'] | 点融网 | 500-2000人 | ['五里桥', '打浦桥', '制造局路'] | 技术 | 数据开发 | 本科 | 金融 | 2427485 | 挑战机会,团队好,与大牛合作,工作环境好 | 数据分析师-CR2017-SH2909 | ['分析师', '数据分析', '数据挖掘', '数据'] | 10k-15k | 应届毕业生 | 10 | 15 | 12.5 |
| 2 | 上海 | 上海晶樵网络信息技术有限公司 | 57561 | ['技能培训', '绩效奖金', '岗位晋升', '管理规范'] | SPD | 50-150人 | ['打浦桥'] | 设计 | 数据分析 | 本科 | 移动互联网 | 2511252 | 时间自由,领导nic | 数据分析师 | ['分析师', '数据分析', '数据'] | 4k-6k | 应届毕业生 | 4 | 6 | 5.0 |
| 3 | 上海 | 杭州数云信息技术有限公司上海分公司 | 7502 | ['绩效奖金', '股票期权', '五险一金', '通讯津贴'] | 数云 | 150-500人 | ['龙华', '上海体育场', '万体馆'] | 市场与销售 | 数据分析 | 本科 | 企业服务,数据服务 | 2427530 | 五险一金 绩效奖金 带薪年假 节日福利 | 大数据业务分析师【数云校招】 | ['商业', '分析师', '大数据', '数据'] | 6k-8k | 应届毕业生 | 6 | 8 | 7.0 |
| 4 | 上海 | 上海银基富力信息技术有限公司 | 130876 | ['年底双薪', '通讯津贴', '定期体检', '绩效奖金'] | 银基富力 | 15-50人 | ['上海影城', '新华路', '虹桥'] | 技术 | 软件开发 | 本科 | 其他 | 2245819 | 在大牛下指导 | BI开发/数据分析师 | ['分析师', '数据分析', '数据', 'BI'] | 2k-3k | 应届毕业生 | 2 | 3 | 2.5 |
到此,数据清洗的部分完成。切选出我们想要的内容进行后续分析。
四、数据分析
df_clean = df_duplicates[["city","companyShortName","companySize",
"education","positionName","positionLables",
"workYear","avgsalary"]]
df_clean.head()
| city | companyShortName | companySize | education | positionName | positionLables | workYear | avgsalary | |
|---|---|---|---|---|---|---|---|---|
| 0 | 上海 | 1号店 | 2000人以上 | 硕士 | 数据分析师 | ['分析师', '数据分析', '数据挖掘', '数据'] | 应届毕业生 | 8.0 |
| 1 | 上海 | 点融网 | 500-2000人 | 本科 | 数据分析师-CR2017-SH2909 | ['分析师', '数据分析', '数据挖掘', '数据'] | 应届毕业生 | 12.5 |
| 2 | 上海 | SPD | 50-150人 | 本科 | 数据分析师 | ['分析师', '数据分析', '数据'] | 应届毕业生 | 5.0 |
| 3 | 上海 | 数云 | 150-500人 | 本科 | 大数据业务分析师【数云校招】 | ['商业', '分析师', '大数据', '数据'] | 应届毕业生 | 7.0 |
| 4 | 上海 | 银基富力 | 15-50人 | 本科 | BI开发/数据分析师 | ['分析师', '数据分析', '数据', 'BI'] | 应届毕业生 | 2.5 |
先对数据进行几个描述统计:
df_clean.city.value_counts()
北京 2347
上海 979
深圳 527
杭州 406
广州 335
成都 135
南京 83
武汉 69
西安 38
苏州 37
厦门 30
长沙 25
天津 20
Name: city, dtype: int64
value_counts是计数,统计所有非零元素的个数,以降序的方式输出Series。数据中可以看到北京招募的数据分析师是最多的。
我们可以依次分析数据分析师的学历要求,工作年限要求。
df_clean.education.value_counts()
本科 3835
大专 615
硕士 288
不限 287
博士 6
Name: education, dtype: int64
可见,对数据分析师的学历要求是本科的最多数,其次是大专。
df_clean.workYear.value_counts()
3-5年 1849
1-3年 1657
不限 728
5-10年 592
应届毕业生 135
1年以下 52
10年以上 18
Name: workYear, dtype: int64
可见,对数据分析师3-5年的工作经验需求是最多的,其次是1-3年。
针对数据分析师的薪资,我们用describe函数。
df_clean.describe()
| avgsalary | |
|---|---|
| count | 5031.000000 |
| mean | 17.111409 |
| std | 8.996242 |
| min | 1.500000 |
| 25% | 11.500000 |
| 50% | 15.000000 |
| 75% | 22.500000 |
| max | 75.000000 |
它能快速生成各类统计指标。数据分析师的薪资的平均数是17k,中位数是15k,两者相差不大,最大薪资在75k,应该是数据科学家或者数据分析总监档位的水平。标准差在8.99k,有一定的波动性,大部分分析师薪资在17+—9k之间。
五、数据可视化
import matplotlib as plt
%matplotlib inline
plt.style.use("ggplot")
pandas自带绘图函数,它是以matplotlib包为基础封装,所以两者能够结合使用。%matplotlib inline是jupyter自带的方式,允许图表在cell中输出。plt.style.use(‘ggplot’)使用R语言中的ggplot2配色作为绘图风格,纯粹为了好看。
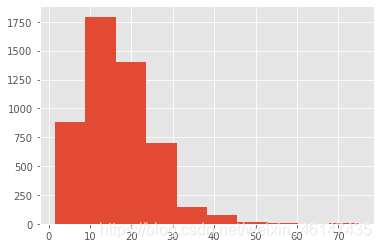
df_clean.avgsalary.hist()
<matplotlib.axes._subplots.AxesSubplot at 0x21995dde088>
 g)]
g)]
图表列出了数据分析师薪资的分布,因为大部分薪资集中20k以下,为了更细的粒度。将直方图的宽距继续缩小。
df_clean.avgsalary.hist(bins=15)
<matplotlib.axes._subplots.AxesSubplot at 0x21995f91f88>
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I7IDCjpx-1584262605329)(output_59_1.png)]](https://img-blog.csdnimg.cn/20200315170621149.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NjE0NzQzNQ==,size_16,color_FFFFFF,t_70)
