在多线程并发编程中,volatile 是轻量级的 synchronized,用好 volatile 是 Java 开发的同学必备技能之一。
前言
volatile 是变量修饰符,其修饰的变量具有可见性。在 Java 中为了加快程序的运行效率,对一些变量的操作通常是在寄存器或是 cpu 缓存上进行的,之后才会同步到内存中,而加了 volatile 修饰符的变量则是直接读写内存。可见性也就说一旦某个线程修改了该变量,其他线程读值时可以立即获取修改之后的值。
Java 语言规范第三版中对 volatile 的定义如下:
java 编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致的更新,线程应该确保通过排他锁单独获得这个变量。Java 语言提供了 volatile,在某些情况下比锁更加方便。如果一个字段被声明成 volatile, java 线程内存模型确保所有线程看到这个变量的值是一致的。
一旦一个共享变量(类的成员变量、类的静态成员变量)被 volatile 修饰之后,那么就具备了两层语义:
-
可见性
-
禁止进行指令重排序
可见性
举个栗子,伪代码奉上:
//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2修改stop值
stop = true;
这是一段很典型的多线程代码片段,那么这段代码会发生什么情况呢?
当线程1在运行的时候,会将 stop 变量的值拷贝一份放在自己的工作内存当中。那么当线程2更改了 stop 变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对 stop 变量的更改,因此还会一直循环下去。
聪明的你想必已经猜到了,大声说出来:“while 循环无法停止”。对,你没猜错!是不是感觉很神奇?
其实这里涉及到 JMM(Java 内存模型)
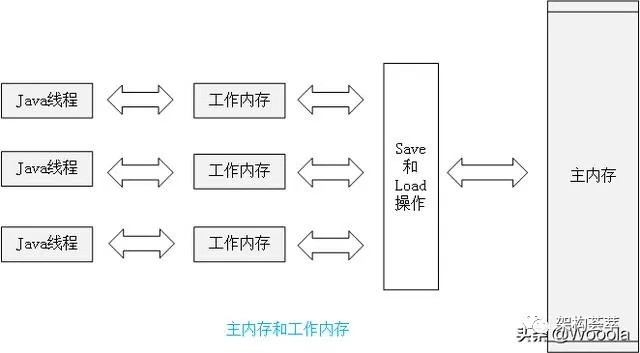
JMM规定
所有的变量都存储在主内存(Main Memory)中。每个线程还有自己的工作内存(Working Memory),线程的工作内存中保存了该线程使用到的变量的主内存的副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量。不同的线程之间也无法直接访问对方工作内存中的变量,线程之间值的传递都需要通过主内存来完成
正因为不同的线程之间也无法直接访问对方工作内存中的变量,所以 volatile 闪亮登场登场登场了。
当线程2 对被 volatile 修饰的 stop 变量进行赋值时并把值写进主内存,会导致线程1的工作内存中缓存变量 stop 的缓存行无效(反映到硬件层的话,就是 CPU 的 L1 或者L2 缓存中对应的缓存行无效),所以线程1再次读取变量 stop 的值时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值,那么线程1读取到的就是最新的正确的值。
这就是 volatile 的可见性。
volatile 的可见性是指当多个线程访问同一个变量(共享变量)时,如果在这期间有某个线程修改了该共享变量的值,那么其他线程能够立即看得到修改后的值。
为什么其他线程可以访问到共享变量修改后的值呢?
这里涉及到 jvm 运行时刻内存的分配:
其中有一个内存区域是 jvm 虚拟机栈,每一个线程运行时都有一个线程栈,线程栈保存了线程运行时候变量值信息。当线程访问某一个对象的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存变量的具体值 load 到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了
也就是说,当一个共享变量被 volatile 修饰时,它会保证修改的值会立即被更新到主内存,当有其他线程需要读取时,它会去主内存中读取最新值。相反,普通的共享变量被修改之后,不能保证及时更新到主内存,导致某些线程读取时还是旧值,因此无法保证其可见性。
计算机处理器怎么保证其可见性的呢?
