Python——运算符与数据结构
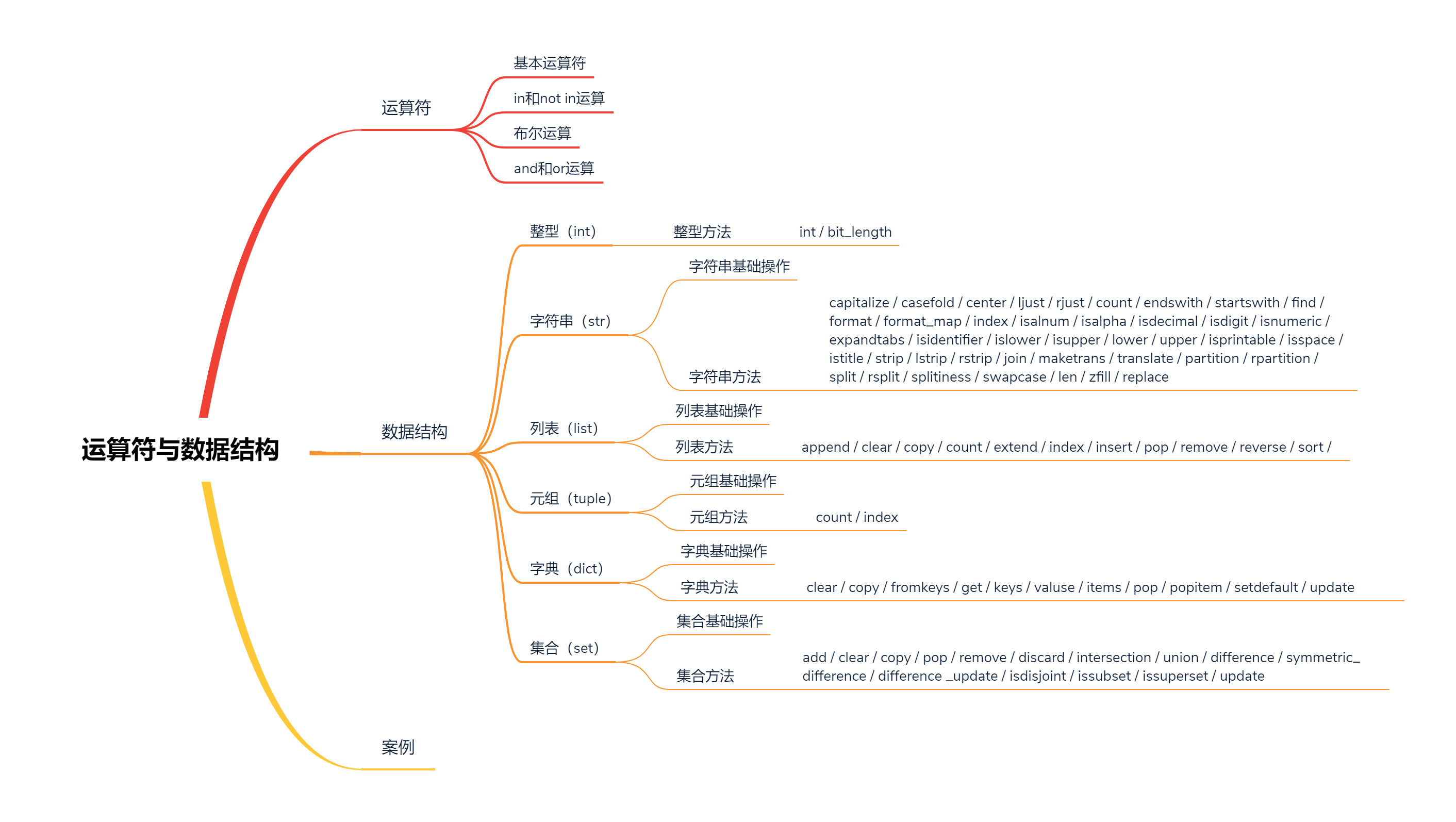
Python——运算符
1.基本运算符——+、-、*、/、**、//
1 # 基本运算符 2 a = 15 3 b = 4 4 print(a+b) # 加 5 # =>19 6 print(a-b) # 减 7 # =>11 8 print(a*b) # 乘 9 # =>60 10 print(a/b) # 除 11 # =>3.75 12 print(a**b) # 幂 13 # =>50625 14 print(a//b) # 取商 15 # =>3
2.in 和 not in 运算
1 # in 和 not in 运算 2 str = '一寸光阴一寸金,寸金难买寸光阴' 3 a = '寸金' 4 if a in str: 5 print(True) 6 else: 7 print(False) 8 # =>True 9 10 b = '寸心金' 11 if b not in str: 12 print(True) 13 else: 14 print(False) 15 # =>True
3.布尔运算——False、True
1 # 布尔运算 2 if True: 3 print(True) 4 else: 5 print(False) 6 # =>True 7 if False: 8 print(True) 9 else: 10 print(False) 11 # =>False
4.and 和 or 运算
1 # and 和 or 运算 2 a = '我' 3 b = '是' 4 c = '英' 5 d = '雄' 6 if a == '我' or (b == '你' and c == '英' )or d == '雄': 7 print(True) 8 else: 9 print(False) 10 # =>True 11 if a == '我' or b == '你' and c == '是' and d == '雄': 12 print(True) 13 else: 14 print(False) 15 # =>True 16 if a == '我' and b == '你' and c == '英' or d == '雄': 17 print(True) 18 else: 19 print(False) 20 # =>True 21 if a == '你' or b == '我' and c =='英' or d == '雄': 22 print(True) 23 else: 24 print(False) 25 # =>True 26 if a == '你' and b == '我' or c == '英' or d == '雄': 27 print(True) 28 else: 29 print(False) 30 # =>True
and 和 or 知识点总结:
1)在判断真假时,有括号先进行括号内的判断;
2)当有多个and 和 or连接时,遵守从前到后的顺序进行;
3)判断结果:
① True or ==> True (当第一个判断结果为True时,后面接or ,则整个判断语句为True)
② True and ==> 继续往下判断 (当第一个判断结果为True时,后面接and ,则继续向下执行,直到整个判断语句结束)
③ False or ==> 继续往下判断 (当第一个判断结果为False时,后面接or ,则继续向下执行,直到整个判断语句结束)
④ False and ==> False (当第一个判断结果为False时,后面接and ,则整个判断语句为False)
Python——数据类型
1.整型(int)
整型就是整数,如:a = 123 、b = 4 等。
1)整型方法
① int() ——将字符串转换为数字
1 num = '124' 2 print(int(num)) 3 # =>124 4 num = 'b' 5 v = int(num,base=16) # 将字符串转换为整形,以16进制的形式进行转换 6 print(v) 7 # =>11
② bit_length() ——将数字转换为二进制位,用多少位表示
1 num = 12 2 v = num.bit_length() # 将数字转换为二进制位,用多少位表示 3 print(v) 4 # =>4
2.字符串(str)
字符串,如:a = '1235'、b = '你真棒'、c = 'I love you !' 等。
1)字符串基础操作
<1> 通过索引下标,获取字符串中的某一个字符
1 test = 'love' #索引下标 2 v = test[1] #取1个 3 print(v) 4 # =>o 5 v1 = test[1:3] #取范围 6 print(v1) 7 # =>ov 8 v2 = test[0:-1] #切片 9 print(v2) 10 # =>lov
<2> 获取字符串中的每一个字符,并且打印出来
1 # 采用while循环 2 test = '人生若只如初见,何事秋风悲画扇' 3 i = 0 4 while i<len(test): 5 print(test[i]) 6 i += 1 7 8 # 采用for循环 9 test = '人生若只如初见,何事秋风悲画扇' 10 for i in test: 11 print(i)
<3> 字符串一旦创建,不可修改.一旦修改或者拼接,都会造成重新生成字符串
<4> 字符串遍历
1 # —字符串遍历 2 test =input('请输入字符串:') 3 4 # for循环可采用break和continue语句 5 for i in test: 6 print(i) 7 break 8 for i in test: 9 continue 10 print(i) 11 12 # range():创建连续的和不连续的数字,可设置步长间隔 13 for i in range(10): 14 print(i) 15 for i in range(0,100,5): 16 print(i) 17 18 # 将文字对应的索引打印出来 19 for i in test: 20 v = test.find(i) 21 print(i,v) # find()查找对应字符串的下标 22 23 l = len(test) 24 print(l) 25 for i in range(l): 26 print(test[i],i) # len()获取字符串长度,然后遍历打印
2)字符串方法
<1> capitalize(self) -> str: ... ——将字符串首字母大写
1 test = 'i love China!,You Love' 2 v = test.capitalize() 3 print(v) 4 # => I love china!,you love 5 test = 'love love' 6 v = test.capitalize() 7 print(v) 8 # => Love love 9 test = 'wo ai zhong guo' 10 v = test.capitalize() 11 print(v) 12 # => Wo ai zhong guo
<2> casefold(self) -> str: .../---lower(self) -> str: ... ——所有字母变小写,casefold更厉害,可以将许多未知变量转换为相对应的小写
1 test = 'inteESTING WONderful' 2 v1 = test.casefold() 3 print(v1) 4 # => inteesting wonderful 5 v2 = test.lower() 6 print(v2) 7 # => inteesting wonderful
<3> center(width,'指定字符')——设置宽度,并将内容居中 width代指总宽度 未填表示空格
<4> ljust(width,'指定字符') —— 设置宽度,将内容居左
<5> rjust(width,'指定字符') ——设置宽度,将内容居右
