文章目录
redis集群是什么
redis从3.0版本开始引入了redis-cluster(集群)。
从主从-哨兵-集群可以看到redis的不断完善;主从复制是最简单的节点同步方案无法主从自动故障转移。
哨兵可以同时管理多个主从同步方案同时也可以处理主从自动故障转移,通过配置多个哨兵节点可以解决单点网络故障问题。
但是单个节点的性能压力问题无法解决。集群解决了前面两个方案的所有问题。
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。
Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误.
Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令.
Redis 集群的优势:
自动分割数据到不同的节点上。
整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
几个小概念:


redis集群的特点
集群的节点内置了复制和高可用特性。
特点:
1、节点自动发现
2、slave->master 选举,集群容错
3、Hot resharding:在线分片
4、基于配置(nodes-port.conf)的集群管理
5、客户端与redis节点直连、不需要中间proxy层.
6、所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
Redis 集群的数据分片
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
节点 A 包含 0 到 5500号哈希槽.
节点 B 包含5501 到 11000 号哈希槽.
节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.

Redis 集群的主从复制模型
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了
不过当B和B1 都失败后,集群是不可用的.
Redis 一致性保证
Redis 并不能保证数据的强一致性. 这意味这在实际中集群在特定的条件下可能会丢失写操作.
第一个原因是因为集群是用了异步复制. 写操作过程:
客户端向主节点B写入一条命令.
主节点B向客户端回复命令状态.
主节点将写操作复制给他得从节点 B1, B2 和 B3.
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。 注意:Redis 集群可能会在将来提供同步写的方法。 Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点, 还有一个客户端 Z1 假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点 A 、C 、A1 、B1 和 C1 ,小部分的一方则包含节点 B 和客户端 Z1 .
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了.
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项。
几个常见的问题
“用了哈希槽的概念,而没有用一致性哈希算法,不都是哈希么?这样做的原因是为什么呢?”
Redis Cluster是自己做的crc16的简单hash算法,没有用一致性hash。
