数字音频简介
模拟信号与数字信号
什么是信号?学术上的标准定义为:信号是信息的载体。例如,司机可以通过红绿灯信号获取当前是否可以通行的信息;人们说话时会发出声音信号,声音信号中就有他想传递的信息;医生可以通过听诊器听到患者的心跳信号,从中获取病理信息。
从数学角度来讲,信号一般可以模拟为拥有一个或多个独立自变量的函数。自变量可以是时间,空间位置,速度等等。
按照自变量和函数值的对应关系对信号进行分类的话,可以将其分为模拟信号和数字信号。如果自变量和函数值都是连续的,那么这样的信号可称为模拟信号(Analog Signals),如下图所示,自变量(时间)和函数值(振幅)都是连续的:

自然界中几乎所有的信号都是模拟信号,如声音,温度,压力等等,因为这些信号都是随着时间的变化而连续变化的。
如果自变量和函数值都是离散的(不连续的),则这样的信号称为数字信号(Digital Signals),如下图所示:

举个简单的例子,汽车在路上行驶,车速本身就是一个模拟信号,因为随着时间变化,车速也是连续变化的。我们可以通过指针仪表盘来模拟车速信号,这种方式也是模拟信号,因为指针仪表盘也是连续变化的,但是如果我们使用数字仪表盘来表示车速,就变成了数字信号,因为数字并不连续。如下图所示。