数据分布呈双峰状,因为原始数据来源于招聘网站的爬取,薪资很容易集中在某个区间,不是真实薪资的反应(10~20k的区间,以本文的计算公式,只会粗暴地落在15k,而非均匀分布)。
现在观察不同城市、不同学历对薪资的影响。箱线图是最佳的观测方式。
df_clean.boxplot(column = "avgsalary",by = "city",figsize = (9,7))
<matplotlib.axes._subplots.AxesSubplot at 0x2199572c308>
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 19978 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 28023 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 21271 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 20140 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 21335 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 21414 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 38376 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 22825 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 27941 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 24191 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 24030 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 25104 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 37117 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 26477 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 27494 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 27721 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 28145 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 22323 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 33487 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 35199 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 23433 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 38271 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:211: RuntimeWarning: Glyph 27801 missing from current font.
font.set_text(s, 0.0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 19978 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 28023 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 21271 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 20140 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 21335 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 21414 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 38376 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 22825 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 27941 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 24191 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 24030 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 25104 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 37117 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 26477 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 27494 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 27721 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 28145 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 22323 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 33487 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 35199 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 23433 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 38271 missing from current font.
font.set_text(s, 0, flags=flags)
D:\anaconda\lib\site-packages\matplotlib\backends\backend_agg.py:180: RuntimeWarning: Glyph 27801 missing from current font.