1 test = 'Love' 2 v1 = test.center(10) 3 v2 = test.ljust(10) 4 v3 = test.rjust(10) 5 print(v1,v2,v3) 6 # => Love Love Love 7 v4 = test.center(20,'@') 8 v5 = test.ljust(20,'@') 9 v6 = test.rjust(20,'@') 10 print(v4,v5,v6) 11 # => @@@@@@@@Love@@@@@@@@ Love@@@@@@@@@@@@@@@@ @@@@@@@@@@@@@@@@Love
<6> count(self, x: Text, __start: Optional[int] = ..., __end: Optional[int] = ...) -> int: ... ——count(查找对象,开始位置,结束位置),count方法表示寻找子序列在字符串中所出现的次数,可以设置开始寻找位置和结束位置。
1 test = 'alexalexdsdg' 2 v = test.count('a',3,8) 3 print(v) 4 # => 1
<7> endswith(self, suffix: Union[Text, Tuple[Text, ...]], start: Optional[int] = ..., end: Optional[int] = ...) -> bool: ... ——endswith()判断在字符串内是否以指定字符结尾
<8> startswith(self, suffix: Union[Text, Tuple[Text, ...]], start: Optional[int] = ..., end: Optional[int] = ...) -> bool: ... ——startswith()判断在字符串内是否以指定字符开始
1 test = 'alexalexdsdg' 2 v1 = test.endswith('a') 3 print(v1) 4 # => False 5 v2 = test.startswith('a') 6 print(v2) 7 # => True
<9> find(self, sub: Text, __start: Optional[int] = ..., __end: Optional[int] = ...) -> int: ... ——find(寻找对象,开始区间,闭合区间)方法,从开始往后找,找到第一个后,获取其位置 >或>=,未找到返回-1
1 test = 'alexalexdsdg' 2 v = test.find('le',4,15) 3 print(v) 4 # => 5
<10> format(self, *args: Any, **kwargs: Any) -> str: ... ——格式化,将一个字符串中的占位符替换为指定的值
1 test = 'i an {name},age {a}' 2 print(test) 3 # => i an {name},age {a} 4 v=test.format(name='feng liang',a=24) 5 print(v) 6 # => i an feng liang,age 24
<11> format_map({key1:value1,key2:value2}) ——格式化,传入的值为字典,同format具有相同功能 eg:{"name":'zhangsan',"a":24}
1 test = 'i am {name},age {a}' 2 v1=test.format(name = 'zhsng san',a = 24) 3 v2=test.format_map({"name":'zhang san',"a":24}) 4 print(v1) 5 # => i am zhsng san,age 24 6 print(v2) 7 # => i am zhand san,age 24
<12> index(self, sub: Text, __start: Optional[int] = ..., __end: Optional[int] = ...) -> int: ... ——寻找对象,寻找指定字符在字符串中的位置,找不到会报错,建议使用find()方法
1 test = 'alexalexdsdg' 2 v = test.index('g') 3 print(v) 4 # => 11
<13> isalnum(self) -> bool: ... ——可用以判断字符串中是否只包含字母和数字
1 test = 'alexalexdsdg455' 2 v = test.isalnum() 3 print(v) 4 # => True 5 test1 = 'alexalexdsdg455_?' 6 v2 = test1.isalnum() 7 print(v2) 8 # => False
<14> isalpha(self) -> bool: ... ——可用以判断字符串中是否只包含字母和汉字
1 test = 'fjsldjgjlj784' 2 v = test.isalpha() 3 print(v) 4 # => False 5 test1 = 'jlkjg你好' 6 v1 = test1.isalpha() 7 print(v1) 8 # => True
<15> isdecimal(self) -> bool: ... ——可用以判断字符串中是否只包含阿拉伯数字(1,2,3,……)
<16> isdigit(self) -> bool: ... ——可用以判断字符串中是否包含数字,特殊数字也可以进行判断
<17> isnumeric(self) -> bool: ... —— 可用以判断字符串中是否只包含数字,既可对特殊数字判断,也可对中文数字判断
1 test = '23435454' 2 v1 = test.isdecimal() 3 v2 = test.isdigit() 4 v3 = test.isnumeric() 5 print(v1,v2,v3) 6 # => True True True 7 test1 = '②' 8 v4 = test1.isdecimal() 9 v5 = test1.isdigit() 10 v6 = test.isnumeric() 11 print(v4,v5,v6) 12 # => False True True 13 test2 = '二' 14 v7 = test2.isdecimal() 15 v8 = test2.isdigit() 16 v9 = test2.isnumeric() 17 print(v7,v8,v9) 18 # => False False True
<18> expandtabs(self, tabsize: int = ...) -> str: ... ——expandtabs(数字):以数字为个数对字符串进行断句,遇到制表符(\t)补空格,可用以制表格
1 test='12345678\t9' 2 v = test.expandtabs(6) #以6个字符为数,遇到制表符补空格 3 print(v) 4 # => 12345678 9 #78+4个空格 5 test='username\temail\tpassword\nlaiying\[email protected]\t123\nlaiying\[email protected]\t123\nlaiying\[email protected]\t123\n' 6 v = test.expandtabs(20) 7 print(v) 8 # => username email password 9 laiying [email protected] 123 10 laiying [email protected] 123 11 laiying [email protected] 123
<19> isidentifier(self) -> bool: ... ——字母、数字、下划线、标识符:def class 判断字符串是否符合规范的变量名称