Redis的作者认为它的crc16(key) mod 16384的效果已经不错了,
虽然没有一致性hash灵活,但实现很简单,节点增删时处理起来也很方便。
“为了动态增删节点的时候,不至于丢失数据么?”
节点增删时不丢失数据和hash算法没什么关系,不丢失数据要求的是一份数据有多个副本。
“集群总共有2的14次方,16384个哈希槽,那么每一个哈希槽中存的key 和 value是什么?”
当你往Redis Cluster中加入一个Key时,会根据crc16(key) mod 16384计算这个key应该分布到哪个hash slot中,一个hash slot中会有很多key和value。
你可以理解成表的分区,使用单节点时的redis时只有一个表,所有的key都放在这个表里;
改用Redis Cluster以后会自动为你生成16384个分区表,你insert数据时会根据上面的简单算法来决定你的key应该存在哪个分区,每个分区里有很多key。
搭建并使用Redis集群
搭建集群的第一件事情我们需要一些运行在 集群模式的Redis实例. 这意味这集群并不是由一些普通的Redis实例组成的,集群模式需要通过配置启用,开启集群模式后的Redis实例便可以使用集群特有的命令和特性了.。
实验背景:
server1 172.25.2.10 关闭firewalld
在serevr1上设置6个redis实例,3个主,3个从。
创建实例
 1.停止原来的redis
1.停止原来的redis
 2.创建目录,准备配置文件
2.创建目录,准备配置文件
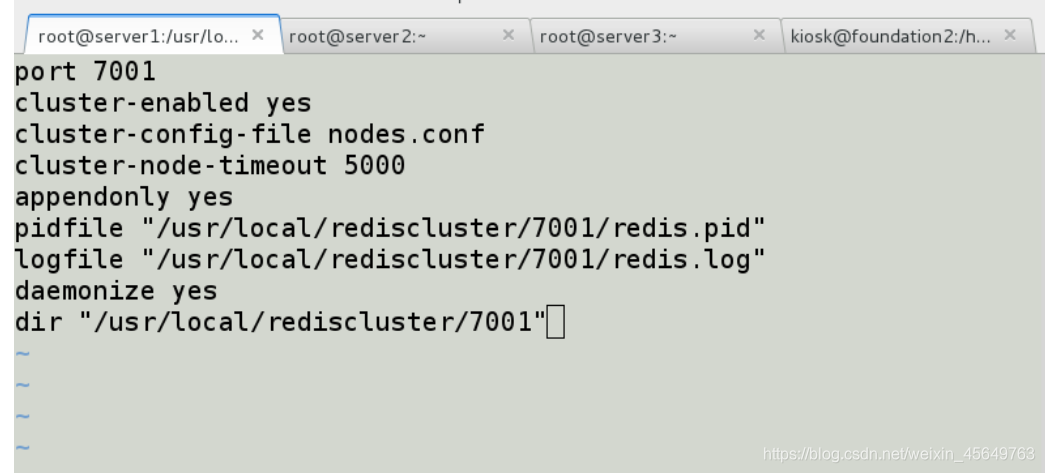
port 7001 //端口7001,7002,7003,7004,7005,7006
cluster-enabled yes //开实例的集群模式
cluster-config-file nodes.conf //集群的配置,配置文件首次启动自动生成 7001,7002,7003,7004,7005,7006
cluster-node-timeout 5000 //请求超时 默认15秒,可自行设置
appendonly yes //aof日志开启 有需要就开启,它会每次写操作都记录一条日志
daemonize yes //redis后台运行
后面指定了pid,log日志等
cluster-conf-file 选项则设定了保存节点配置文件的路径, 默认值为 nodes.conf.节点配置文件无须人为修改, 它由 Redis 集群在启动时创建, 并在有需要时自动进行更新。
要让集群正常运作至少需要三个主节点,不过在刚开始试用集群功能时, 强烈建议使用六个节点: 其中三个为主节点, 而其余三个则是各个主节点的从节点。
首先, 让我们进入一个新目录, 并创建六个以端口号为名字的子目录, 稍后我们在将每个目录中运行一个 Redis 实例: 命令如下:
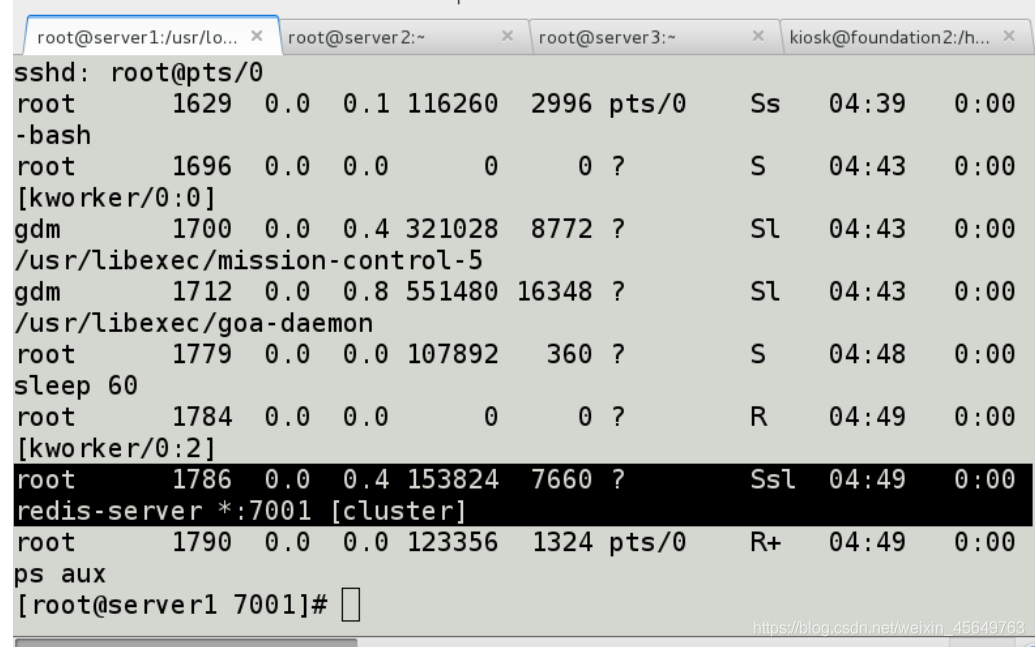
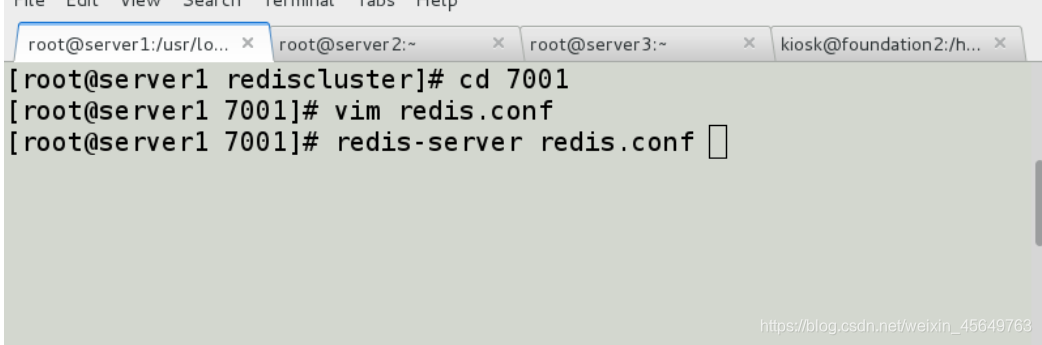 开启实例1,ps -aux
开启实例1,ps -aux
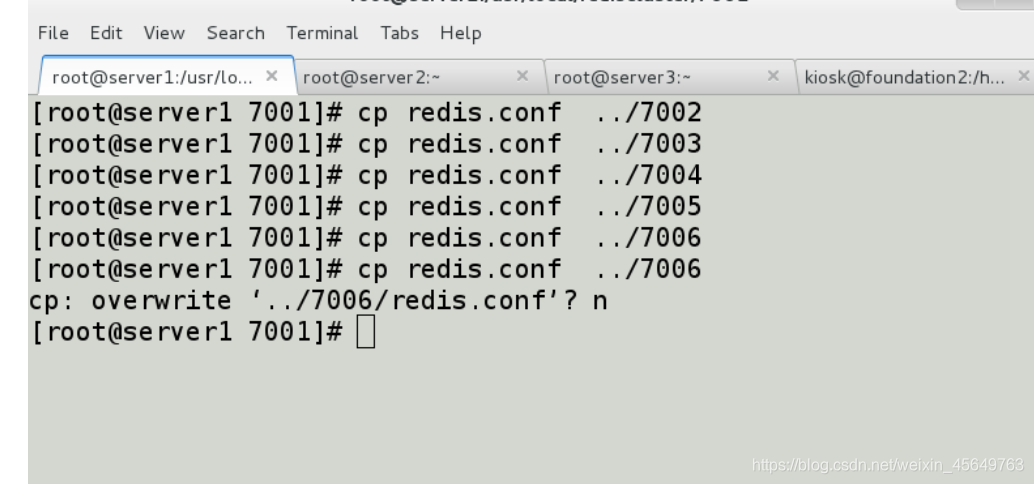
在文件夹 70001至 7006 中, 各创建一个 redis.conf 文件, 文件的内容可以使用上面的示例配置文件, 但记得将配置中的端口号从 7000 改为与文件夹名字相同的号码.