font.set_text(s, 0, flags=flags)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VeEW5LIP-1584262605330)(output_62_2.png)]](https://img-blog.csdnimg.cn/20200315170830837.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NjE0NzQzNQ==,size_16,color_FFFFFF,t_70)
图表的标签出了问题,出现了白框,主要是图表默认用英文字体,而这里的都是中文,导致了冲突。所以需要改用matplotlib。
from matplotlib.font_manager import FontProperties
font_zh = FontProperties(fname = "c:/msyh.ttf")
ax = df_clean.boxplot(column = "avgsalary",by = "city",figsize = (9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(font_zh)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rRlTO0gW-1584262605334)(output_64_0.png)]](https://img-blog.csdnimg.cn/20200315170900891.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NjE0NzQzNQ==,size_16,color_FFFFFF,t_70)
首先加载字体管理包,设置一个载入中文字体的变量,不同系统的路径不一样。boxplot是我们调用的箱线图函数,column选择箱线图的数值,by是选择分类变量,figsize是尺寸。
ax.get_xticklabels获取坐标轴刻度,即无法正确显示城市名的白框,利用set_fontpeoperties更改字体。于是获得了我们想要的箱线图。
从图上我们看到,北京的数据分析师薪资高于其他城市,尤其是中位数。上海和深圳稍次,广州甚至不如杭州。
ax = df_clean.boxplot(column = "avgsalary",by = "education",figsize = (9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(font_zh)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vinw6o1J-1584262605336)(output_67_0.png)]](https://img-blog.csdnimg.cn/2020031517093434.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NjE0NzQzNQ==,size_16,color_FFFFFF,t_70)
从学历看,博士薪资遥遥领先,虽然在top区域不如本科和硕士,这点我们要后续分析。大专学历稍有弱势。
ax = df_clean.boxplot(column = "avgsalary",by = "workYear",figsize = (9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(font_zh)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T0Iwc8go-1584262605356)(output_69_0.png)]](https://img-blog.csdnimg.cn/20200315170959348.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NjE0NzQzNQ==,size_16,color_FFFFFF,t_70)
工作年限看,薪资的差距进一步拉大,毕业生和工作多年的不在一个梯度。虽然没有其他行业的数据对比,但是可以确定,数据分析师的职场上升路线还是挺光明的。
到目前为止,我们了解了城市、年限和学历对薪资的影响,但这些都是单一的变量,现在想知道北京和上海这两座城市,学历对薪资的影响。
这里需要使用isin函数,用来筛选某一列的某些值。
df_sh_bj = df_clean[df_clean["city"].isin(["上海","北京"])]
ax = df_sh_bj.boxplot(column = "avgsalary",by = ["education","city"],figsize = (9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(font_zh)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0ur9wfge-1584262605358)(output_73_0.png)]](https://img-blog.csdnimg.cn/20200315171043757.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NjE0NzQzNQ==,size_16,color_FFFFFF,t_70)
从图上可以看到,不同学历背景下,北京都是稍优于上海的,北京愿意花费更多薪资吸引数据分析师,而在博士这个档次,也是一个大幅度的跨越。我们不妨寻找其中的原因
df_clean.groupby("city")
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000021999691308>
df_clean.groupby("city").count()
| companyShortName | companySize | education | positionName | positionLables | workYear | avgsalary | |
|---|---|---|---|---|---|---|---|
