文章目录
一、HBase介绍
HBase是一个开源的非关系型数据库,是根据谷歌的论文Big Table设计开发的。HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。HBase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表。
1、HBase出现的原因?
• hadoop虽然已经有了HDFS和mapreduce,但是只能很好的解决大规模数据的离线批量处理问题。无法满足大规模数据实时处理应用的需求。
• 并且HDFS面向批量访问模式,不是随机访问模式
• 传统的关系型数据库无法应对结构化和半结构的数据以及数据规模剧增的情况
2、HBase和传统的关系型数据库的区别
| 方面 | 传统的关系型数据库 | Hbase |
|---|---|---|
| 数据类型 | 有丰富的数据类型和存储方式,数据类型固定 | 数据类型不固定,把数据存储为未经解释的字符串 |
| 数据操作 | 有复杂的多表连接关系 | 只有简单的插入、查询、删除、清空等,不存在复杂的表与表之间的关系 |
| 存储模式 | 基于行 | 基于列,每个列族由几个文件保存,不同列族的文件是分离的 |
| 数据索引 | 针对不同列构建复杂的多个索引 | 只有一个索引,行键 |
| 数据维护 | 更新操作会用最新的值去替换原来的值,被覆盖后就不存在 | HBase更新操作时,不会删除数据旧的版本,旧的新的都会存在 |
| 可伸缩性 | 关系型数据库很难实现横向扩展,纵向扩展的空间也有限 | HBase是分布式数据库实现了灵活的水平扩展,可以随意的增加or减少硬件数量实现性能的伸缩 |
3、HBase数据类型
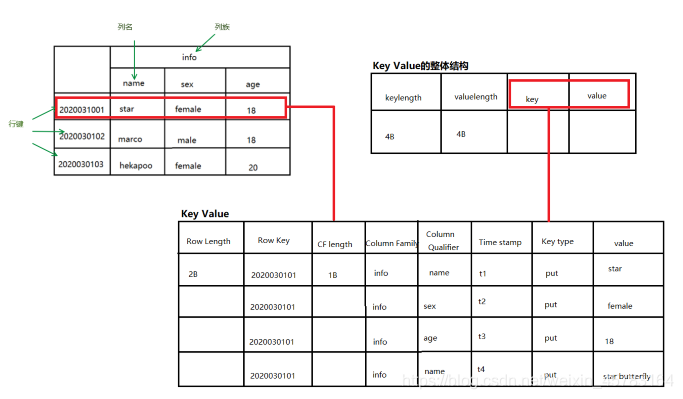
对上图的解释
- 表:HBase采用表来组织数据,表由行和列组成,列划分为若干列族。
- 行:每个HBase表都由若干行组成,每个行由行键(row key)来标识。
- 列族:一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元。
- 列名:列族里的数据通过限定符(或列)来定位。
- 单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[](第一个表的一个格子就是单元格)
对key value的解释
- Row Length:存储rowkey的长度,占2B (Bytes.SIZEOF_INT);
- Row:存储Rowkey实际内容,其大小为Row Length ;
- Column Family Length:存储列簇Column Family的长度,占1B (Bytes.SIZEOF_BYTE);
- Column Family:存储Column Family实际内容,大小为Column Family Length;
- Column Qualifier:存储Column Qualifier对应的数据。
- Time Stamp:存储时间戳Time Stamp,占8B (Bytes.SIZEOF_LONG);
- Key Type:存储Key类型Key Type,占1B ( Bytes.SIZEOF_BYTE),Type分为Put、Delete、DeleteColumn、DeleteFamilyVersion、DeleteFamily、Maximum、Minimum等类型,标记这个KeyValue的类型;--------->由于Key中其它的字段占用大小已经知道,并且知道整个Key的大小,因此没有存储Column Qualifier的大小。
4、HBase的架构
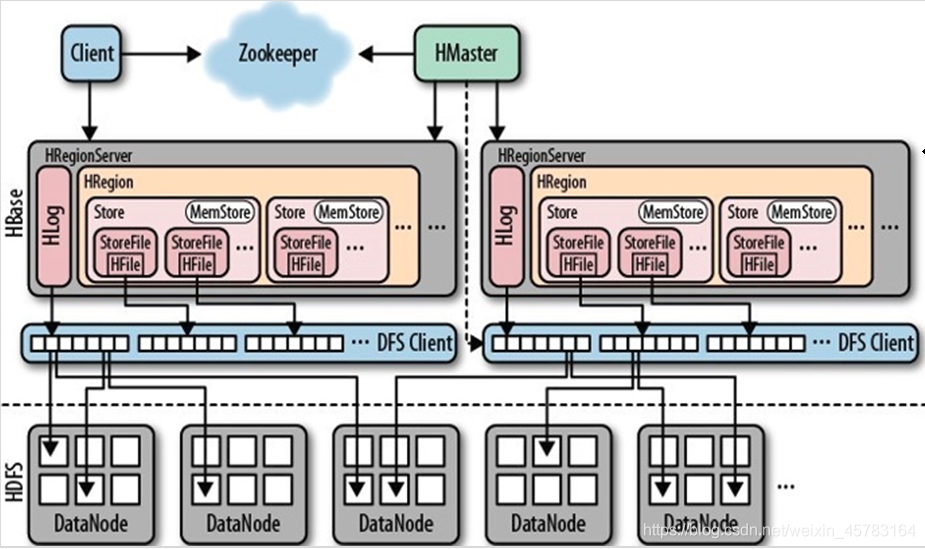
- Zookeeper:作为分布式的协调。RegionServer也会把自己的信息写到ZooKeeper中,主用Master据此感知各个RegionServer的健康状态。
- Client使用HBase的RPC机制与Master、RegionServer进行通信。Client与Master进行管理类通信,与RegionServer进行数据操作类通信。
- HDFS:是Hbase运行的底层文件系统,HBase的数据全部存储在HDFS中
- RegionServer:理解为数据节点,存储数据的。
- Hmaster:分为主用master和备用master
- 主用Master:负责HBase中RegionServer的管理,包括表的增删改查;RegionServer的负载均衡,Region分布调整;Region分裂以及分裂后的Region分配;RegionServer失效后的Region迁移等。
- 备用Master:当主用Master故障时,备用Master将取代主用Master对外提供服务。故障恢复后,原主用Master降为备用。
- MemStore:当RegionServer中的MemStore大小达到配置的容量上限时,RegionServer会将MemStore中的数据“flush”到HDFS中。
- StoreFile:随着数据的插入,一个Store会产生多个StoreFile,当StoreFile的个数达到配置的最大值时,RegionServer会将多个StoreFile合并为一个大的StoreFile。
- Hfile:HFile定义了StoreFile在文件系统中的存储格式,它是当前HBase系统中StoreFile的具体实现。
- Hlog:HLog日志保证了当RegionServer故障的情况下用户写入的数据不丢失,RegionServer的多个Region共享一个相同的Hlog。
5、HBase读写流程
HBase读流程
- HRegionServer 保存着 meta 表以及表数据,要访问表数据,首先 Client 先去访问
zookeeper,从 zookeeper 里面获取 meta 表所在的位置信息,即找到这个 meta 表在哪个
HRegionServer 上保存着。 - 接着 Client 通过刚才获取到的 HRegionServer 的 IP 来访问 Meta 表所在的HRegionServer,从而读取到 Meta,进而获取到 Meta 表中存放的元数据。
- Client 通过元数据中存储的信息,访问对应的 HRegionServer,然后扫描所在
HRegionServer 的 Memstore 和 Storefile 来查询数据。 - 最后 HRegionServer 把查询到的数据响应给 Client。
HBase写流程
- Client 也是先访问 zookeeper,找到 Meta 表,并获取 Meta 表信息。
- 确定当前将要写入的数据所对应的 RegionServer 服务器和 Region。
- Client 向该 RegionServer 服务器发起写入数据请求,然后 RegionServer 收到请求并响应。
- Client 先把数据写入到 HLog,以防止数据丢失。
- 然后将数据写入到 Memstore。
- 如果 Hlog 和 Memstore 均写入成功,则这条数据写入成功。在此过程中,如果 Memstore达到阈值,
会把 Memstore 中的数据 flush 到 StoreFile 中。 - 当 Storefile 越来越多,会触发 Compact 合并操作,把过多的 Storefile 合并成一个大的Storefile。
当 Storefile 越来越大,Region 也会越来越大,达到阈值后,会触发 Split 操作,将 Region 一分为二。
二、Hbase部署
环境前提
zookeeper正常部署
hadoop正常部署
1、解压HBase
解压HBase到/export/service
2、修改配置文件
vim hbase-env.sh


