深度神经网络可视化技术
深度学习模型表述的难点与意义
深度神经网络(Deep Neural Network,DNN)作为当前人工智能应用的首选模型,在图像识别,语音识别,自然语言处理,计算生物,金融大数据等领域成效显著。但深度神经网络又被称为“黑盒”模型,多层隐藏结构,数据 / 特征矢量化,海量决策关键元等因素让模型使用者犯难:模型决策的依据是什么?应该相信模型么?特别是对于金融,医药,生物等关键型任务,深度学习模型的 弱解释性 成为人工智能项目落地的最大障碍。
云脑科技自主研发的 Deepro 深度学习平台利用可视化技术,集成了最前沿的各类深度神经网络可视化组件,分析与显化内部隐藏结构与模型输出的关系,解决“黑盒”难题。
深度神经网络的可视化
作为理解人工智能系统的主要技术,模型可视化是一个由来已久而且宽泛的话题。模型可视化与数据可视化属于不同的范畴,数据可视化通过降维,主成分分析等技术来分析数据的结构,模型可视化针对的是对机器学习模型本身的理解。深度神经网络又是最为复杂的机器学习模型,其可解释性与可视化性更加具有挑战性。网络模型为什么起作用,它是否足够好,图像识别是如何抽象出“猫”这个概念的?本段分析了几种典型深度神经网络可视化技术,详尽展示了前沿的可视化原理以及解释性效果。
云脑 Deepro 采用的 CNN 可视化
作为最有效的神经网络之一,CNN(Convolutional Neural Network, 卷积神经网络)解决了大量复杂的机器学习实际问题。CNN 被广泛应用于图像识别,语音识别,语义识别等系统。最近的研究表明 CNN 在包含自动驾驶在内的自动复杂智能系统中也大展身手。CNN 结构通常由一个或多个卷积层和顶端的全连通层组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。 相比较其他深度、前馈神经网络,CNN 需要的参数更少,能够更好的利用 GPU 作大规模并行处理,使之成为一种颇具吸引力的深度学习结构。
- 举个 CNN 的栗子:
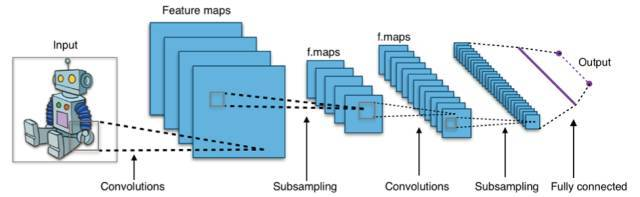
CNN 带来了高精度的预测模型,但是同时也留下重要的问题,在复杂的多层非线性网络结构中,究竟是什么让训练好的 CNN 模型给出近乎完美的预测答案?从 CNN 被大规模研究使用以来,学者们持续不断的探索可以理解和解释 CNN 的方法,其中可视化技术被证明是解释 CNN 内部结构最有效的方法之一。CNN 可视化技术包括,独立单元激活的可视化,图案和区域生成法,维度缩减空间表示法等。
独立单元激活的可视化
理解 CNN 内部网络的操作需要追踪多层网络中每一层的特征状态,而中间层的状态可以通过一种叫做 DeconvNet(Deconvolutional Network,去卷积网络)的技术反向映射回输入层的图像像素空间。DeconvNet 可以理解成另一个 CNN,利用同样的网络结构,包括卷积元,池化等,但相对于 CNN 是反向的。DeconvNet 主要作用是把 CNN 从像素学会的特征给还原成像素。一个多层 CNN 网络中每一层都会对应一个 DeconvNet,这样做的好处是得到的 DeconvNet 也是连续的,可以从任意一个输出层或者中间层反推到输入层的对应像素。

设定好 DeconvNet 后,如果对 CNN 网络的某一个激活元感兴趣,只需保留该单元而把其它单元设为 0 值后提交给 DeconvNet。DeconvNet 进行反池化,非线性化,去卷积化等操作,每一层 DeconvNet 重复此操作后直至到达最初的像素空间。