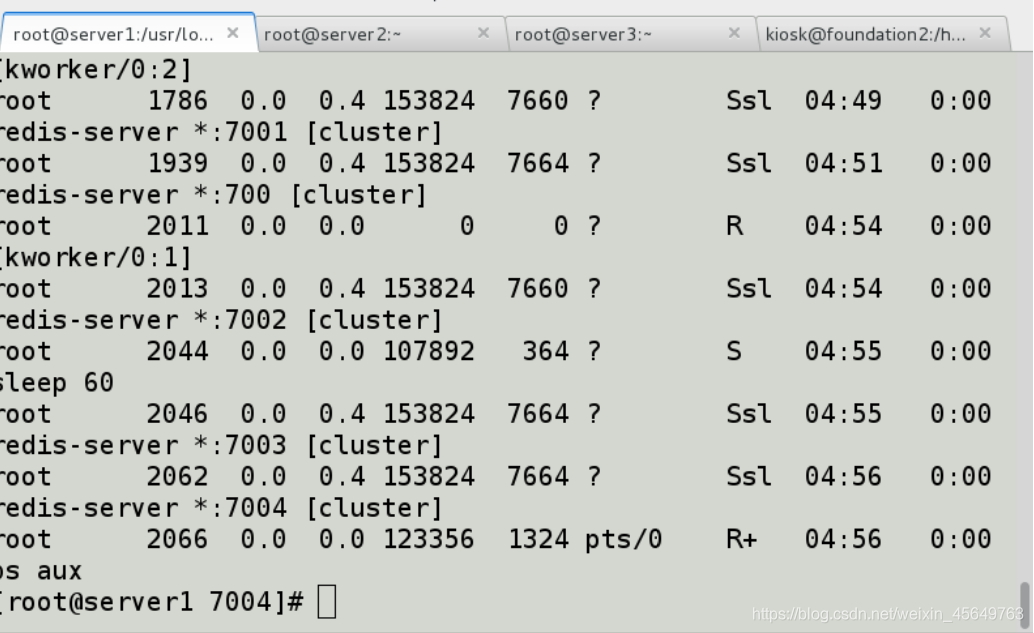
 配置完文件后,开启每个redis,直到看到每个端口都打开。
配置完文件后,开启每个redis,直到看到每个端口都打开。
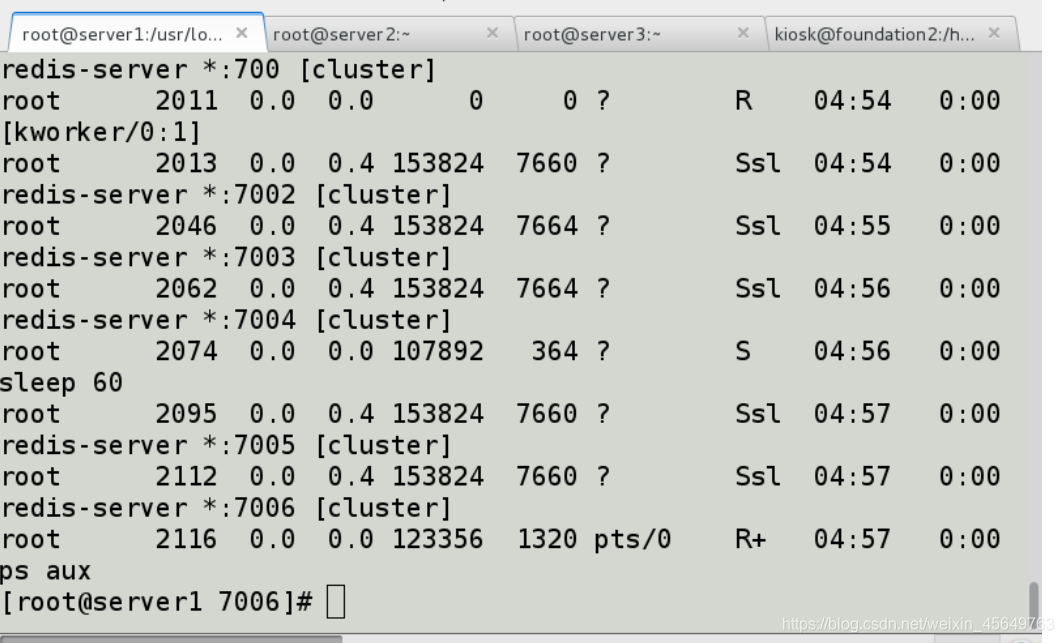
搭建集群
现在我们已经有了六个正在运行中的 Redis 实例, 接下来我们需要使用这些实例来创建集群, 并为每个节点编写配置文件。
通过使用 Redis 集群命令行工具 redis-trib , 编写节点配置文件的工作可以非常容易地完成
redis-trib 位于 Redis 源码的 src 文件夹中, 它是一个 Ruby 程序, 这个程序通过向实例发送特殊命令来完成创建新集群, 检查集群, 或者对集群进行重新分片(reshared)等工作。

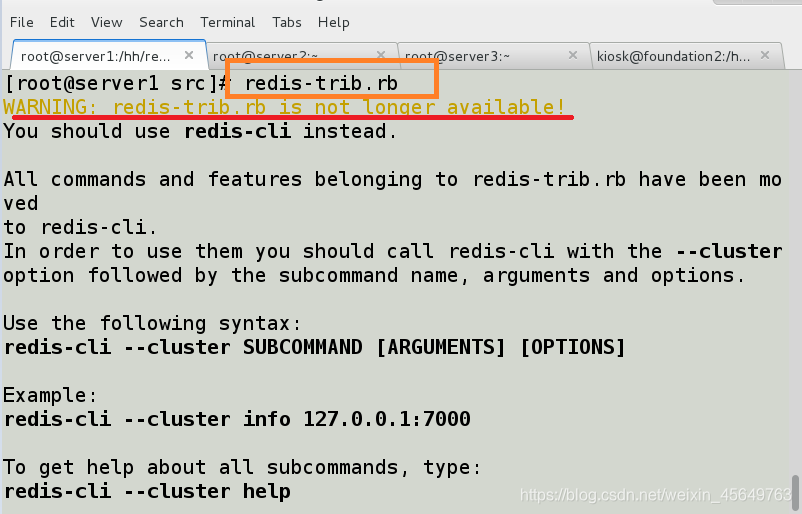
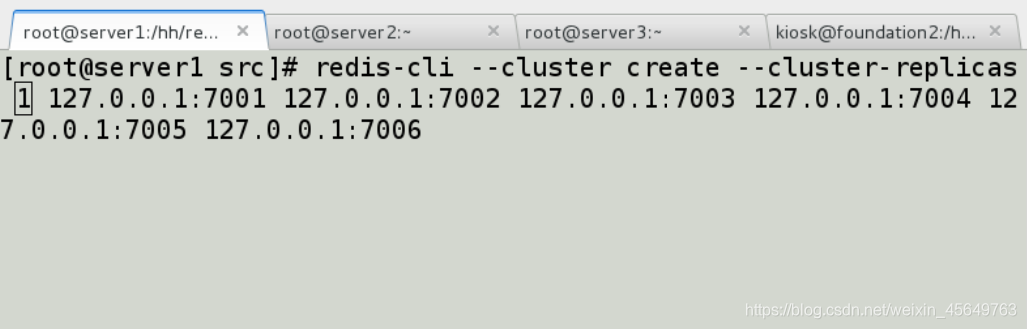 这个命令在这里用于创建一个新的集群, 选项–replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