vim hbase-site.xml
这个是Hbase的主配置文件,你可以指定hbase和ZooKeeper数据写入的目录,当然也可以指定hbase的根目录在哪个位置

<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns1/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/data/zk/</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01,node02,node03</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
</configuration>
vim regionservers
3、启动节点
1、启动zk集群 ./zkServer.sh start
2、启动hdfs集群: start-dfs.sh
3、启动hbase,在主节点上运行(node01):start-hbase.sh

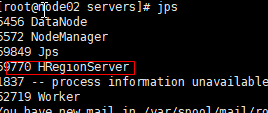
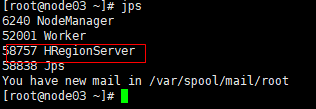
4、页面访问hbase管理页面:
node01:16010
5、进入shell命令行 :hbase shell
三、HBase简单使用
- 查看帮助命令
hbase(main):001:0> help
- 查看当前数据库有哪些表
hbase(main):002:0> list
- 表的创建
hbase(main):003:0> create 'student','info'
- 插入数据到表
put 'student','1001','info:name','mike'
put 'student','1001','info:age','22'
put 'student','1002','info:name','marco'
put 'student','1001','info:sex','female'
- 扫描查看数据
hbase(main) > scan 'student' //扫描全表
hbase(main) > scan 'student',{STARTROW => '1001', STOPROW => '1001'} //扫描指定范围
- 查看表结构:
hbase(main):008:0> describe 'student'
- 删除数据:
hbase(main) > delete 'student','1002','info:sex'
- 查看指定行或者指定行:指定列
hbase(main) > get 'student','1001'
hbase(main) > get 'student','1001','info:name'
- 更新字段
put 'student','1001','info:name','star'
- 清空表数据
truncate ‘student’
- 删除表
drop ‘student’