1 test = 'class' 2 v = test.isidentifier() 3 print(v) 4 # => True 5 test1 = '124dghhg' 6 v1 = test1.isidentifier() 7 print(v1) 8 # => False 9 test2 = '_124dghhg' 10 v2 = test2.isidentifier() 11 print(v2) 12 # => True
<20> islower(self) -> bool: ... ——判断字符串是否都为小写
<21> isupper(self) -> bool: ... ——判断字符串是否都为大写
<22> lower(self) -> str: ... ——将字符串全部转换为小写
<23>.upper(self) -> str: ... ——将字符串全部转换为大写
1 test = 'i LoVE yOu' 2 v1 = test.islower() #判断是否都为小写 3 v2 = test.lower() #全部转换为小写 4 v3 = test.isupper() #判断是否都为大写 5 v4 = test.upper() #全部转换为大写 6 print(v1,v2) 7 # => False i love you 8 print(v3,v4) 9 # => False I LOVE YOU
<24> isprintable(self) -> bool: ... ——可用以判断字符串中是否含有不可显示的字符或符号(不可显示:打印出来不显示,如:'oic\tdgn'中的\t和\n即不可见)
1 test = 'alexAxdsdg你好——\t' 2 v = test.isprintable() 3 print(v) 4 # => False 5 test1 = '78678ghkdhg' 6 v1 = test1.isprintable() 7 print(v1) 8 # => True
<25> isspace(self) -> bool: ... ——判断字符串是否全部都为空格
1 test = ' fsdg' 2 v = test.isspace() 3 print(v) 4 # => False 5 test1 = ' ' 6 v1 = test1.isspace() 7 print(v1) 8 # => True
<26> istitle(self) -> bool: ... ——判断字符串是否为标题,即所有单词首字母大写
1 test = 'I Love You' 2 v = test.istitle() 3 print(v) 4 # => True 5 test1 = 'I love you' 6 v1 = test1.istitle() 7 print(v1) 8 # => False
<27> strip(): ——默认去除字符串左右两端空格,\t、\n、指定字符也可去除
<28> lstrip(): ——默认去除字符串左端空格,\t、\n、指定字符也可去除
<29> rstrip(): ——默认去除字符串右端空格,\t、\n可去除
1 test = ' love ' 2 v = test.strip() #去两端空格 3 v = test.lstrip() #去左边空格 4 v = test.rstrip() #去右边空格 5 print(v) 6 test = 'iloveyoud ' 7 v = test.lstrip('idlov') #去除指定字符,子序列匹配,含有几个去几个,最多匹配 8 print(v) 9 # => eyoud 10 v = test.rstrip('d') 11 print(v) 12 # => iloveyoud #从右边无法去除指定字符
<30> join(self, iterable: Iterable[str]) -> str: ... ——将字符串中的每一个元素按照指定分隔符进行拼接
1 test = '你是风儿我是沙' 2 print(test) 3 # => 你是风儿我是沙 4 t = ' ' #一个空格 5 v = t.join(test) # 6 print(v) 7 # => 你 是 风 儿 我 是 沙
<31> maketrans(): ——进行替换对应
<32> translate(): ——进行替换
1 test1 = 'abcdefg' 2 test2 = '1234567' 3 v = 'i love apple i can fly i eat grass' 4 m = str.maketrans(test1,test2) #进行替换对应 5 new_v = v.translate(m) #进行替换 6 print(new_v) 7 # => i lov5 1ppl5 i 31n 6ly i 51t 7r5ss
<33> partition(): ——根据指定字符对字符串进行分割,保留指定字符,从左边开始,只分三份
<34> rpartition(): ——根据指定字符对字符串进行分割,保留指定字符,从右边开始,只分三份
<35>split('对象','个数'): ——根据指定字符对字符串进行分割,不保留指定字符,从左边开始,可设置分割个数
<36>rsplit('对象','个数'): ——根据指定字符对字符串进行分割,不保留指定字符,从右边开始,可设置分割个数
1 test = 'klagjkjgsdajkjgcadajiiutu' 2 v = test.partition('a') #根据单个‘a’对字符串进行分割,从左边只找第一个,只分三份 3 print(v) 4 # => ('kl', 'a', 'gjkjgsdajkjgcadajiiutu') 5 v = test.rpartition('a') #根据单个‘a’对字符串进行分割,从右边只找第一个,只分三份 6 print(v) 7 # => ('klagjkjgsdajkjgcad', 'a', 'jiiutu') 8 v = test.split('a') #根据全部‘a’对字符串进行分割,分多段 9 print(v) 10 # => ['kl', 'gjkjgsd', 'jkjgc', 'd', 'jiiutu'] 11 v = test.rsplit('a') #根据全部‘a’对字符串进行分割,分多段 12 print(v) 13 # =>['kl', 'gjkjgsd', 'jkjgc', 'd', 'jiiutu']
<37> splitlines(self, keepends: bool = ...) -> List[str]: ... ——对字符串进行分割,只能根据\n进行分割,True,False 表示是否保留换行符\n
1 test = 'dsafsdgdg\ngfdhghgh\ngdgfdhgh' 2 v = test.splitlines(False) 3 print(v) 4 # => ['dsafsdgdg', 'gfdhghgh', 'gdgfdhgh']
<38> swapcase(self) -> str: ... ——大小写转换
1 test = 'fsDG' 2 v = test.swapcase() 3 print(v) 4 # => FSdg
<39> len(): ——判断字符串长度,也可判断列表长度
1 test = '你真棒!' 2 list = [11,22,33,44,55] 3 v = len(test) 4 print(v) 5 # => 4 6 print(len(list)) 7 # => 5
<40> zfill(self, width: int) -> str: ... ——居左只填充0,可设置宽度width
1 test = 'love' 2 v = test.zfill(20) 3 print(v) 4 # => 0000000000000000love
<41> replace(self, old: AnyStr, new: AnyStr, count: int = ...) -> AnyStr: .. ——替换,旧字符串替换新字符串,可设置替换个数
