在写爬取页面a标签下href属性的时候,有这样一个问题,如果a标签下没有href这个属性则会报错,如下:


百度了有师傅用正则匹配的,方法感觉都不怎么好,查了BeautifulSoup的官方文档,发现一个不错的方法,如下图:
官方文档链接:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
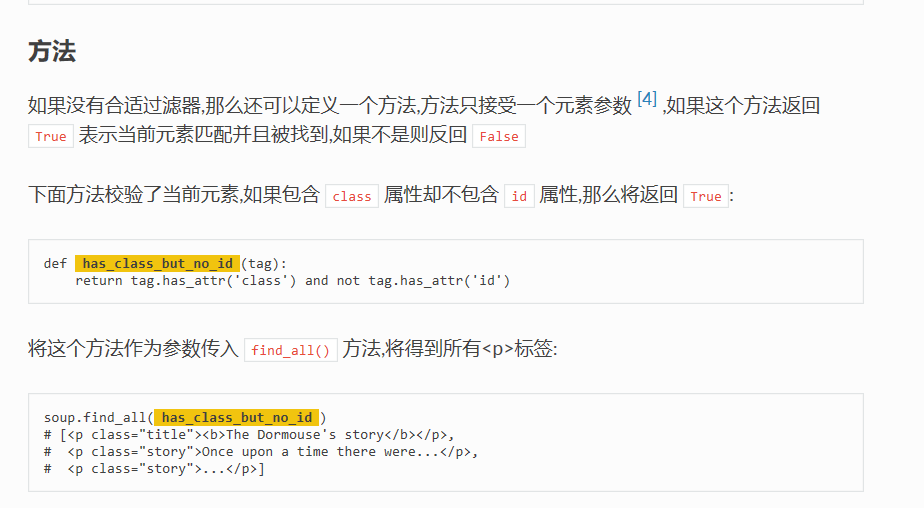
has_attr() 这个方法可以判断某标签是否存在某属性,如果存在则返回 True
解决办法:
为美观使用了匿名函数
soup_a = soup.find_all(lambda tag:tag.has_attr('href'))
最终代码:


1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 # Author:Riy 4 5 import time 6 import requests 7 import sys 8 import logging 9 from bs4 import BeautifulSoup 10 from requests.exceptions import RequestException 11 from multiprocessing import Process, Pool 12 13 14 logging.basicConfig( 15 level=logging.DEBUG, 16 format='%(levelname)-10s: %(message)s', 17 ) 18 19 20 class down_url: 21 def download(self, url): 22 '''爬取url''' 23 try: 24 start = time.time() 25 logging.debug('starting download url...') 26 response = requests.get(url) 27 page = response.content 28 soup = BeautifulSoup(page, 'lxml') 29 soup_a = soup.find_all(lambda tag:tag.has_attr('href')) 30 soup_a_href_list = [] 31 # print(soup_a) 32 for k in soup_a: 33 # print(k) 34 soup_a_href = k['href'] 35 if soup_a_href.find('.'): 36 # print(soup_a_href) 37 soup_a_href_list.append(soup_a_href) 38 print(f'运行了{time.time()-start}秒') 39 except RecursionError as e: 40 print(e) 41 return soup_a_href_list 42 43 44 def write(soup_a_href_list, txt): 45 '''下载到txt文件''' 46 logging.debug('starting write txt...') 47 with open(txt, 'a', encoding='utf-8') as f: 48 for i in soup_a_href_list: 49 f.writelines(f'{i}\n') 50 print(f'已生成文件{txt}') 51 52 53 def help_memo(self): 54 '''查看帮助''' 55 print(''' 56 -h or --help 查看帮助 57 -u or --url 添加url 58 -t or --txt 写入txt文件 59 ''') 60 61 62 def welcome(self): 63 '''欢迎页面''' 64 desc = ('欢迎使用url爬取脚本'.center(30, '*')) 65 print(desc) 66 67 68 def main(): 69 '''主函数''' 70 p = Pool(3) 71 p_list = [] 72 temp = down_url() 73 logging.debug('starting run python...') 74 try: 75 if len(sys.argv) == 1: 76 temp.welcome() 77 temp.help_memo() 78 elif sys.argv[1] in {'-h', '--help'}: 79 temp.help_memo() 80 elif sys.argv[1] in {'-u ', '--url'} and sys.argv[3] in {'-t', '--txt'}: 81 a = temp.download(sys.argv[2]) 82 temp.write(a, sys.argv[4]) 83 elif sys.argv[1] in {'-t', '--txt'}: 84 print('请先输入url!') 85 elif sys.argv[1] in {'-u', '--url'}: 86 url_list = sys.argv[2:] 87 print(url_list) 88 for i in url_list: 89 a = p.apply_async(temp.download, args=(i,)) 90 p_list.append(a) 91 for p in p_list: 92 print(p.get()) 93 else: 94 temp.help_memo() 95 96 print('输入的参数有误!') 97 except Exception as e: 98 print(e) 99 temp.help_memo() 100 101 102 if __name__ == '__main__': 103 main()