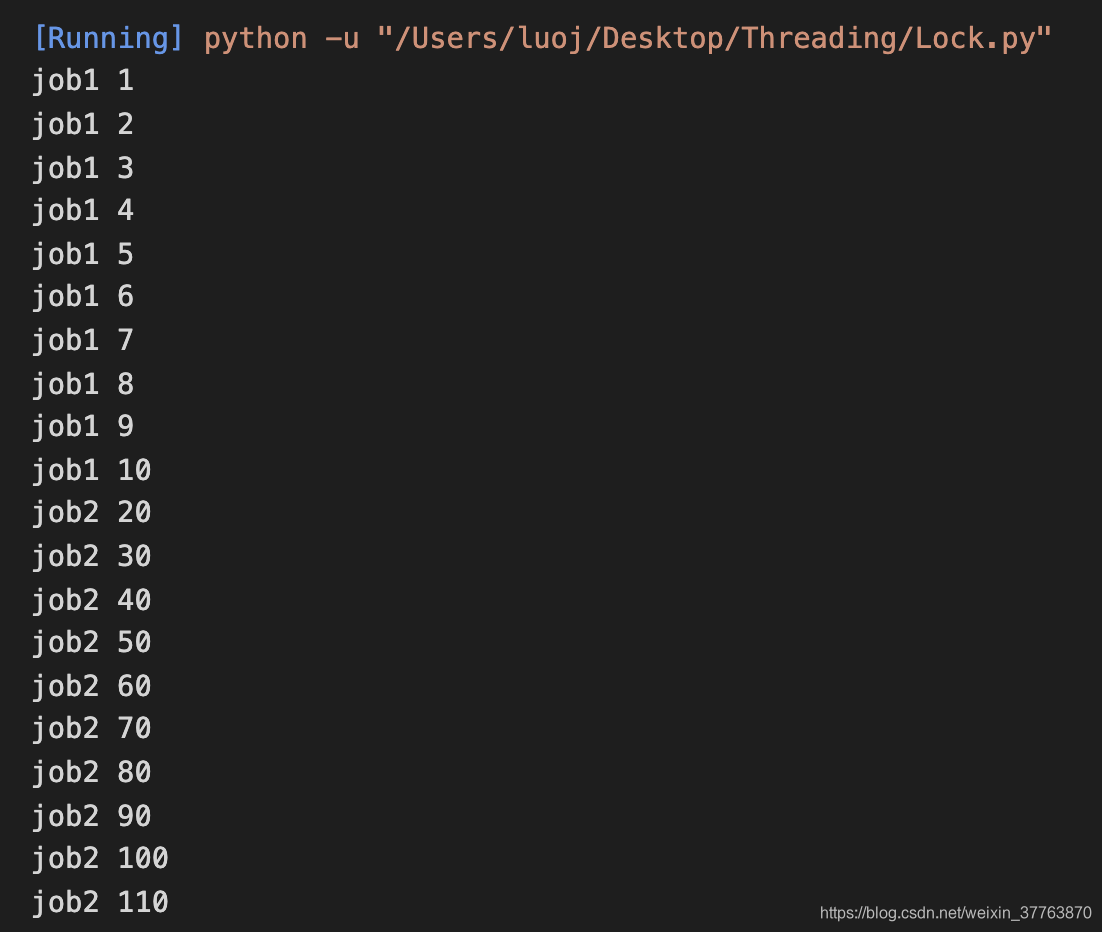
1.不使用 Lock 的情况
函数一:全局变量A的值每次加1,循环10次,并打印
def job1():
global A
for i in range(10):
A+=1
print('job1',A)
函数二:全局变量A的值每次加10,循环10次,并打印
def job2():
global A
for i in range(10):
A+=10
print('job2',A)
主函数:定义两个线程,分别执行函数一和函数二
if __name__== '__main__':
A=0
t1=threading.Thread(target=job1)
t2=threading.Thread(target=job2)
t1.start()
t2.start()
t1.join()
t2.join()
完整代码:
import threading
def job1():
global A
for i in range(10):
A+=1
print('job1',A)
def job2():
global A
for i in range(10):
A+=10
print('job2',A)
if __name__== '__main__':
lock=threading.Lock()
A=0
t1=threading.Thread(target=job1)
t2=threading.Thread(target=job2)
t1.start()
t2.start()
t1.join()
t2.join()
可以看出,打印的结果非常混乱
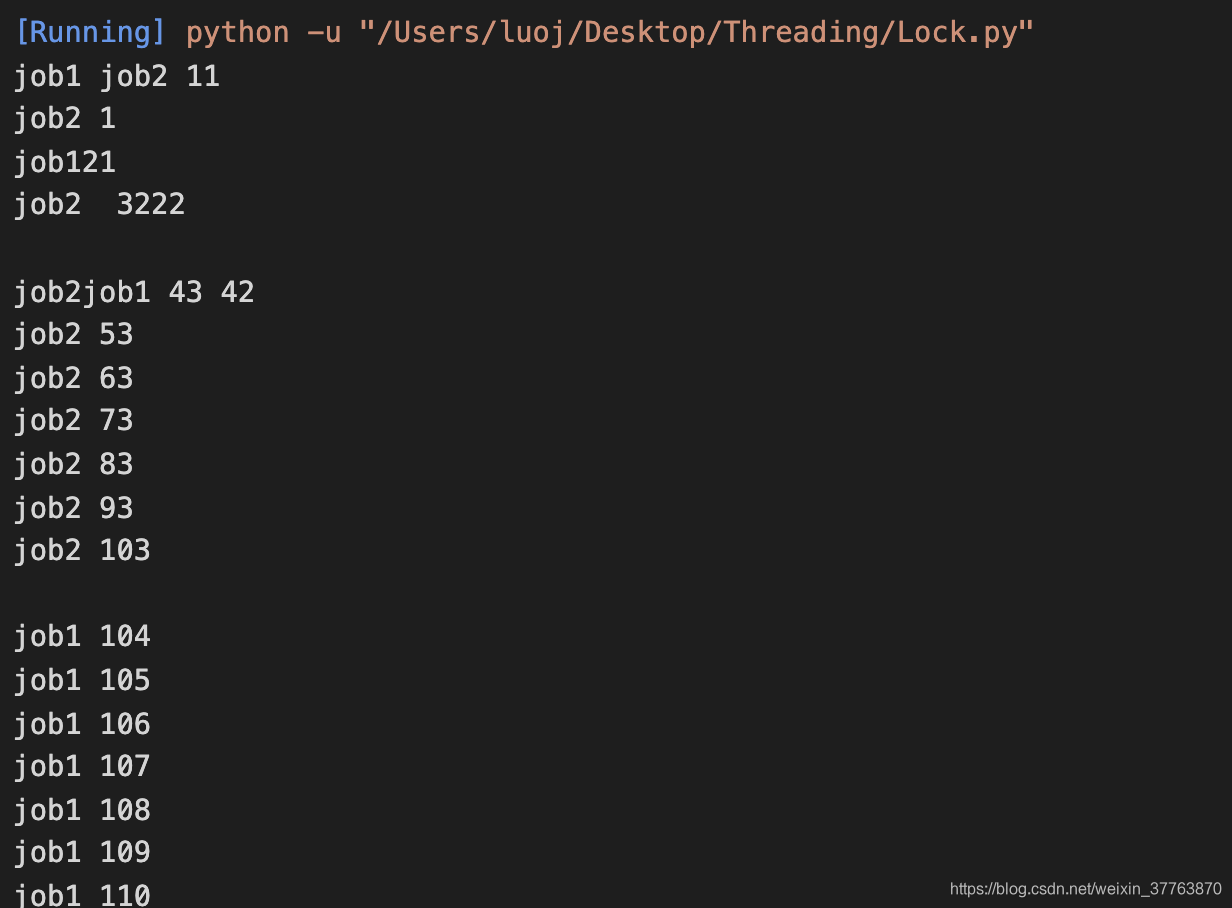
2.使用 Lock 的情况