1 test = 'love you love you' 2 v =test.replace('o','m') 3 print(v) 4 # => lmve ymu lmve ymu 5 test = 'love you love you' 6 v =test.replace('o','m',2) #可设置参数,进行替换个数的选择 7 print(v) 8 # => lmve ymu love you
3.列表(list)
- 列表(list):列表由中括号括起,每个元素之间由逗号(,)分隔。如:li = [11,22,33,44,'我','老虎',]
- 列表中可以嵌套任何类型,数字、字符串、元组、列表、字典等等,可以无限嵌套。如:li = [[123,456,789],(1234,5678),{'一':1,'二':2}]
- 列表是有序的,列表元素可以被修改。
1)列表(list)基础操作
<1> 列表取值
1 li = [1,2,3,'sjlajg','你好',['are','you','ok']] 2 # --—索引取值 3 print(li[3]) 4 # =>sjlajg 5 # ——切片取值 6 print(li[2:5]) 7 # =>[3, 'sjlajg', '你好'] 8 print(li[-4:-1]) 9 # =>[3, 'sjlajg', '你好']
<2> for / while 循环
1 li = [1,2,3,'sjlajg','你好',['are','you','ok']] 2 # ——for循环 3 for i in li: 4 print(i) # 遍历列表,将列表中的每一个元素取出 5 # ——while 循环 6 a = 1 7 while a < 5: 8 print(li[a]) 9 a += 1 # 按条件遍历列表
<3> 修改列表
1 li = [1,2,3,'sjlajg','你好',['are','you','ok']] 2 # ——索引修改元素 3 li[1] = '我爱你' 4 print(li) 5 # =>[1, '我爱你', 3, 'sjlajg', '你好', ['are', 'you', 'ok']] 6 # ——切片修改元素 7 li[1:3] = [78,'你真棒'] 8 print(li) 9 # =>[1, 78, '你真棒', 'sjlajg', '你好', ['are', 'you', 'ok']]
<4> 删除元素
1 li = [1,2,3,'sjlajg','你好',['are','you','ok']] 2 # ——del 删除 3 del li[4] 4 print(li) 5 # =>[1, 2, 3, 'sjlajg', ['are', 'you', 'ok']]
<5> in 和 not in 操作
1 # ——in 2 li = [1,2,3,'sjlajg','你好',['are','you','ok']] 3 v = '你好' in li 4 print(v) 5 # =>True 6 b = 100 not in li 7 print(b) 8 # =>True
<6> 列表嵌套取值操作
1 li = [1,2,3,'sjlajg','你好',['are','you',[120,666],'ok']] 2 print(li[5][2][1]) 3 # =>666
<7> 字符串与列表相互转换
1 # ——将字符串转换为列表 2 a = '我是英雄' 3 new_a = list(a) # 字符串转列表,直接用list()转换,内部使用for循环 4 print(new_a) 5 # =>['我', '是', '英', '雄'] 6 # ——将列表转换为字符串 7 # ——<1>for循环,既有数字又有字符串 8 li = [12,3,5,'gf','你好'] 9 v = str(li) # str()整体作为一个字符串 10 print(v) 11 # =>[12, 3, 5, 'gf', '你好'] 12 s = '' 13 for i in li: 14 s += str(i) 15 print(s) 16 # =>1235gf你好 17 # ——<2>join方法拼接,列表中元素只有字符串 18 li = ['hahg','sgb','年后'] 19 v = ''.join(li) 20 print(v) 21 # =>hahgsgb年后
2)列表(list)方法
<1> append(self, object):在列表末尾添加一个元素,需要写参数;
1 li = [11,22,33,44] 2 li.append(5) # 参数,原来值最后追加 3 print(li) 4 # =>[11, 22, 33, 44, 5]
<2> clear(self):清空列表;
1 li = [11,22,33,44] 2 li.clear() 3 print(li) 4 # =>[]
<3> copy(self):拷贝,浅拷贝;
1 li = [11,22,33,44] 2 v = li.copy() 3 print(v) 4 # =>[11, 22, 33, 44]
<4> count(self, objec) :计算列表中元素出现的个数;
1 li = [11,22,33,44,55,66,44] 2 v = li.count(44) 3 print(v) 4 # =>2
<5> extend(self, iterable<可迭代对象>):扩展原来的列表,将可迭代对象(字符串、列表、元组……)一个一个添加到列表中;
1 li = [11,22,33,44] 2 li.extend('我爱你') 3 print(li) 4 # =>[11, 22, 33, 44, '我', '爱', '你'] 5 li1 = [1,23,88,99] # 可用于列表的相加 6 li.extend(li1) 7 print(li) 8 # =>[11, 22, 33, 44, '我', '爱', '你', 1, 23, 88, 99]
<6> index(self, object, start:., stop: ) :根据元素寻找索引,从左往右,只找第一个,可设置开始和结束位置;
1 li = [11,22,33,44,55,66,77,'我是','你',33] 2 v = li.index('你') 3 print(v) 4 # =>8 5 b = li.index(33,4) # 可以设置起始位置 6 print(b) 7 # =>9
<7> insert(self, index, object):在指定索引位置插入元素;
1 li = [11,22,33,44] 2 li.insert(1,99) # 第一个索引位置,第二个元素 3 print(li) 4 # =>[11, 99, 22, 33, 44]
<8> pop(self, index.):删除指定索引下标位置的元素,也可进行指定索引元素的提取,不填默认删除最后一个元素;
1 li = [11,22,33,44] 2 v = li.pop(2) 3 print(v) # 提取元素 4 # =>33 5 print(li) # 删除指定索引下标的元素 6 # =>[11, 22, 44]
<9> remove(self, object):删除指定元素,从左往右,删除第一个出现的元素;
1 li = [11,22,33,44] 2 li.remove(44) 3 print(li) 4 # =>[11, 22, 33]
<10> reverse(self):反转列表,将列表顺序前后颠倒;
1 li = [11,22,33,44] 2 li.reverse() 3 print(li) 4 # =>[44, 33, 22, 11]
<11> sort(self,key,reverse=False):对列表进行排序,默认从小到大,reverse=True 从大到小;
1 li = [11,44,22,55,33] 2 li.sort() # 默认从小到大排序 3 print(li) 4 # =>[11, 22, 33, 44, 55] 5 li1 = [11,44,22,55,33] 6 li1.sort(reverse=True) # 变为从大到小排序 7 print(li1) 8 # =>[55, 44, 33, 22, 11]
4.元组(tuple)
- 元组(tuple):元组由小括号括起,中间由逗号(,)分隔。如:tu = (11,22,33,44,55,66,)。