该图展示了 CNN 在 ImageNet 训练后得到的模型中每一层 CNN 中最强的激活特征单元(灰度图片),以及该激活单元通过 DeconvNet 后生成的像素图(彩色图片)。通过 DeconvNet 可以非常清楚的理解每一层 CNN 的作用。
通过 DeconvNet 分析得出,CNN 第一层训练学习的是以“边”为单位的基本元,第二层学习了“角”,“圆”等其他图像元,之后的第三层则开始学习复杂图案,而且会把相似的图案归类到一起。限于篇幅的原因后面更深的 CNN 层图片就不放出了,通过 DeconvNet 可以分析出 CNN 第四层开始出现物体的特征,比如“狗的脸部”,“鸟的腿部”等,第五层开始出现整个物体,以及物体的不同姿势和形态。
DeconvNet 清楚的证明了 CNN 高效的学习能力:通过学习图像中物体从小至大的特征而归纳出物体的整体特征。由此得出结论 CNN 网络中海量的内部隐藏特征元并不是随机或者不可解释的。该结论极大的增加了使用者对于 CNN 模型的理解,从而进一步信任模型的结果。DeconvNet 技术除了可以观察解释 CNN 内部结构外,还可以用来排除模型建立和调试时遇到的问题,以及通过分析内部结果来得到更好的模型。研究表明 CNN 模型一大优势就是预测精确度与内部隐藏层的局部结构有很强的关联。
图案和区域生成法
除了从 CNN 内部结构着手的 DeconvNet,图案和区域生成法也是有效的模型可视化手段。通过进行数值优化技术来生成图案,CNN 预测的结果可以被更好的可视化并带有解释性。以常见的图像分类问题来举例,CNN 在大量图像数据集上训练得出一个分类器模型:给定的一张图像会被标注为一个或多个类别,比如一张猫的照片会标记为猫或某种猫。对于一个特定的标注类,图案生成法通过数值优化生成可以表述为 CNN 分类分数的图像,也就是把 CNN 理解分类的过程给“画”了出来,如下图所示。

从生成的图像中可以看出 CNN 对于图像分类的判断与人对图像的判断有一定的相似之处,物体的部分特征可以表述出来。但是 CNN 又学会了自有和特有的判定条件,而有一些条件从人类的角度上来看可能是显而易见的错误,比如上图中鹅有多于两条腿等。通过图像生成可视化可以帮助理解 CNN 模型,从而进行更好的排错和优化。
图像生成法的另一类应用是图像的区域识别。区域识别是图像识别应用中广泛需求的技术,在安防人脸识别,自动驾驶环境识别等应用中是识别准确的关键步骤。图像生成法先建立 CNN 分类与图像空间的映射关系,通过反向梯度传导来更新映射关系中的权重,最终得到一个完整的类显著映射集。给定一个 CNN 指定分类和原始输入图像,该映射集可以生成特征图案。

利用单次反向梯度传导就可以快速得到上图中的映射集,从而可以显示出 CNN 判断分类的特征和区域。比如通过生成法可以理解 CNN 学习的过程同时包含从图像中找到小狗的位置,并加以判断这是一只小狗。用生成法产生的映射集可以进一步结合 GraphCut 颜色分割技术来进行图像区域识别和物体分割。 通过生成法产生的映射集划定了图像的大体边界,加上颜色分割技术的细节修正可以快速高效的识别物体区域。

生成法利用 CNN 分类模型实现了区域识别。原图中的物体不仅被标识为正确类别,同时也标注出物体的区域和边界。整个过程又可以通过映射集可视化。
云脑 Deepro 采用的 RNN 可视化
RNN(Recurrent Neural Network,循环神经网络)可以和 CNN 并称为当前两大最热门的深度神经网络。RNN 可以描述动态时间行为,因为和前馈神经网络(feedforward neural network)接受较特定结构的输入不同,RNN 将状态在自身网络中循环传递,因此可以接受更广泛的时间序列结构输入。RNN 与其衍生的 LSTM,GRU 网络被广泛应用于时序数据问题中,包括语言模型,手写识别,语音识别,机器翻译,视频识别等。
RNN 结构由来已久,Werbos 在 1988 年就提出用 RNN 学习时序任务。RNN 的循环元展开是深度神经网络中最“深”的网络结构,过深的网络结构容易导致权重梯度成指数级爆炸或消失,从而使模型失去学习的能力。因此 RNN 发展出很多强化变种,其中最成功的要数 LSTM(Long Short Term Memory,长短期记忆)和 GRU(Gated Recurrent Unit)。LSTM 和 GRU 引入 Gate 机制来控制记忆/遗忘时间序列中的信息,从而使模型更加有效的学习更长(深)的时序数据。