这个命令在这里用于创建一个新的集群, 选项–replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
之后跟着的其他参数则是这个集群实例的地址列表,3个master3个slave redis-trib 会打印出一份预想中的配置给你看, 如果你觉得没问题的话, 就可以输入 yes , redis-trib 就会将这份配置应用到集群当中,让各个节点开始互相通讯,最后可以得到如下信息:
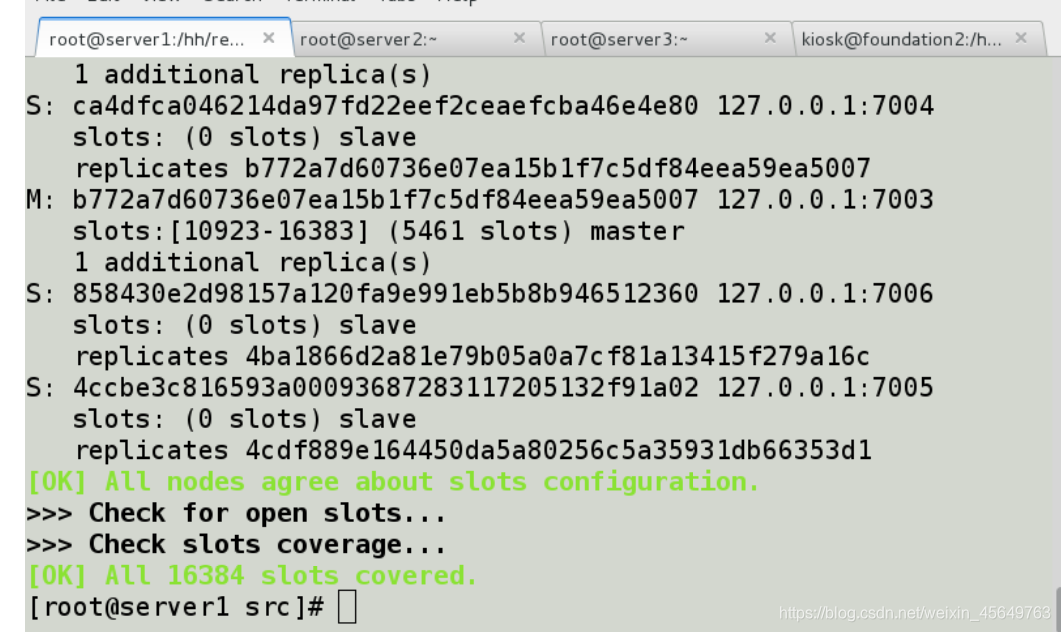 这表示集群中的 16384 个槽都有至少一个主节点在处理, 集群运作正常。
这表示集群中的 16384 个槽都有至少一个主节点在处理, 集群运作正常。
可以看到集群已经创建好

测试集群
测试 Redis 集群比较简单的办法就是使用 redis-rb-cluster 或者 redis-cli , 接下来我们将使用 redis-cli 为例来进行演示。
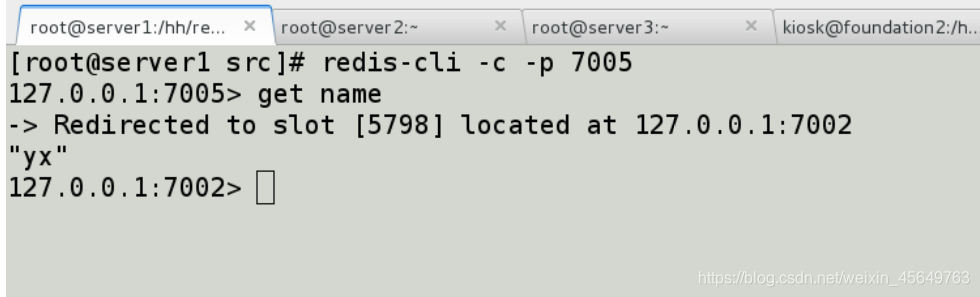
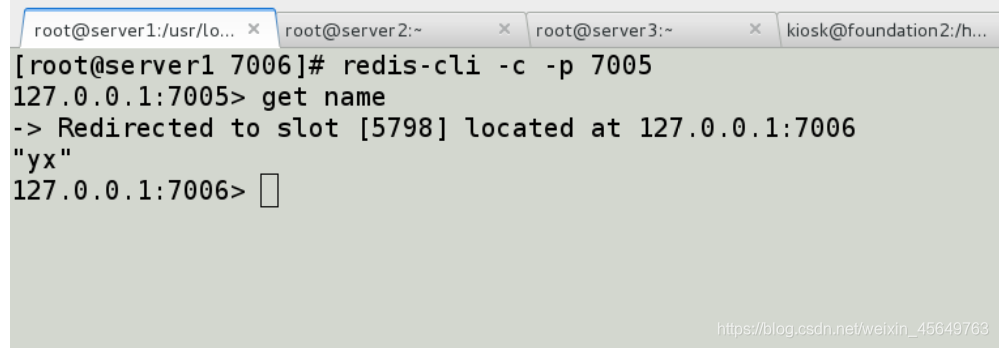
可以看到,经过算法运算,我们存的name 保存在了7002的槽里。
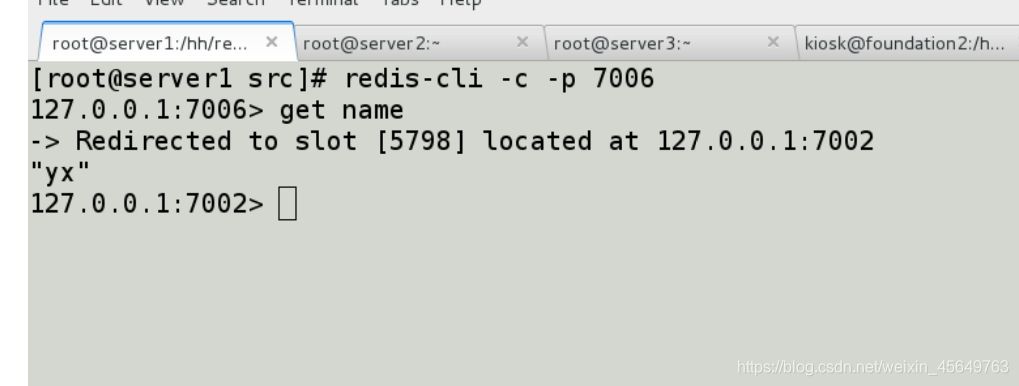