- 元组是有序的,一级元素不可被修改,不能被增加或删除。
- 一般写元组的时候,最后多加一个逗号。如:tu = (11,22,33,44,55,66,)
- 元组中可以嵌套任何类型,数字、字符串、元组、列表、字典等等,可以无限嵌套。如:tu = (1,2,3,'sjlajg','你好',('are','you',(120,666),'ok',),)。
1)元组(tuple)基础操作
<1> 元组取值
1 tu = (12,46,7,8,'wwe','爱的',) 2 # --—索引取值 3 print(tu[3]) 4 # =>8 5 # ——切片取值 6 print(tu[2:5]) 7 # =>(7, 8, 'wwe') 8 print(tu[-4:-1]) 9 # =>(7, 8, 'wwe')
<2> for 循环,可迭代对象
1 tu = (12,46,7,8,'wwe','爱的',) 2 for i in tu: 3 print(i)
<3> 列表、元组、字符串的相互转换
1 # ——元组转换为列表 2 tu = (12,46,7,8,'wwe','爱的',) 3 li = list(tu) 4 print(li) 5 # =>[12, 46, 7, 8, 'wwe', '爱的'] 6 # ——列表转换为元组 7 li = [12,3,5,6,6] 8 tu = tuple(li) 9 print(tu) 10 # =>(12, 3, 5, 6, 6) 11 # ——字符串转换为元组 12 st = '我是你的苹果' 13 tu = tuple(st) 14 print(tu) 15 # =>('我', '是', '你', '的', '苹', '果') 16 # ——元组转换为字符串 17 # ——<1>for循环,既有数字又有字符串 18 tu = (12,3,5,'gf','你好') 19 v = str(tu) # str()整体作为一个字符串 20 print(v) 21 # =>(12, 3, 5, 'gf', '你好') 22 s = '' 23 for i in tu: 24 s += str(i) 25 print(s) 26 # =>1235gf你好 27 # ——<2>join方法拼接,元组中元素只有字符串 28 tu = ('hahg','sgb','年后') 29 v = ''.join(tu) 30 print(v) 31 # =>hahgsgb年后
<4> 元组嵌套取值操作
1 tu = (1,2,3,'sjlajg','你好',('are','you',(120,666),'ok',)) 2 print(tu[5][2][1]) 3 # =>666
<5> 元组的一级元素不可修改、删除、增加,列表元素可修改
1 tu = (1,2,3,'sjlajg','你好',('are','you',[120,666],'ok',)) 2 tu[5][2][1] = '你真棒' 3 print(tu) 4 # =>(1, 2, 3, 'sjlajg', '你好', ('are', 'you', [120, '你真棒'], 'ok'))
2)元组(tuple)方法
<1> count():计算某个元素的个数;
1 tu = (11,22,33,44,55,44,) 2 v = tu.count(44) 3 print(v) 4 # =>2
<2> index():查找某个元素对应的索引下标,从左到右查找,找寻第一个;
1 tu = (11,22,33,44,55,44,) 2 v = tu.index(55) 3 print(v) 4 # =>4
5.字典(dict)
字典(dict):字典由大括号括起,键值对之间由英文冒号隔开,每个键值对之间由逗号(,)分隔;如:info = {'k1':10,'k2':True,'k3':[11,22,33],'K4':{'a1':110,'b1':[999,1000]},'k5':(12,23,34)}。
字典中可以嵌套任何类型,数字、字符串、元组、列表、字典等等,可以无限嵌套。
布尔值、列表、字典不能作为字典的键(key),字典的值(value)可以为任何类型数据。
字典是无序的,可以进行删除和增加功能。
1)字典(dict)基础操作
<1> 字典取值,通过键(key)取值(value)
1 # ——索引方式找到指定元素,不能用切片方式寻找元素 2 info = {'k1':11,'k2':22,'k3':33,'k4':(44,55),'k5':[66,77,88]} 3 print(info['k1']) 4 # =>11 5 print(info['k4'][1]) 6 # =>55 7 print(info['k5'][2]) 8 # =>88
<2> 字典支持del删除操作
1 info = {'k1':11,'k2':22,'k3':33,'k4':(44,55),'k5':[66,77,88]} 2 del info['k2'] 3 print(info) 4 # =>{'k1': 11, 'k3': 33, 'k4': (44, 55), 'k5': [66, 77, 88]} 5 del info['k5'][1] # 嵌套删除 6 print(info) 7 # =>{'k1': 11, 'k3': 33, 'k4': (44, 55), 'k5': [66, 88]}
<3> for 循环
1 info = {'k1':11,'k2':22,'k3':33,'k4':(44,55),'k5':[66,77,88]} 2 for i in info: # 默认循环键(key0 3 print(i) 4 # =>k1 k2 k3 k4 k5 5 for i in info.keys(): # 循环键(key) 6 print(i) 7 # =>k1 k2 k3 k4 k5 8 for i in info.values(): # 循环值(value) 9 print(i) 10 # =>11 22 33 (44, 55) [66, 77, 88] 11 for i,o in info.items(): # 同时循环键(key)和值(value) 12 print(i,o) 13 # =>k1 11 k2 22 k3 33 k4 (44, 55) k5 [66, 77, 88]
2)字典(dict)方法
<1> clear(self):清空字典
1 info = {'k1':11,'k2':22,'k3':33,'k4':(44,55),'k5':[66,77,88]} 2 info.clear() 3 print(info) 4 # =>{}
<2> copy(self):复制拷贝字典,浅拷贝
1 info = {'k1':11,'k2':22,'k3':33,'k4':(44,55),'k5':[66,77,88]} 2 dic = info.copy() 3 print(dic) 4 # =>{'k1': 11, 'k2': 22, 'k3': 33, 'k4': (44, 55), 'k5': [66, 77, 88]}
<3> fromkeys(*args, **kwargs):根据序列,创建字典,并指定统一的值
1 dic = dict.fromkeys('一',1) # 根据字符串,创建键(key),1为值(value) 2 print(dic) 3 # =>{'一': 1} 4 dic1 = dict.fromkeys(('k1','k2','k3',)) # 根据元组,创建键(key) 5 print(dic1) 6 # =>{'k1': None, 'k2': None, 'k3': None} 7 dic2 = dict.fromkeys(('k1','k2','k3',),111) # 为键统一指定值 8 print(dic2) 9 # =>{'k1': 111, 'k2': 111, 'k3': 111} 10 dic3 = dict.fromkeys(['k1','k2','k3'],111) # 根据列表生成键值对 11 print(dic3) 12 # =>{'k1': 111, 'k2': 111, 'k3': 111} 13 dic4 = dict.fromkeys('我',(111,222)) 14 print(dic4) 15 # =>{'我': (111, 222)} 16 dic5 = dict.fromkeys('我是你',(111,222)) 17 print(dic5) 18 # =>{'我': (111, 222), '是': (111, 222), '你': (111, 222)}