模拟信号和数字信号在生活中都有应用。**人们一般会用电信号(电流,电磁波等)模拟其他模拟信号,这样产生的电信号同样是模拟信号。**以前的电话,广播,电视使用就是模拟信号。声音和画面本身都是模拟信号,人们使用电信号对其进行模拟,再使用电流或电磁波的方式发射出去,依然是模拟信号(实际原理比这复杂很多,这里不详细介绍了)。
但是模拟信号有一个缺点,就是在传输过程中,抗干扰性比较弱,因为无论是电流还是电磁波,由于其物理特性,都会受到干扰,也会在传播过程中衰减,很容易失真。此时就体现出数字信号的优势了,数字信号由于是离散的值,抗干扰性极强,而且便于存储,传输和分析。在计算机中,都是使用数字信号进行存储和处理的。
要将自然界中的模拟信号转为计算机中的数字信号,需要进行模电转换(A/D转换),下面我们就以声音为例,来介绍这个过程。
要将声音信号转为数字信号,首先要采集原始声音信号,通过麦克风将声音信号转为模拟电信号,有了模拟电信号之后,才可以将其转化为数字信号,这个过程分为三步:
- 采样
- 量化
- 编码
下面逐一讲解。
采样
所谓采样,就是通过周期性地以某一规定间隔截取模拟信号,也就是在时间上将模拟信号离散化,从而将模拟信号变换为数字信号。听上去很费解,我们通过下面的示意图来理解:
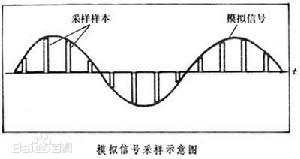
上图中,横轴代表时间,纵轴代表模拟信号值的变化,从中可以看到,每隔固定的时间,截取一次模拟信号的值,这些截取到的值就是采样样本,即数字信号。
每秒从模拟信号中提取并组成离散信号的样本个数被称为采样频率(采样率),单位是 Hz。采样频率的倒数是采样周期或者叫作采样时间,它是样本之间的时间间隔。通俗地讲采样率是指每秒钟采集多少个信号样本。
那么很容易得出结论,采样率越高,得到的离散值就越多,就越接近模拟信号,但同时数据量就越大。那么如何既能减少数据量,又能不丢失信息精度呢?奈奎斯特定理给出了解决方案。
奈奎斯特定理:在进行模拟/数字信号的转换过程中,当采样频率大于信号中最高频率的2倍时,采样之后的数字信号可以完整地保留了原始信号中的信息,奈奎斯特定理又称采样定理。
人能听到的声音的最大频率为 20kHz,对于声音信号的采样,业界大多使用的采样率为 44100Hz,符合奈奎斯特定理。当然也有使用更高的采样率的情况,例如47250Hz,48000Hz等,但是使用 44100Hz 的情况比较常见。
PS. 由于人耳对高频率的声音并不敏感,对于不同的场景的声音质量要求不同,所以采样频率也不同,数字电话的采样率只有11025Hz,数字广播的采样率为22050Hz,而对于对音质要求比较高的音乐CD,会采用44100Hz。
量化
由于模拟信号的值是连续的,我们采样到的这些点理论上来说可能有无限个取值的可能,显然,对无限个样值一一给出数字码来对应是不可能的。为了实现以数字码表示样值,必须采用类似“四舍五入”(实际上并不是四舍五入)的方法把样值分级“取整”,使一定取值范围内的样值由无限多个值变为有限个值。这一过程称为量化。
进行量化时,规定的可取值的个数,则由比特深度决定。比特深度(bit depth,也叫位深度)描述了处理音频数据的硬件或软件能达到的细节精度。计算机中使用二进制,一位就是一个 bit,比特深度为 1,则可以表示两种取值,比特深度为 2,则可以表示 4 种取值,以此类推。
总的来说,更多的比特意味着数据处理后更精确的输出结果。每增加一个比特位,所获得的表示意义的可能性将会翻一倍。如果比特深度为16,那么将获得65536种取值可能性,而24位的比特深度将能够表示16777216种不同的取值。
对于音频采样值的量化,现在常用的比特深度为 16,对于人耳已经足够了。
PS. 量化方式并不是线性的,由于人耳对低频率声音更敏感,所以在几百Hz这个范围的的数值,量化步长可以端一些,对于高频率声音(如超过10000Hz)的量化步长可以取的长一些,这种量化方式称为非线性量化,也是常用的量化方式。
编码
经过采样和量化,模拟信号就被转化为了数字信号,记下来就要进行编码,写入到数字存储设备中,典型的存储设备有 CD,硬盘等等。
由于计算机只支持二进制,需要将数字信号的值转化为为0101的二进制数据才能写入存储设备,这个转化过程就叫编码。在音频领域中,采用的编码技术为 PCM,即脉冲编码调制(Pulse Code Modulation)。除了原始的数字信号值,PCM 编码过程中还会写入一些其他的控制数据,以便于后期处理。经过 PCM 编码后的数字信号,可称为原始数字音频数据,有时也被称为 PCM 数据。
那么1秒钟的声音信号,转化为数字信号之后,是多大的数据量呢?计算方法如下:
数字信号的大小(bit)= 采样率 * 比特深度 * 声道数 * 时间(s)
那么对于采样率 44.1KHz,比特深度16,立体声(双声道)的声音,1秒钟的大小为:44100 * 16 * 2 = 1411200 bit,1 Byte=8bit,即 176400 Byte,那么一分钟的数字信号大小为:176400 * 60 = 10584000 Byte,约等于 10 MB。由于 PCM 编码还会写入控制数据,PCM 数据会比这个值还要再大一些。
那么一首4分钟的歌曲,大小在 40 MB 以上。这和我们认知的一首歌曲的大小不太一样,我们从网络上下载一首歌,一般也就几MB。这是为何呢?
这是因为,PCM 数据太大了,存在 CD 或硬盘上还好,但是如果进行网络传输的,每分钟 10 MB,早些年的带宽承受不了,所以人们发明了压缩技术,将 PCM 数据进行压缩,转化为数据量更小,更易传输,更易存储的数据。常见的压缩技术有:WAV,APE,FLAC,WMA,MP3,AAC,OGG 等等。很多时候,人们把这些音频压缩技术也叫做音频编码技术,这是一种普遍叫法。关于压缩技术,后面我们会进一步介绍。
数字音频处理
声音信号经过编码,转化为 PCM 数据,就可以在计算机中进行存储和处理了。我们可以对这些数字音频进行各种处理,包括变声,混音,消音,剪辑,模拟,传输等等等等。数字音频处理技术在日常生活中非常常见,例如手机K歌中的各种变声,广受欢迎的电子音乐,语音聊天等等,后面我们会介绍其中一部分技术。
数字音频处理是一门及其复杂的技术,即使到了今天,还有很多难题没有解决。例如,PS 技术可以轻易的将图片中的某个人替换成另一个人,但是对于声音,很难在一段音频中将一个人的声音换成另一个人的声音,现在有些技术能够做到,但是还不完美。数字音频处理技术一直在发展,很多难题还需要大量的底层技术研究。