| city | |||||||
| 上海 | 979 | 979 | 979 | 979 | 973 | 979 | 979 |
| 北京 | 2347 | 2347 | 2347 | 2347 | 2336 | 2347 | 2347 |
| 南京 | 83 | 83 | 83 | 83 | 82 | 83 | 83 |
| 厦门 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
| 天津 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
| 广州 | 335 | 335 | 335 | 335 | 333 | 335 | 335 |
| 成都 | 135 | 135 | 135 | 135 | 134 | 135 | 135 |
| 杭州 | 406 | 406 | 406 | 406 | 405 | 406 | 406 |
| 武汉 | 69 | 69 | 69 | 69 | 69 | 69 | 69 |
| 深圳 | 527 | 527 | 527 | 527 | 525 | 527 | 527 |
| 苏州 | 37 | 37 | 37 | 37 | 37 | 37 | 37 |
| 西安 | 38 | 38 | 38 | 38 | 38 | 38 | 38 |
| 长沙 | 25 | 25 | 25 | 25 | 25 | 25 | 25 |
它返回的是不同城市的各列计数结果,因为没有NaN,每列结果都是相等的。现在它和value_counts等价。
df_clean.city.value_counts()
北京 2347
上海 979
深圳 527
杭州 406
广州 335
成都 135
南京 83
武汉 69
西安 38
苏州 37
厦门 30
长沙 25
天津 20
Name: city, dtype: int64
换成mean,计算出了不同城市的平均薪资。因为mean方法只针对数值,而各列中只有avgSalary是数值,于是返回了这个唯一结果。
df_clean.groupby("city").mean()
| avgsalary | |
|---|---|
| city | |
| 上海 | 17.280388 |
| 北京 | 18.688539 |
| 南京 | 10.951807 |
| 厦门 | 10.966667 |
| 天津 | 8.250000 |
| 广州 | 12.702985 |
| 成都 | 12.848148 |
| 杭州 | 16.455665 |
| 武汉 | 11.297101 |
| 深圳 | 17.591082 |
| 苏州 | 14.554054 |
| 西安 | 10.671053 |
| 长沙 | 9.600000 |
df_clean.groupby(["city","education"]).mean()
| avgsalary | ||
|---|---|---|
| city | education | |
| 上海 | 不限 | 14.051471 |
| 博士 | 15.000000 | |
| 大专 | 13.395455 | |
| 本科 | 17.987552 | |
| 硕士 | 19.180000 | |
| 北京 | 不限 | 15.673387 |
| 博士 | 25.000000 | |
| 大专 | 12.339474 | |
| 本科 | 19.435802 | |
| 硕士 | 19.759740 | |
| 南京 | 不限 | 7.000000 |
| 大专 | 9.272727 | |
| 本科 | 11.327869 | |
| 硕士 | 13.500000 | |
| 厦门 | 不限 | 12.500000 |
| 大专 | 6.785714 | |
| 本科 | 11.805556 | |
| 硕士 | 15.750000 | |
| 天津 | 不限 | 3.500000 |
| 大专 | 5.500000 | |
| 本科 | 9.300000 | |
| 广州 | 不限 | 9.250000 |
| 大专 | 8.988095 | |
| 本科 | 14.170259 | |
| 硕士 | 14.571429 | |
| 成都 | 不限 | 10.562500 |
| 大专 | 11.000000 | |
| 本科 | 13.520202 | |
| 硕士 | 12.750000 | |
| 杭州 | 不限 | 18.269231 |
| 大专 | 12.327586 | |
| 本科 | 16.823432 | |
| 硕士 | 20.710526 | |
| 武汉 | 不限 | 10.950000 |
| 大专 | 11.214286 | |
| 本科 | 11.500000 | |
| 硕士 | 7.000000 | |
| 深圳 | 不限 | 15.100000 |
| 博士 | 35.000000 | |
| 大专 | 13.898936 | |
| 本科 | 18.532911 | |
| 硕士 | 18.029412 | |
| 苏州 | 大专 | 14.600000 |
| 本科 | 14.310345 | |
| 硕士 | 16.833333 | |
| 西安 | 不限 | 8.666667 |
| 大专 | 8.150000 | |
| 本科 | 12.208333 | |
| 硕士 | 5.000000 | |
| 长沙 | 不限 | 7.642857 |
| 大专 | 9.000000 | |
| 本科 | 10.633333 | |
| 硕士 | 9.000000 |
按城市和学历分组计算了平均薪资。后面再调用unstack方法,进行行列转置,这样看的就更清楚了。在不同城市中,博士学历最高的薪资在深圳,硕士学历最高的薪资在杭州。北京综合薪资最好。这个分析结论有没有问题呢?不妨先看招聘人数。
df_clean.groupby(["city","education"]).mean().unstack()
| avgsalary | |||||
|---|---|---|---|---|---|
| education | 不限 | 博士 | 大专 | 本科 | 硕士 |
| city | |||||