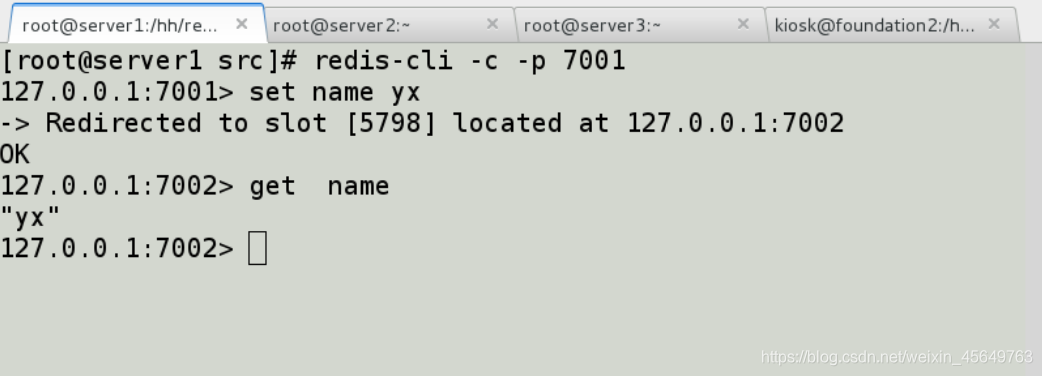 去7005找数据,它自动帮你从7002中拿数据
去7005找数据,它自动帮你从7002中拿数据
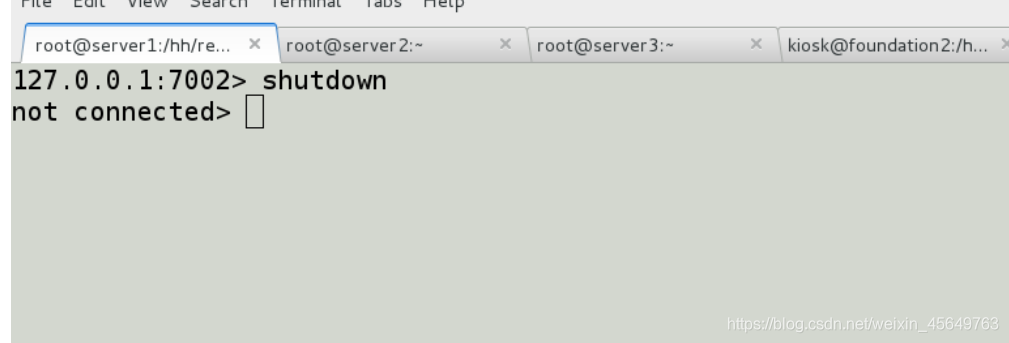
 当把7002关闭时
当把7002关闭时
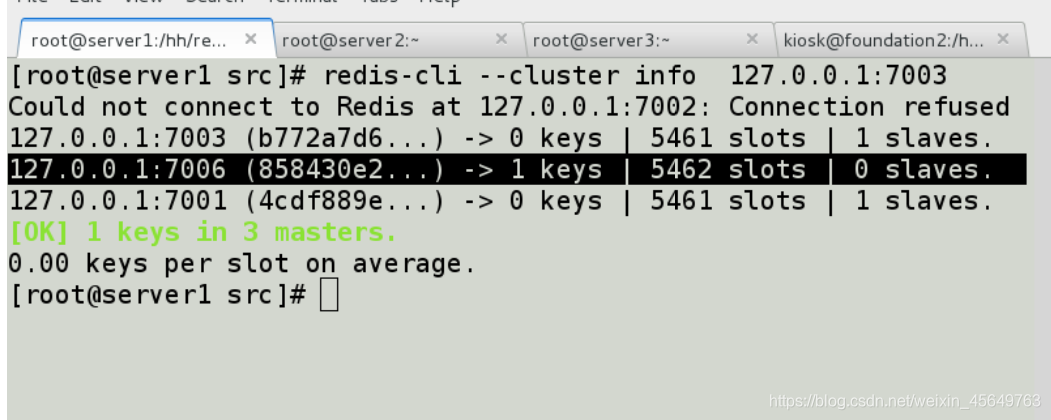
 我们看到7006自动成为主库,它没有从库。
我们看到7006自动成为主库,它没有从库。
 数据存储在7006中
数据存储在7006中
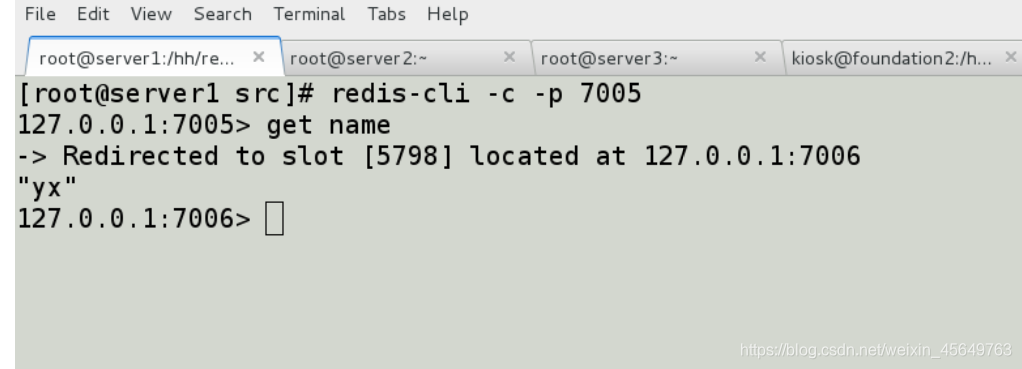 将7006也关闭,它原来是7002的从库,现在是一个主库
将7006也关闭,它原来是7002的从库,现在是一个主库
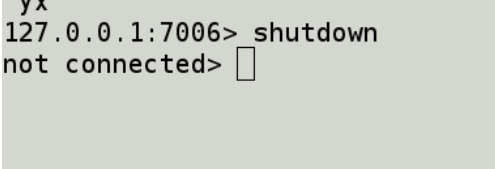 只剩下2个主库
只剩下2个主库
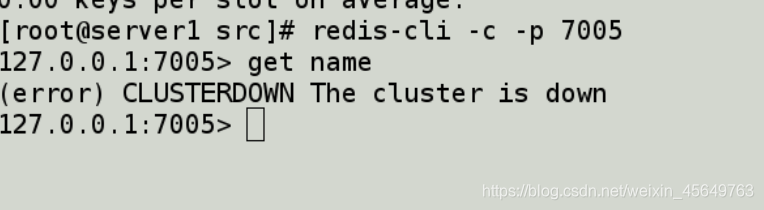
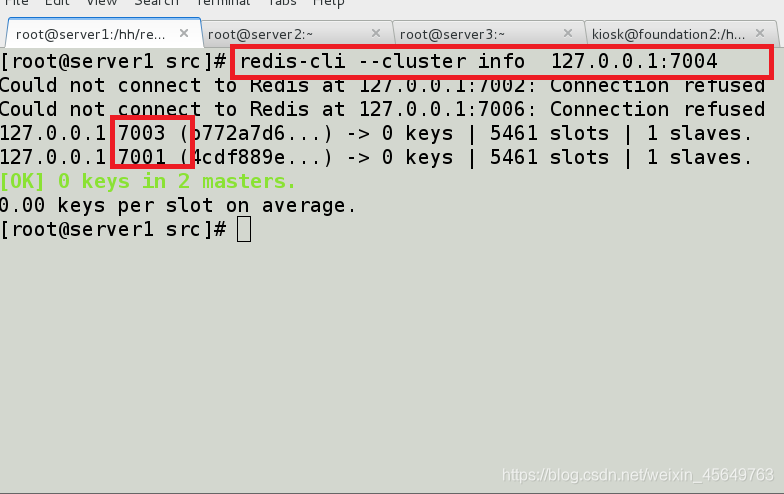 再也拿不到数据了,因为刚才创建的name,存在7002和7006上,现在两个都downl.找不到了.