举个栗子,代码如下:
public class MySingleton {
private static volatile MySingleton instance = null;
public static MySingleton getInstance() {
if (instance == null) {
instance = new MySingleton();
}
return instance;
}
public static void main(String[] args) {
MySingleton.getInstance();
}
}
汇编代码
0x00000000027df0d5: lock add dword ptr [rsp],0h ;*putstatic instance
; - com.dunzung.demo.MySingleton::getInstance@13 (line 9)
有 volatile 变量修饰的共享变量进行写操作的时候会多第一行加 lock 的汇编代码,通过查 IA-32 架构软件开发者手册可知,lock 前缀的指令在多核处理器下会引发了两件事情。
第一、将当前处理器缓存行的数据会写回到系统内存
Lock 前缀指令导致在执行指令期间,声言处理器的 LOCK# 信号。在多处理器环境中,LOCK# 信号确保在声言该信号期间,处理器可以独占使用任何共享内存。(因为它会锁住总线,导致其他CPU不能访问总线,不能访问总线就意味着不能访问系统内存),但是在最近的处理器里,LOCK#信号一般不锁总线,而是锁缓存,毕竟锁总线开销比较大。对于Intel486 和 Pentium 处理器,在锁操作时,总是在总线上声言 LOCK# 信号。但在 P6 和最近的处理器中,如果访问的内存区域已经缓存在处理器内部,则不会声言 LOCK# 信号。相反地,它会锁定这块内存区域的缓存并回写到内存,并使用缓存一致性机制来确保修改的原子性,此操作被称为“缓存锁定”,缓存一致性机制会阻止同时修改被两个以上处理器缓存的内存区域数据。
第二、这个写回内存的操作会引起在其他 CPU 里缓存了该内存地址的数据无效
IA-32 处理器和 Intel 64 处理器使用 MESI(修改,独占,共享,无效)控制协议去维护内部缓存和其他处理器缓存的一致性。在多核处理器系统中进行操作的时候,IA-32 和Intel 64 处理器能嗅探其他处理器访问系统内存和它们的内部缓存。它们使用嗅探技术保证它的内部缓存,系统内存和其他处理器的缓存的数据在总线上保持一致。例如在Pentium 和 P6 family 处理器中,如果通过嗅探一个处理器来检测其他处理器打算写内存地址,而这个地址当前处理共享状态,那么正在嗅探的处理器将无效它的缓存行,在下次访问相同内存地址时,强制执行缓存行填充。
处理器为了提高处理速度,不直接和内存进行通讯,而是先将系统内存的数据读到内部缓存(L1,L2 或其他)后再进行操作,但操作完之后不知道何时会写到内存。
如果对声明了 Volatile 变量进行写操作,JVM 就会向处理器发送一条 Lock 前缀的指令,将这个变量所在缓存行的数据写回到系统内存。但是就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题,所以在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器要对这个数据进行修改操作的时候,会强制重新从系统内存里把数据读到处理器缓存里。
一个处理器的缓存回写到内存会导致其他处理器的缓存无效。IA-32 处理器和 Intel64 处理器使用 MESI(修改,独占,共享,无效)控制协议去维护内部缓存和其他处理器缓存的一致性。在多核处理器系统中进行操作的时候,IA-32 和 Intel 64 处理器能嗅探其他处理器访问系统内存和它们的内部缓存。它们使用嗅探技术保证它的内部缓存,系统内存和其他处理器的缓存的数据在总线上保持一致。
例如在 Pentium 和 P6family 处理器中,如果通过嗅探一个处理器来检测其他处理器打算写内存地址,而这个地址当前处理共享状态,那么正在嗅探的处理器将无效它的缓存行,在下次访问相同内存地址时,强制执行缓存行填充。