| 上海 | 14.051471 | 15.0 | 13.395455 | 17.987552 | 19.180000 |
| 北京 | 15.673387 | 25.0 | 12.339474 | 19.435802 | 19.759740 |
| 南京 | 7.000000 | NaN | 9.272727 | 11.327869 | 13.500000 |
| 厦门 | 12.500000 | NaN | 6.785714 | 11.805556 | 15.750000 |
| 天津 | 3.500000 | NaN | 5.500000 | 9.300000 | NaN |
| 广州 | 9.250000 | NaN | 8.988095 | 14.170259 | 14.571429 |
| 成都 | 10.562500 | NaN | 11.000000 | 13.520202 | 12.750000 |
| 杭州 | 18.269231 | NaN | 12.327586 | 16.823432 | 20.710526 |
| 武汉 | 10.950000 | NaN | 11.214286 | 11.500000 | 7.000000 |
| 深圳 | 15.100000 | 35.0 | 13.898936 | 18.532911 | 18.029412 |
| 苏州 | NaN | NaN | 14.600000 | 14.310345 | 16.833333 |
| 西安 | 8.666667 | NaN | 8.150000 | 12.208333 | 5.000000 |
| 长沙 | 7.642857 | NaN | 9.000000 | 10.633333 | 9.000000 |
df_clean.groupby(["city","education"]).avgsalary.count().unstack()
| education | 不限 | 博士 | 大专 | 本科 | 硕士 |
|---|---|---|---|---|---|
| city | |||||
| 上海 | 68.0 | 3.0 | 110.0 | 723.0 | 75.0 |
| 北京 | 124.0 | 2.0 | 190.0 | 1877.0 | 154.0 |
| 南京 | 5.0 | NaN | 11.0 | 61.0 | 6.0 |
| 厦门 | 3.0 | NaN | 7.0 | 18.0 | 2.0 |
| 天津 | 1.0 | NaN | 4.0 | 15.0 | NaN |
| 广州 | 12.0 | NaN | 84.0 | 232.0 | 7.0 |
| 成都 | 8.0 | NaN | 26.0 | 99.0 | 2.0 |
| 杭州 | 26.0 | NaN | 58.0 | 303.0 | 19.0 |
| 武汉 | 10.0 | NaN | 14.0 | 44.0 | 1.0 |
| 深圳 | 20.0 | 1.0 | 94.0 | 395.0 | 17.0 |
| 苏州 | NaN | NaN | 5.0 | 29.0 | 3.0 |
| 西安 | 3.0 | NaN | 10.0 | 24.0 | 1.0 |
| 长沙 | 7.0 | NaN | 2.0 | 15.0 | 1.0 |
这次换成count,我们在groupby后面加一个avgSalary,说明只统计avgSalary的计数结果,不用混入相同数据。图上的结果很明确了,要求博士学历的岗位只有6个,所谓的平均薪资,也只取决于公司开出的价码,波动性很强,毕竟这只是招聘薪资,不代表真实的博士在职薪资。这也解释了上面几个图表的异常。
接下来计算不同公司招聘的数据分析师数量,并且计算平均数。
df_clean.groupby("companyShortName").avgsalary.agg(["count","mean"]).sort_values("count",ascending=False)
| count | mean | |
|---|---|---|
| companyShortName | ||
| 美团点评 | 175 | 21.862857 |
| 滴滴出行 | 64 | 27.351562 |
| 百度 | 44 | 19.136364 |
| 网易 | 36 | 18.208333 |
| 今日头条 | 32 | 17.125000 |
| ... | ... | ... |
| 天宝 | 1 | 22.500000 |
| 天天果园 | 1 | 17.500000 |
| 天地汇 | 1 | 14.000000 |
| 天同 | 1 | 15.000000 |
| 龙浩通信 | 1 | 5.000000 |
2243 rows × 2 columns
这里使用了agg函数,同时传入count和mean方法,然后返回了不同公司的计数和平均值两个结果。所以前文的mean,count,其实都省略了agg。agg除了系统自带的几个函数,它也支持自定义函数。
df_clean.groupby("companyShortName").avgsalary.agg(lambda x :max(x)-min(x))
companyShortName
12580 0.0
12家全国性股份制商业银行之一 0.0
1号店 22.0
2345.com 4.0
360 22.0
...
齐家网 6.0
齐聚科技(原呱呱视频) 0.0
龙信数据 7.0
龙宝斋财富 0.0
龙浩通信 0.0
Name: avgsalary, Length: 2243, dtype: float64
上图用lamba函数,返回了不同公司中最高薪资和最低薪资的差值。
现在我想计算出不同城市,招聘数据分析师需求前5的公司,应该如何处理?agg虽然能返回计数也能排序,但它返回的是所有结果,前五还需要手工计算。能不能直接返回前五结果?当然可以,这里再次请出apply。
def topN(x,n):
counts = x.value_counts()
r = counts.sort_values(ascending = False)
return r[:n]
df_clean.groupby("city").companyShortName.apply(topN,n = 5).head(20)