再也拿不到数据了,因为刚才创建的name,存在7002和7006上,现在两个都downl.找不到了.
 如何进行数据的恢复,恢复7001和7002
如何进行数据的恢复,恢复7001和7002
 appendonly.aof可以帮助我们恢复节点
appendonly.aof可以帮助我们恢复节点
它以日志的形式来记录每个写操作,将redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
Aof保存的是appendonly.aof文件,具体涉及到前几篇文章中,数据持久化的方式
 同样恢复7006
同样恢复7006
 再次查看集群,发现恢复6台
再次查看集群,发现恢复6台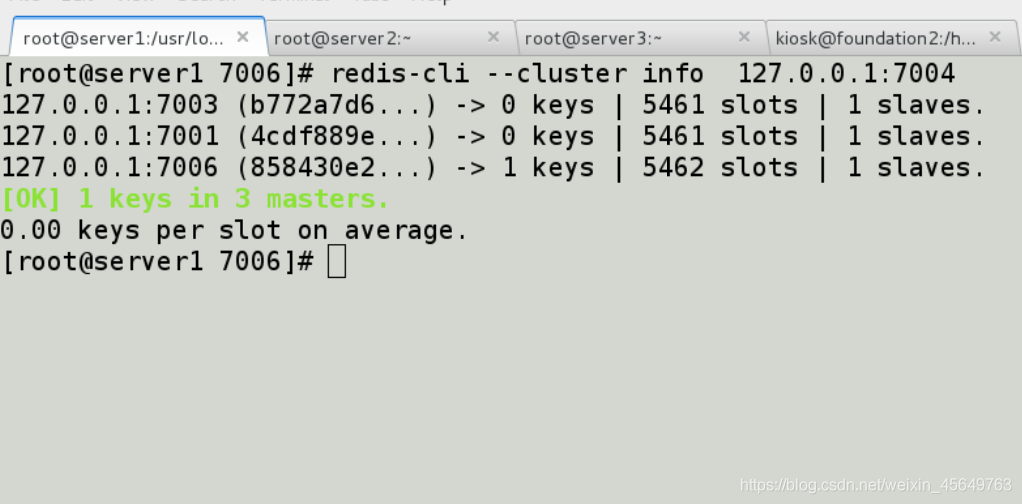 原来的数据,在7006上也能找到-
原来的数据,在7006上也能找到-
 注意:
注意:
当集群当中的一半以上的master都down掉以后,集群也会down掉了
给集群增加新的节点
添加新的节点的基本过程就是添加一个空的节点然后移动一些数据给它,有两种情况,添加一个主节点和添加一个从节点(添加从节点时需要将这个新的节点设置为集群中某个节点的复制)
两种情况第一步都是要添加 一个空的节点.