和很多深度学习结构一样,RNN 可以提供一个有效的预测模型,但是复杂的结构让使用者望而却步。时序数据有没有规律,时间关键点在哪里,哪些信息被记忆了,哪些被遗忘了,等等有诸多问题隐藏在黑箱之中。要想更好的理解 RNN,可视化技术是必不可少的,但是相比于 CNN 结构,RNN 可视化难度更大,网络中间层的控制和相互依赖性更高。这里列出一种基于 LSTM 的可视化技术,解释元与激活门统计法。
LSTM 解释元与激活门统计
从原理分析,LSTM 可以记录较长时间的时序信息,以及持续追踪当前时间的数据。但是在真实数据的模型上这种解释元理论很难被直接证明。研究通过字母级别语言模型建立的任务,进行对 RNN,LSTM,GRU 定性分析,加以对 Gate 激活的统计和比较,可以可视化出 LSTM 中的长期有效记忆,给出了一个合理的解释。
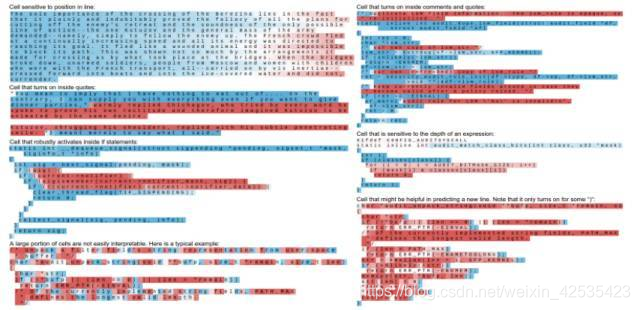
举例来说,LSTM 中某个单位元专注学习了文本输入的行数,数值从行始开始递减至行尾为 0,然后开始新的一行。另一个元记录并保证了成对出现的引号,括号等标点符号。
LSTM 文本标记可以用来理解 RNN 的内部结构,也可以用来做模型分析以更好的优化模型。

同样是字母级别语言模型实例,在上图中预测的错误原因得到分析,错误的模型结果可以通过标记可视化分解为多类原因。N-gram 占据 18% 的错误,意味着模型记录的字母序列过短;生僻字占据 9%,意味着需要增加训练覆盖率;空格,换行等标点占据了 37% 的错误,意味着 LSTM 需要更长的时序输入,或者需要加入断章断句等层次模型。可视化技术极大提高了模型的解释性,为提升模型效果提供了最直接的方案。
人工智能模型可视化实例
医疗影像诊断网络
近年来深度神经网络在生物与医疗影像领域的应用有着爆发式的增长。图像识别,图像分割极大的利用了大数据技术协助医生作出诊断。作为更进一步的发展,自动诊断系统也崭露头角,连连创造惊喜。GOOGLE 的糖尿病视网膜病变诊断系统得出的算法准确度已经高于美国委员会认证的眼科医生的检查结果。IBM 的沃森肿瘤诊断机器人已经入住海内外多家肿瘤治疗医院,成为医疗 AI 商业化的标杆。
医疗诊断本质上是一个标准的深度学习分类问题,然而普通的深度神经网络生成的模型隐藏了关键判断依据,缺乏解释性,无法被医疗系统和大众接受。只有具有可视化可解释性的模型才是医疗 AI 可用的模型。这里介绍一种综合网络结构 MDNet,可以读取医疗影像,生成诊断报告,同时可以根据症状描述获取对应的影像,并利用网络注意力机制提供诊断的依据。实例采用 BCIDR 膀胱癌诊断报告数据集。

为了更好的模型效果和更容易的解释性,模型整合 CNN,AAS 与 LSTM 几大模块。图像输入部分利用最新的 ResNet 网络作深层连接,并且利用 ensemble-connection 来连接 ResNet 的各个残差部分便于模型表述。在图像处理层与语言模型层之间的是 AAS 模块,基于注意力机制原理来增加训练的有效性。最终的诊断报告通过 LSTM 语言模型生成,其中有 LSTM 专注于挖掘训练数据中有区别的病症描述,而其他 LSTM 共享该 LSTM 的结果。这样做的好处是每一份数据的学习都可以增加诊断知识库,从给最终生成报告提供帮助。

如上图所示,对于给定的 CT 照片,MDNet 可以给出膀胱癌的诊断报告。左图表示诊断报告不仅给出了诊断结论,对于结论中每一个关键词也可以划出原图中对应区域作为判断依据。右图标示了不同级别的癌症判断,并且通过热力图展示了判断对应的区域。MDNet 可以有效的协助医疗机构进行大量诊断排查工作,极大的加强肿瘤防治效果。
结语
李开复在题为《人工智能的黄金时代》的万字演讲中提到,深度学习有四点挑战,分别是平台化、数据、计算及可解释性。人工智能的黄金时代已经到来,深度学习已经在图像,语音,大数据,自动驾驶等诸多领域占绝对优势。相较而言,模型可解释性的研究还处于起步阶段。云脑科技的小伙伴们潜心学习与研发更高效易用的 AI 平台,算法与可视化技术,助力深度学习应用的推广与落地,致力于推动整个人工智能产业的发展进程。