city
上海 饿了么 23
美团点评 19
买单侠 15
返利网 15
点融网 11
北京 美团点评 156
滴滴出行 60
百度 39
今日头条 32
百度外卖 31
南京 途牛旅游网 8
通联数据 7
中地控股 6
创景咨询 5
亚信 3
厦门 美图公司 4
厦门融通信息技术有限责任公司 2
Datartisan 数据工匠 2
4399 1
光鱼全景 1
Name: companyShortName, dtype: int64
自定义了函数topN,将传入的数据计数,并且从大到小返回前五的数据。然后以city聚合分组,因为求的是前5的公司,所以对companyShortName调用topN函数。
同样的,如果我想知道不同城市,各职位招聘数前五,也能直接调用topN
df_clean.groupby("city").positionName.apply(topN,n = 5).head(20)
city
上海 数据分析师 79
大数据开发工程师 37
数据产品经理 31
大数据工程师 26
需求分析师 20
北京 数据分析师 238
数据产品经理 121
大数据开发工程师 69
分析师 49
数据分析 42
南京 数据分析师 5
大数据开发工程师 5
大数据架构师 3
大数据工程师 3
大数据开发 2
厦门 数据分析专员 3
数据分析师 3
大数据开发工程师 2
数据分析平台开发工程师 1
数据仓库开发工程师 1
Name: positionName, dtype: int64
可见,虽说是数据分析师,但其实有不少的开发工程师,数据产品经理等。这是抓取下来数据的缺点,它反应的不止是数据分析师,而是数据领域。不同的城市的需求不一样,北京各岗位的需求都比上海高。
同样的,如果我想知道不同城市,各工作年限招聘数前五,也能直接调用topN
df_clean.groupby("city").workYear.apply(topN,n = 5).head(20)
city
上海 3-5年 340
1-3年 322
5-10年 138
不限 126
应届毕业生 33
北京 3-5年 900
1-3年 745
不限 353
5-10年 257
应届毕业生 58
南京 3-5年 25
1-3年 24
不限 23
5-10年 5
应届毕业生 4
厦门 1-3年 15
不限 9
3-5年 5
应届毕业生 1
天津 不限 7
Name: workYear, dtype: int64
可见,上海,北京,南京工作年限3-5年的招聘数量最多,其次是1-3年。
类似的,我想知道不同城市,各职位平均薪资前五的公司。
def top1N(x,n):
r = x.sort_values("avgsalary",ascending = False)
return r[:n]
df_clean.groupby("city").apply(top1N,n = 5)
| city | companyShortName | companySize | education | positionName | positionLables | workYear | avgsalary | ||
|---|---|---|---|---|---|---|---|---|---|
| city | |||||||||
| 上海 | 836 | 上海 | 友希科技 | 500-2000人 | 本科 | 大数据架构师(阿里/腾讯/华人文化共同投资) | ['专家', '架构师', '大数据', '数据'] | 5-10年 | 75.0 |
| 844 | 上海 | 复星金服 | 2000人以上 | 硕士 | 数据技术总监 | ['技术总监', '数据'] | 5-10年 | 75.0 | |
| 782 | 上海 | 上海管易云计算软件有限公司 | 150-500人 | 本科 | 大数据架构 | ['大数据', '架构师', '数据'] | 5-10年 | 52.5 | |
| 808 | 上海 | 中金所技术公司 | 150-500人 | 硕士 | 大数据平台技术专家(J10083) | ['平台', '大数据', '数据挖掘', '数据'] | 5-10年 | 50.0 | |
| 767 | 上海 | Maxent | 15-50人 | 本科 | 大数据架构师 | ['大数据', '架构师', '数据'] | 5-10年 | 50.0 | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 长沙 | 4968 | 长沙 | 益丰大药房 | 2000人以上 | 本科 | 统计分析师 | ['分析师'] | 1-3年 | 15.0 |
| 4979 | 长沙 | 天闻数媒 | 150-500人 | 本科 | 大数据开发工程师 | ['大数据', '数据库', '数据'] | 3-5年 | 15.0 | |
| 4973 | 长沙 | 网舜科技 | 50-150人 | 大专 | DBA数据分析师 | ['分析师', '数据分析', '数据库', 'DBA', '数据'] | 3-5年 | 13.5 | |
| 4986 | 长沙 | 自动化所 | 150-500人 | 不限 | 数据应用开发工程师 | ['数据'] | 不限 | 12.5 | |
| 4967 | 长沙 | 北京炬鑫 | 50-150人 | 不限 | 大数据研究经理 | ['大数据', '数据'] | 1-3年 | 12.5 |
65 rows × 8 columns
这里创建了一个top1N的函数,对平均薪资进行排序,再对城市分组调用top1N函数,由于没有指定某一个字段,所以返回的就是所有字段,若只想返回公司名称,则只需要再后面添加字段名即可
df_clean.groupby("city").apply(top1N,n = 5)[["companyShortName","avgsalary"]]
| companyShortName | avgsalary | ||
|---|---|---|---|
| city | |||
| 上海 | 836 | 友希科技 | 75.0 |
| 844 | 复星金服 | 75.0 | |
| 782 | 上海管易云计算软件有限公司 | 52.5 | |
| 808 | 中金所技术公司 | 50.0 | |
| 767 | Maxent | 50.0 | |