启动新的7006节点,使用的配置文件和以前的一样,只要把端口号改一下即可,过程如下:
先从添加主节点开始介绍。
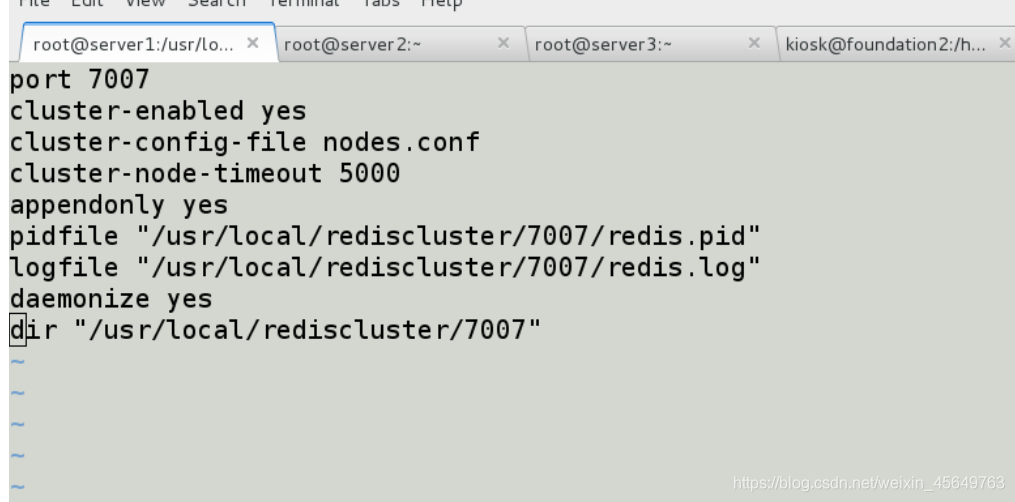

 (开启7007和7008端口)
(开启7007和7008端口)
将7007添加到集群中

 将7008添加到集群,并让它成为7007的从库
将7008添加到集群,并让它成为7007的从库
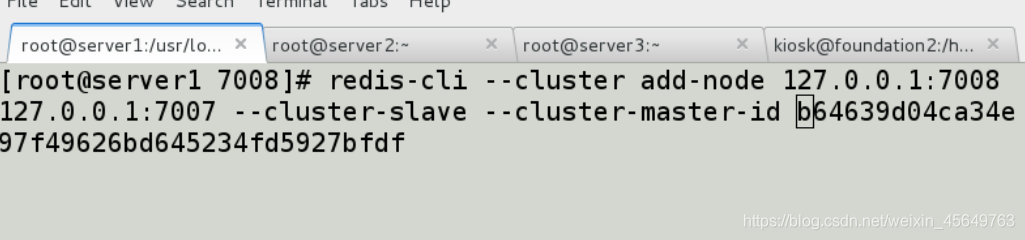 后面的id 是之前的命令查出的id
后面的id 是之前的命令查出的id
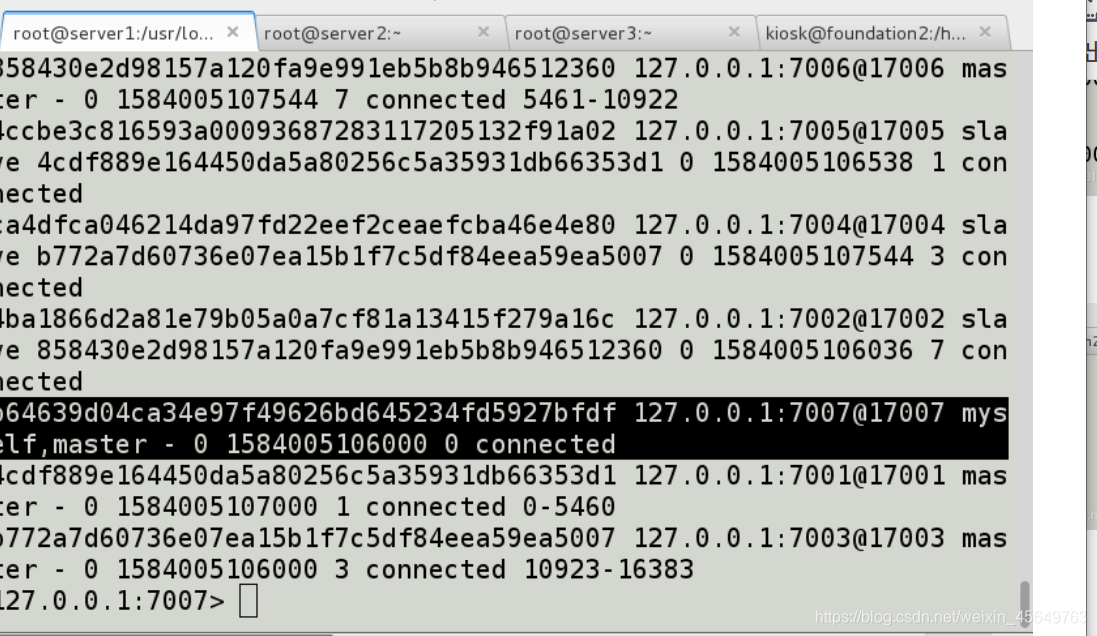
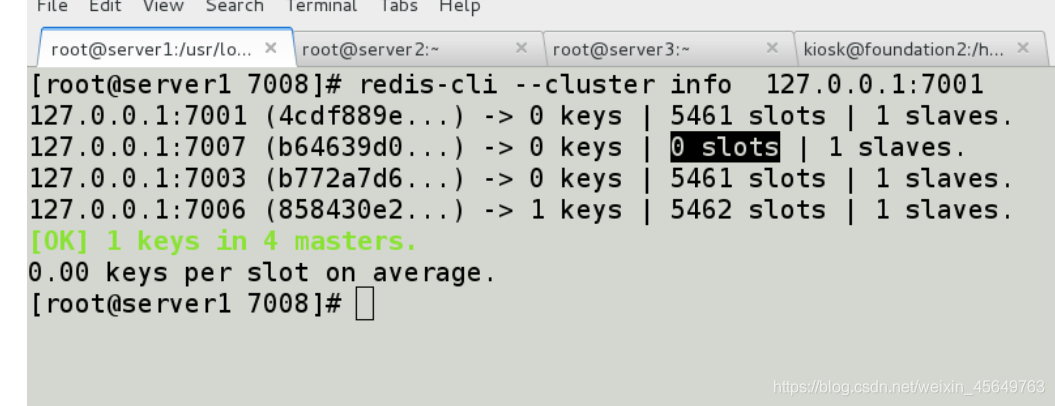
 我们发现,虽然配置好了,但是7007并没有分配到槽
我们发现,虽然配置好了,但是7007并没有分配到槽
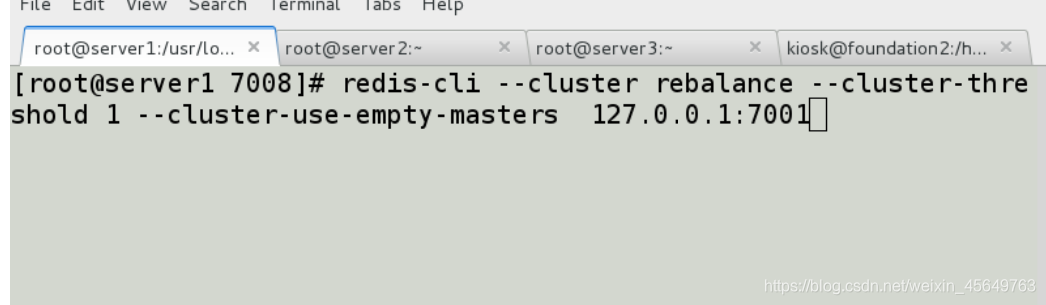
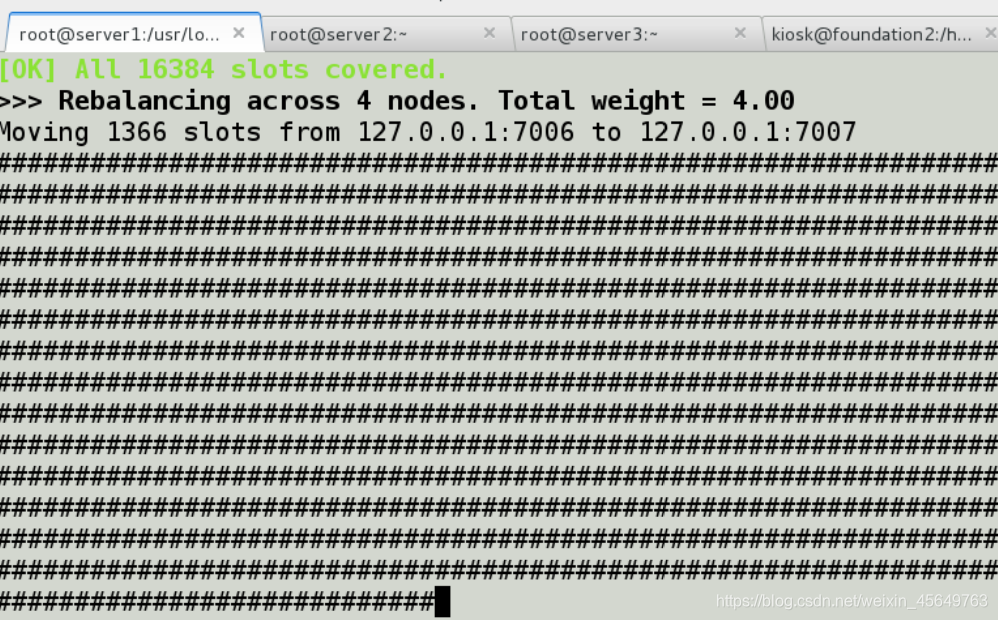 发现哈希槽被均分
发现哈希槽被均分