<4> get(self, *args, **kwargs):根据key获取值,key不存在时,返回默认值(None),可以指定任意值
1 info = {'k1':11,'k2':22,'k3':33,'k4':(44,55),'k5':[66,77,88]} 2 v = info.get('你好') # 没有“你好”的键(key),返回None 3 print(v) 4 # =>None 5 v = info.get('k2') # 有键'k2',返回值22 6 print(v) 7 # =>22 8 v = info.get('你好',666) # 没有键“你好”,指定了返回值666,就返回666 9 print(v) 10 # =>666 11 v = info.get('k2',666) # 有键'k2',返回'k2'相对应的值22 12 print(v) 13 # =>22
<5> keys(self): 提取字典的键
<6> values(self): 提取字典的值
<7> items(self): 提取字典的键和值
1 info = {'k1':11,'k2':22,'k3':33,'k4':(44,55),'k5':[66,77,88]} 2 for i in info.keys(): # 循环键(key) 3 print(i) 4 # =>k1 k2 k3 k4 k5 5 for i in info.values(): # 循环值(value) 6 print(i) 7 # =>11 22 33 (44, 55) [66, 77, 88] 8 for i,o in info.items(): # 同时循环键(key)和值(value) 9 print(i,o) 10 # =>k1 11 k2 22 k3 33 k4 (44, 55) k5 [66, 77, 88]
<8> pop(self, k, d=None):删除指定键和对应的值,并且可以获取要删除的键和值
1 info = {'k1':11,'k2':22,'k3':33,'k4':(44,55),'k5':[66,77,88]} 2 v = info.pop('k5') 3 print(v) 4 # =>[66, 77, 88] 5 print(info) 6 # =>{'k1': 11, 'k2': 22, 'k3': 33, 'k4': (44, 55)}
<9> popitem(self): 随机删除一个键值对,也可进行获取其删除掉的键值对
1 info = {'k1':11,'k2':22,'k3':33,'k4':(44,55),'k5':[66,77,88]} 2 v = info.popitem() 3 print(info) 4 # =>{'k1': 11, 'k2': 22, 'k3': 33, 'k4': (44, 55)} 5 print(v) 6 # =>('k5', [66, 77, 88])
<10> setdefault(self, *args, **kwargs):设置值,已存在,不设置,获取key对应的值;不存在,设置,获取当前key对应的值。可用于获取值或添加键和值
1 info = {'k1':11,'k2':22,'k3':33,'k4':(44,55),'k5':[66,77,88]} 2 v = info.setdefault('k1') 3 print(v) 4 # =>11 5 print(info) 6 # =》{'k1': 11, 'k2': 22, 'k3': 33, 'k4': (44, 55), 'k5': [66, 77, 88]} 7 v = info.setdefault('ok','are you') 8 print(v) 9 # =>are you 10 print(info) 11 # =>{'k1': 11, 'k2': 22, 'k3': 33, 'k4': (44, 55), 'k5': [66, 77, 88], 'ok': 'are you'}
<11> update(self, E=None, **F):更新字典
1 info = {'k1':11,'k2':22,'k3':33,'k4':(44,55),'k5':[66,77,88]} 2 info.update({'k1':110,'are':'you ok'}) 3 print(info) 4 # =>{'k1': 110, 'k2': 22, 'k3': 33, 'k4': (44, 55), 'k5': [66, 77, 88], 'are': 'you ok'} 5 info.update(k1=1234,k2=5678,k3=9090) 6 print(info) 7 # =>{'k1': 1234, 'k2': 5678, 'k3': 9090, 'k4': (44, 55), 'k5': [66, 77, 88], 'are': 'you ok'}
6.集合(set)
集合(set):①由不同元素组成、②无序、③集合中元素必须是不可变类型。
集合(set):集合由大括号括起,每个元素之间由逗号分隔:set = {1,2,3,4,5}。
1)集合(set)基础操作
<1> 集合中的元素必须不能重复、是无序的。(如果集合内有重复元素,会自动去重)
1 s = {11,22,33,44,55,55,66,33,77} 2 print(s) 3 # =>{33, 66, 11, 44, 77, 22, 55}
<2> 可以使用set()格式来生成集合,前提必须是可迭代对象。
1 s = set('hello') 2 print(s) 3 # =>{'e', 'o', 'l', 'h'} 4 s = set(['我','是','中','你','是']) 5 print(s) 6 # =>{'你', '我', '是', '中'}
<3> frozenset():生成不可变集合(一旦创建不可被修改,可用于生成字典的键key)
1 s = frozenset('hello') 2 print(s) 3 # =>frozenset({'e', 'l', 'o', 'h'})
<4> 列表、集合去重,不改变顺序
1 li = ['你','爱','我','是','你'] 2 print(list(set(li))) 3 # =>['爱', '你', '我', '是']
2)集合(set)方法
<1> add():添加一个元素
1 s = {11,22,33,44,55} 2 s.add(3) 3 print(s) 4 # =>{33, 3, 11, 44, 22, 55} 5 s.add('是') 6 print(s) 7 # =>{33, 3, 11, 44, '是', 22, 55}
<2> clear():清空元素
1 s = {11,22,33,44,55} 2 s.clear() 3 print(s) 4 # =>set()
<3> copy():复制拷贝,浅拷贝
1 s = {11,22,33,44,55} 2 s1 = s.copy() 3 print(s1) 4 # =>{33, 22, 55, 11, 44}
<4> pop():随机删除元素
1 s = {11,22,33,44,55} 2 s.pop() 3 print(s) 4 # =>{11, 44, 22, 55}
<5> remove():可以删除指定元素,删除不存在的元素会报错
1 s = {11,22,33,44,55,'123','567'} 2 s.remove(33) 3 print(s) 4 # =>{11, 44, '567', '123', 22, 55} 5 s.remove('我是你') 6 print(s) 7 # =>会报错!!!