| ... | ... | ... | ... |
| 长沙 | 4968 | 益丰大药房 | 15.0 |
| 4979 | 天闻数媒 | 15.0 | |
| 4973 | 网舜科技 | 13.5 | |
| 4986 | 自动化所 | 12.5 | |
| 4967 | 北京炬鑫 | 12.5 |
65 rows × 2 columns
运用group by,我们已经能随意组合不同维度。接下来配合group by作图。
ax = df_clean.groupby("city").mean().plot.bar()
for label in ax.get_xticklabels():
label.set_fontproperties(font_zh)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ATOnT7Y3-1584262605362)(output_105_0.png)]](https://img-blog.csdnimg.cn/20200315171144441.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NjE0NzQzNQ==,size_16,color_FFFFFF,t_70)
多重聚合在作图上面没有太大差异,行列数据转置不要混淆即可。
ax = df_clean.groupby(["city","education"]).mean().unstack().plot.bar(figsize = (14,6))
for label in ax.get_xticklabels():
label.set_fontproperties(font_zh)
ax.legend(prop = font_zh)
<matplotlib.legend.Legend at 0x219990cef88>
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yhRVgGaP-1584262605363)(output_107_1.png)]](https://img-blog.csdnimg.cn/20200315171214538.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NjE0NzQzNQ==,size_16,color_FFFFFF,t_70)
另外一种分析思路是对数据进行深加工。我们将薪资设立出不同的level。
bins = [0,3,5,10,15,20,30,100]
level = ["0-3","3-5","5-10","10-15","15-20","20-30","30+"]
df_clean["level"] = pd.cut(df_clean.avgsalary,bins = bins,labels = level)
D:\anaconda\lib\site-packages\ipykernel_launcher.py:3: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
This is separate from the ipykernel package so we can avoid doing imports until
df_clean[["avgsalary","level"]]
| avgsalary | level | |
|---|---|---|
| 0 | 8.0 | 5-10 |
| 1 | 12.5 | 10-15 |
| 2 | 5.0 | 3-5 |
| 3 | 7.0 | 5-10 |
| 4 | 2.5 | 0-3 |
| ... | ... | ... |
| 6054 | 20.0 | 15-20 |
| 6330 | 22.5 | 20-30 |
| 6465 | 35.0 | 30+ |
| 6605 | 5.0 | 3-5 |
| 6766 | 22.5 | 20-30 |
5031 rows × 2 columns
cut的作用是分桶,它也是数据分析常用的一种方法,将不同数据划分出不同等级,也就是将数值型数据加工成分类数据。cut可以等距划分,传入一个数字就好。这里为了更好的区分,我传入了一组列表进行人工划分,加工成相应的标签。
df_level = df_clean.groupby(["city","level"]).avgsalary.count().unstack()
df_level_prop = df_level.apply(lambda x:x/x.sum(),axis = 1)
ax= df_level_prop.plot.bar(stacked = True,figsize = (14,6))
for label in ax.get_xticklabels():
label.set_fontproperties(font_zh)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3dJAWFJS-1584262605365)(output_112_0.png)]](https://img-blog.csdnimg.cn/20200315171255316.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NjE0NzQzNQ==,size_16,color_FFFFFF,t_70)
用lambda转换百分比,然后作堆积百分比柱形图(matplotlib好像没有直接调用的函数)。这里可以较为清晰的看到不同等级在不同地区的薪资占比。它比箱线图和直方图的好处在于,通过人工划分,具备业务含义。0~3是实习生的价位,3~6是刚毕业没有基础的新人,整理数据那种,6~10是有一定基础的,以此类推。
现在只剩下最后一列数据没有处理,标签数据。
df_clean.positionLables
0 ['分析师', '数据分析', '数据挖掘', '数据']
1 ['分析师', '数据分析', '数据挖掘', '数据']
2 ['分析师', '数据分析', '数据']
3 ['商业', '分析师', '大数据', '数据']
4 ['分析师', '数据分析', '数据', 'BI']
...