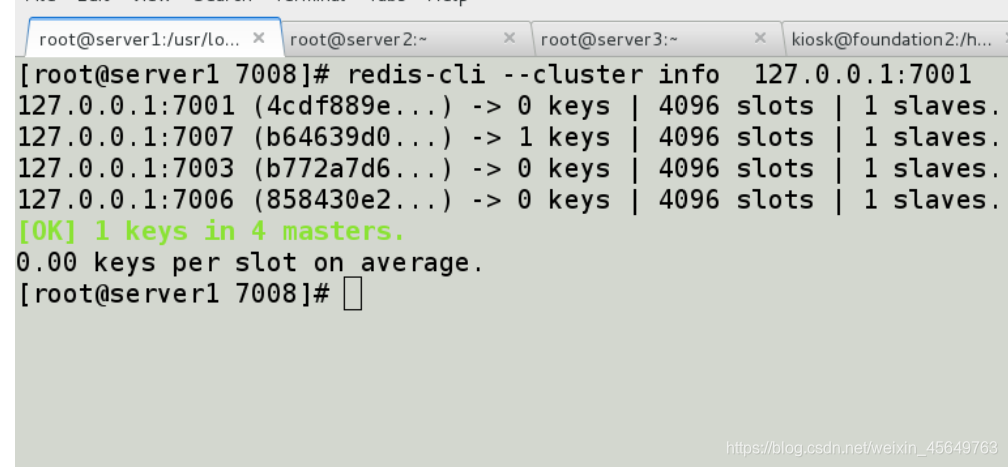 发现新节点上的数据
发现新节点上的数据
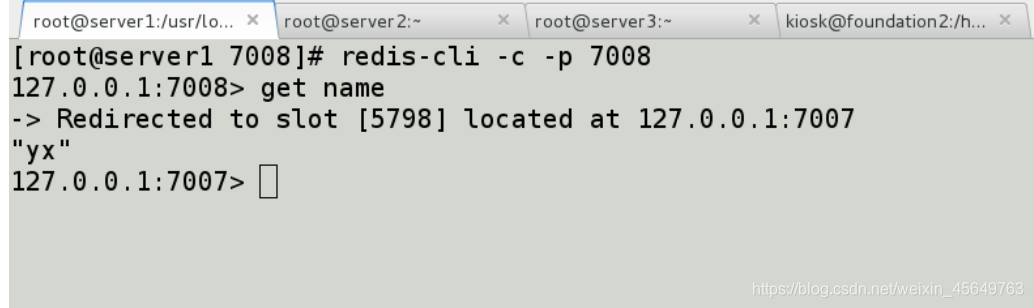
节点的移除
只要使用 del-node 命令即可:
./redis-trib del-node 127.0.0.1:7000 `<node-id>`
第一个参数是任意一个节点的地址,第二个节点是你想要移除的节点地址。
使用同样的方法移除主节点,不过在移除主节点前,需要确保这个主节点是空的. 如果不是空的,需要将这个节点的数据重新分片到其他主节点上.
替代移除主节点的方法是手动执行故障恢复,被移除的主节点会作为一个从节点存在,不过这种情况下不会减少集群节点的数量,也需要重新分片数据
从节点的迁移
在Redis集群中会存在改变一个从节点的主节点的情况,需要执行如下命令 :
CLUSTER REPLICATE <master-node-id>
在特定的场景下,不需要系统管理员的协助下,自动将一个从节点从当前的主节点切换到另一个主节 的自动重新配置的过程叫做复制迁移(从节点迁移),从节点的迁移能够提高整个Redis集群的可用性.
