1.监督学习:监督学习分为两大类回归问题和分类问题。由已有的数据训练模型函数,把新的输入数据带入模型函数,预测数据输出。函数的输出若为一个连续的值,则为回归问题;若是预测一个分类标签,则为分类问题。例:糖尿病
无监督学习:聚类算法。根据特征把未知类别进行分类。例:新闻事件分类,细分市场。
2.代价函数:又叫损失函数。任何能够衡量模型预测出来的值h(θ)与真实值y之间的差异的函数都可以叫做代价函数,用于找到最优解的目的函数。
对于回归问题,我们需要求出代价函数来求解最优解,常用的是平方误差代价函数。
例如:对于下面的假设函数
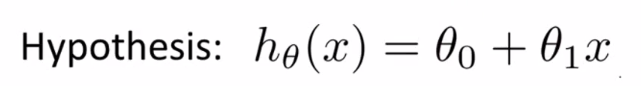
里面有θ0和θ1两个参数,参数的变化将会导致假设函数的变化。
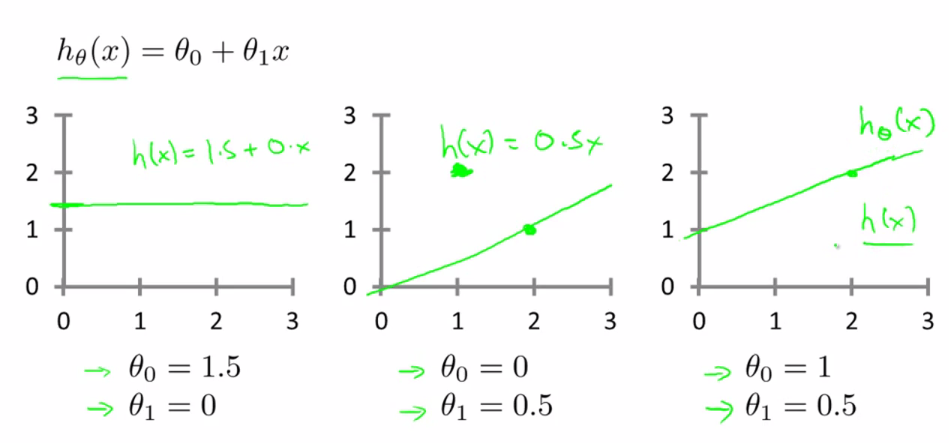
我们想要解决回归问题,就需要将这些点拟合成一条直线,找出最优θ0和θ1。
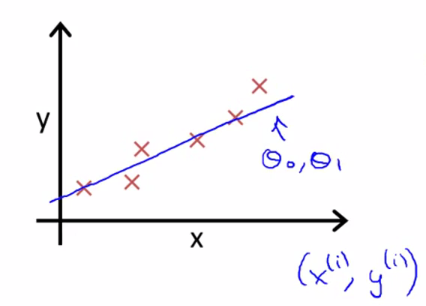
如何找到最优解,这就需要需要使用代价函数来求解。以平方误差代价函数为例。
假设函数为:
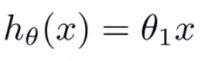
平方误差代价函数的主要思想是将实际数据给出的值与我们拟合出的线的对应值做差,这样就能求出我们拟合出的直线与实际的差距了。
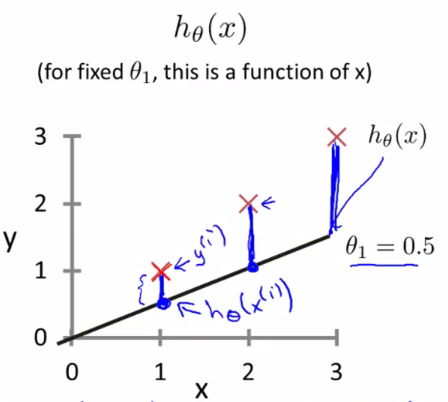
代价函数:
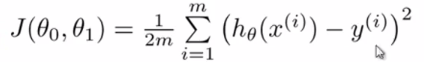
最优解即为代价函数的最小值,根据以上公式多次计算得代价函数图像
可以看到该代价函数的确有最小值,这里为横坐标为1得时候。
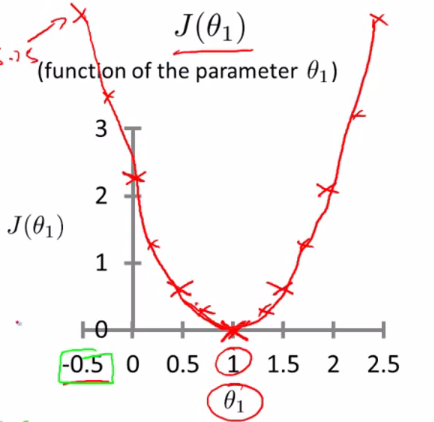
如何为两个参数时,为三维图像:
对于回归问题,我们可以归结为得到代价函数得最小值。
3.梯度下降:用来求函数最小值得算法,我们将使用梯度下降算法代价函数得最小值。
比如我们在一座大山上得某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置得时候,求解
当前位置得一度,沿着梯度得负方向,也就是当前最陡峭得位置向下走一步,然后继续求解当前位置梯度向这一步所在位置沿着
最陡峭最易下山的位置走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到
山脚,而是到了某一个局部的山峰低处。
从上面得解释看,梯度下降不一定能够找到全局最优解,有可能是一个局部最优解。如何损失函数是凸函数,梯度下降得到的解一定是全局最优解。

举例说明梯度减小的过程:对于我们的函数J(θ)求偏导J.

在变化的时候,我们就朝着下降最多的方向进行变化就可以达到一个最小点

迭代示意图:

4.特征缩放:用来标准化数据特征的范围。
作用:特征缩放是针对多特征情况的,当有多个特征向量的时候,如果其中一个变化范围比较大,该特征向量的参数可能会变化范围很大,从而主导整个梯度下降的过程,使得整个收敛轨迹变得复杂,让收敛的时间更长。如下图所示:
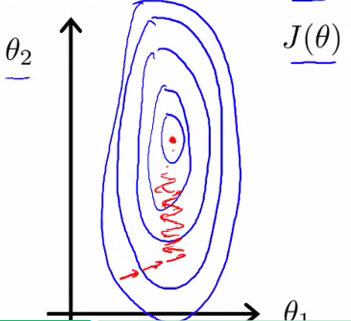
因此,我们可以将所有特征向量的变化范围维持在一个标准化范围之中,就能减小该特征向量的影响程度,加快梯度收敛速度。
5.学习率:学习率决定者目标函数能否收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使得目标函数在合适的时间内收敛到局部最小值。
学习率的作用:它决定了我们能沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。当学习率设置的过小时,收敛过程将变得十分缓慢。而当学习率设置的过大时,梯度可能会在最小值附近来回震荡,甚至可能无法收敛。
学习率的设置:
6.分类与回归的区别:
定量输出称为回归,或者说是连续变量预测;
定性输出称为分类,或者说是离散变量预测。
分类常用算法:随机森林、k—最近邻算法。
回归常用算法:线性回归、逻辑回归(二分类)、多项式回归、逐步回归、岭回归。