6054 ['数据分析', '数据', 'BI', '分析师', '商业智能']
6330 ['专家', '高级', '软件开发']
6465 ['数据挖掘', '数据']
6605 ['顾问', '销售', '分析师']
6766 ['数据仓库', '数据', '建模']
Name: positionLables, Length: 5031, dtype: object
现在的目的是统计数据分析师的标签。它只是看上去干净的数据,元素中的[]是无意义的,它是字符串的一部分,和数组没有关系。
df_clean.positionLables.str[1:-1]
0 '分析师', '数据分析', '数据挖掘', '数据'
1 '分析师', '数据分析', '数据挖掘', '数据'
2 '分析师', '数据分析', '数据'
3 '商业', '分析师', '大数据', '数据'
4 '分析师', '数据分析', '数据', 'BI'
...
6054 '数据分析', '数据', 'BI', '分析师', '商业智能'
6330 '专家', '高级', '软件开发'
6465 '数据挖掘', '数据'
6605 '顾问', '销售', '分析师'
6766 '数据仓库', '数据', '建模'
Name: positionLables, Length: 5031, dtype: object
str方法允许我们针对列中的元素,进行字符串相关的处理,这里的[1:-1]不再是DataFrame和Series的切片,而是对字符串截取,这里把[]都截取掉了。如果漏了str,就变成选取Series第二行至最后一行的数据,切记。
df_clean.positionLables.str[1:-1].str.replace(" ","")
0 '分析师','数据分析','数据挖掘','数据'
1 '分析师','数据分析','数据挖掘','数据'
2 '分析师','数据分析','数据'
3 '商业','分析师','大数据','数据'
4 '分析师','数据分析','数据','BI'
...
6054 '数据分析','数据','BI','分析师','商业智能'
6330 '专家','高级','软件开发'
6465 '数据挖掘','数据'
6605 '顾问','销售','分析师'
6766 '数据仓库','数据','建模'
Name: positionLables, Length: 5031, dtype: object
使用完str后,它返回的仍旧是Series,当我们想要再次用replace去除空格。还是需要添加str的。现在的数据已经干净不少。
df_clean.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 5031 entries, 0 to 6766
Data columns (total 9 columns):
city 5031 non-null object
companyShortName 5031 non-null object
companySize 5031 non-null object
education 5031 non-null object
positionName 5031 non-null object
positionLables 5007 non-null object
workYear 5031 non-null object
avgsalary 5031 non-null float64
level 5031 non-null category
dtypes: category(1), float64(1), object(7)
memory usage: 519.0+ KB
可见positionLables本身有空值,所以要删除,不然容易报错。再次用str.split方法,把元素中的标签按「,」拆分成列表。
word = df_clean.positionLables.str[1:-1].str.replace(" ","")
word.dropna().str.split(",").apply(pd.value_counts)
| '数据' | '数据挖掘' | '数据分析' | '分析师' | '商业' | '大数据' | 'BI' | 'FA' | '实习' | '行业研究' | ... | '安全测试' | '协议分析' | '在线' | '供应链' | '技术岗位' | '云平台' | 'SEM' | 'J2EE' | '文案' | '专利' | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 1.0 | 1.0 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 1.0 | 1.0 | 1.0 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 1.0 | NaN | 1.0 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 1.0 | NaN | NaN | 1.0 | 1.0 | 1.0 | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 1.0 | NaN | 1.0 | 1.0 | NaN | NaN | 1.0 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6054 | 1.0 | NaN | 1.0 | 1.0 | NaN | NaN | 1.0 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 6330 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 6465 | 1.0 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 6605 | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 6766 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5007 rows × 267 columns
通过apply和value_counts函数统计标签数。因为各行元素已经转换成了列表,所以value_counts会逐行计算列表中的标签,apply的灵活性就在于此,它将value_counts应用在行上,最后将结果组成一张新表。
df_word = word.dropna().str.split(",").apply(pd.value_counts)
df_word.unstack().dropna().reset_index().head()
| level_0 | level_1 | 0 | |
|---|---|---|---|
| 0 | '数据' | 0 | 1.0 |
| 1 | '数据' | 1 | 1.0 |
| 2 | '数据' | 2 | 1.0 |
| 3 | '数据' | 3 | 1.0 |
| 4 | '数据' | 4 | 1.0 |
将空值删除,并且重置为DataFrame,此时level_0为标签名,level_1为df_index的索引,也可以认为它对应着一个职位,0是该标签在职位中出现的次数,之前我没有命名,所以才会显示0。部分职位的标签可能出现多次,这里忽略它。
删除线格式 ```python
~~删除线格式~~ ```python