lock在不同线程使用同一共享内存时,能够确保线程之间互不影响,使用lock的方法是, 在每个线程执行运算修改共享内存之前,执行lock.acquire()将共享内存上锁, 确保当前线程执行时,内存不会被其他线程访问,执行运算完毕后,使用lock.release()将锁打开, 保证其他的线程可以使用该共享内存。
函数一和函数二加锁
def job1():
global A,lock
lock.acquire()
for i in range(10):
A+=1
print('job1',A)
lock.release()
def job2():
global A,lock
lock.acquire()
for i in range(10):
A+=10
print('job2',A)
lock.release()
主函数中定义一个Lock
if __name__== '__main__':
lock=threading.Lock()
A=0
t1=threading.Thread(target=job1)
t2=threading.Thread(target=job2)
t1.start()
t2.start()
t1.join()
t2.join()
完整的代码
import threading
def job1():
global A,lock
lock.acquire()
for i in range(10):
A+=1
print('job1',A)
lock.release()
def job2():
global A,lock
lock.acquire()
for i in range(10):
A+=10
print('job2',A)
lock.release()
if __name__== '__main__':
lock=threading.Lock()
A=0
t1=threading.Thread(target=job1)
t2=threading.Thread(target=job2)
t1.start()
t2.start()
t1.join()
t2.join()