<6> discard():可以删除指定元素,删除不存在的元素不会报错
1 s = {11,22,33,44,55,'123','567'} 2 s.discard(33) 3 print(s) 4 # =>{'123', 11, 44, '567', 22, 55} 5 s.discard('我是你') 6 print(s) 7 # =>{'123', 11, 44, '567', 22, 55} ===》不会报错!!
<7> intersection()/&:求元素的交集,相当于and
1 s1 = {'张三','李四','王五','刘六','朱二','冯大','黄八'} 2 s2 = {'张三','爱','跳舞','黄八','喜欢','上树'} 3 print(s1,s2) 4 # =>{'王五', '黄八', '朱二', '张三', '李四', '刘六', '冯大'} {'喜欢', '黄八', '上树', '张三', '跳舞', '爱'} 5 print(s1.intersection(s2)) 6 # =>{'黄八', '张三'} 7 print(s1 & s2) 8 # =>{'张三', '黄八'}
<8> union()/|:求元素的并集
1 s1 = {'张三','李四','王五','刘六','朱二','冯大','黄八'} 2 s2 = {'张三','爱','跳舞','黄八','喜欢','上树'} 3 print(s1.union(s2)) 4 # =>{'上树', '黄八', '冯大', '刘六', '朱二', '跳舞', '喜欢', '爱', '张三', '王五', '李四'} 5 print(s1 | s2) 6 # =>{'上树', '黄八', '冯大', '刘六', '朱二', '跳舞', '喜欢', '爱', '张三', '王五', '李四'}
<9> difference()/-:求元素的差集
1 s1 = {'张三','李四','王五','刘六','朱二','冯大','黄八'} 2 s2 = {'张三','爱','跳舞','黄八','喜欢','上树'} 3 print(s1 - s2) 4 # =>{'朱二', '李四', '冯大', '刘六', '王五'} 5 print(s2 - s1) 6 # =>{'跳舞', '爱', '喜欢', '上树'} 7 print(s1.difference(s2)) 8 # =>{'王五', '冯大', '朱二', '李四', '刘六'}
<10> symmetric_difference()/^:求交叉补集,两个集合中去除相同元素,剩余所有元素的集合
1 s1 = {'张三','李四','王五','刘六','朱二','冯大','黄八'} 2 s2 = {'张三','爱','跳舞','黄八','喜欢','上树'} 3 print(s1.symmetric_difference(s2)) 4 # =>{'朱二', '上树', '喜欢', '王五', '跳舞', '冯大', '李四', '刘六', '爱'} 5 print(s1 ^ s2) 6 # =>{'朱二', '上树', '喜欢', '王五', '跳舞', '冯大', '李四', '刘六', '爱'}
<11> difference_update():求完差集后,将值赋给原始集合,原始结合发生变化
1 s1 = {'张三','李四','王五','刘六','朱二','冯大','黄八'} 2 s2 = {'张三','爱','跳舞','黄八','喜欢','上树'} 3 # s1 = s1 - s2 4 # print(s1) 5 # # =>{'朱二', '刘六', '王五', '冯大', '李四'} 6 s1.difference_update(s2) 7 print(s1) 8 # =>{'王五', '冯大', '李四', '刘六', '朱二'}
<12> isdisjoint():两个集合做交集,没有相同元素即为空集合则返回True
1 s1 = {'张三','李四','王五','刘六','朱二','冯大','黄八'} 2 s2 = {'张三','爱','跳舞','黄八','喜欢','上树'} 3 print(s1.isdisjoint(s2)) 4 # =>False # 交集有相同元素,则返回False
<13> issubset():判断一个集合是否是另一个集合的子集
<14> issuperset():判断一个集合是否是另一个集合的父集
1 s1 = {11,22,33,44,55} 2 s2 = {1,2,3,4,5,22} 3 s3 = {22,33} 4 print(s1.issubset(s2)) # 判断s1是不是s2的子集 5 # =>False 6 print(s3.issubset(s1)) # 判断s3是不是s1的子集 7 # =>True 8 print(s1.issubset(s3)) # 判断s1是不是s3的子集 9 # =》False 10 print(s1.issuperset(s3)) # 判断s1是不是s3的父集 11 # =》True
<15> update():将另一个集合更新到一个集合
1 s1 = {11,22,33,44 } 2 s2 = {1,2,3,4,5,66,22} 3 s1.update(s2) 4 print(s1) 5 # =>{33, 1, 2, 3, 4, 5, 66, 11, 44, 22}
案例
1.根据要求实现不同功能
1 name = 'aleX' 2 3 # a.移除 name 变量对应的值两边的空格,并输入移除后的内容 4 v = name.strip() 5 print(v) 6 7 # b.判断 name 变量对应的值是否以“al”开头,并输出结果 8 v = name.startswith('al') 9 print(v) 10 11 # c.判断 name 变量对应的值是否以“X”结尾,并输出结果 12 v = name.endswith('X') 13 print(v) 14 15 # d.将 name 变量对应的值中的“l”替换为"p",并输出结果 16 v = name.replace('l','p') 17 print(v) 18 19 # e.将 name 变量对应的值根据“l”分割,并输出结果 20 v = name.split('l') 21 print(v) 22 23 # f.将 name 变量对应的值变大写,并输出结果 24 v = name.upper() 25 print(v) 26 27 # g.将 name 变量对应的值变小写,并输出结果 28 v = name.lower() 29 print(v) 30 31 #h.请输出 name 变量对应的值的第2个字符? 32 print(name[1]) 33 34 # i.请输出 name 变量对应的值的前3个字符? 35 print(name[0:3]) 36 37 # j.请输出 name 变量对应的值的后2个字符? 38 print(name[-2:]) 39 40 # k.请输出 name 变量对应的值中“e”所在索引位置 41 v = name.find('e') 42 print(v) 43 44 # l.获取子序列,仅不包含最后一个字符,如: oldboy 则获取oldbo ;root 则获取roo 45 print(name[0:-1])
2.将列表的每一个元素拼接成字符串, li = ['alex','eric','rain']
1 li = ['alex','eric','rain'] 2 i ='' 3 v = i.join(li) 4 print(v) 5 # =>alexericrain
3.制作加法计算器
1 content = input('请输入内容:') 2 v = content.split("+") 3 answer = 0 4 i = 0 5 for i in v: 6 m = int(i) 7 answer += m 8 print(answer) 9 # =>请输入内容:34+57+234+878 10 # =>1203
4.计算用户输入的内容中有几个十进制小数,几个字母?
1 1 content = input('请输入内容:') 2 2 num = 0 3 3 letter = 0 4 4 for i in content: 5 5 if i.isdecimal(): 6 6 num += 1 7 7 else: 8 8 letter += 1 9 9 print('数字有:'+str(num) ,'字母有:'+str(letter))
5.制作表格 (循环提示用户输入:用户名、密码、邮箱(要求用户输入的长度不超过20个字符,如果超过则只有前20个字符有效))
1 begin_str = '用户名\t密码\t邮箱\n' 2 jh_str = '' 3 while True: 4 username = input('请输入姓名:') 5 password = input('请输入密码:') 6 email = input('请输入邮箱:') 7 username += '\t' 8 password += '\t' 9 email += '\n' 10 jh_str += username + password + email 11 all_str = begin_str + jh_str 12 again = input('是否继续输入(是/否):') 13 if again == '否': 14 break 15 excel = all_str.expandtabs(20) 16 print(excel) 17 18 ''' =>请输入姓名:张三 19 请输入密码:123456 20 请输入邮箱:[email protected] 21 是否继续输入(是/否):是 22 请输入姓名:李四 23 请输入密码:789987 24 请输入邮箱:[email protected] 25 是否继续输入(是/否):否 26 用户名 密码 邮箱 27 张三 123456 [email protected] 28 李四 789987 [email protected] 29 '''
6.输入一行字符串, 分别统计出其中英文字母、空格、数字和其它字符的个数。
1 def tj_num(str_zfc): # 定义一个统计字符函数 2 shuzi = 0 # 数字 3 ywen = 0 # 英文字母 4 kge = 0 # 空格 5 other = 0 # 其他 6 for i in str_zfc: # 遍历字符串中的每个字符 7 if i.isdecimal(): # 判断字符是否是数字 8 shuzi += 1 9 elif i.isalpha(): # 判断字符是否是英文 10 ywen += 1 11 elif i.isspace(): # 判断字符是否是空格 12 kge += 1 13 else: # 其他 14 other += 1 15 print_gs = '字符串中含有英文字母:%d个 数字:%d个 空格:%d个 其它字符:%d个' %(ywen,shuzi,kge,other) 16 return print_gs 17 print('----------字符串字符种类统计----------') 18 str_sr = input('输入字符串''\n''>>>') 19 v = tj_num(str_sr) 20 print(v) 21 # ----------字符串字符种类统计---------- 22 # 输入字符串 23 # >>>asdfghjkl;',./ 1234567890 24 # 字符串中含有英文字母:9个 数字:10个 空格:1个 其它字符:5个
7.有如下值集合[11,22,33,44,55,66,77,88,99,00],将所有大于66的值保存至字典的第一个key中,将小于66值保存至第二个key的值中。
1 dic = {} 2 li = [11,22,33,44,55,66,77,88,99,00] 3 li1 = [] 4 li2 = [] 5 for i in li: 6 if i > 66: 7 li1.append(i) 8 else: 9 li2.append(i) 10 dic.update(k1=li1,k2=li2) 11 print(dic) 12 # =>{'k1': [77, 88, 99], 'k2': [11, 22, 33, 44, 55, 66, 0]}
8. 26.有两个列表
1)l1 = [11,22,33]
2)l2 = [22,33,44]
①获取内容相同的元素
②获取l1中有,l2中没有的元素列表
③获取l2中有,l1中没有的元素列表
④获取l1和l2中内容都不同的元素
1 # 方法一: 2 l1 = [11,22,33] 3 l2 = [22,33,44] 4 li = [] 5 # 获取相同元素 6 for i in l1: 7 if i in l2: 8 li.append(i) 9 print(li) 10 # l1中有,l2没有 11 for i in l1: 12 if i not in l2: 13 li.append(i) 14 print(li) 15 # l2中有,l1没有 16 for i in l2: 17 if i not in l1: 18 li.append(i) 19 print(li) 20 # l1和l2都不同 21 for i in l1: 22 if i not in l2: 23 li.append(i) 24 for o in l2: 25 if o not in l1: 26 li.append(o) 27 print(li)
28 # 方法二: 29 l1 = [11,22,33] 30 l2 = [22,33,44] 31 # 获取相同元素,交集 32 li = list(set(l1).intersection(set(l2))) 33 print(li) 34 # l1中有,l2没有,差集 35 li = list(set(l1).difference(set(l2))) 36 print(li) 37 # l2中有,l1没有,差集 38 li = list(set(l2).difference(set(l1))) 39 print(li) 40 # l1和l2都不同,交叉补集 41 li = list(set(l1).symmetric_difference(set(l2))) 42 print(li)