1.1 while与for循环
1、赋值魔法


#1. 序列解包: 将多个值的序列解开,然后放到序列的变量中。 x,y,z = 1,2,3 print(x,y,z) #the result : 1 2 3 x,y = y,x print(x,y,z) #the result : 2 1 3 #2. 链式赋值: 将同一个值赋给多个变量的捷径 x = y = z = 110 print(x,y,z) #the result :110 110 110
2、更复杂的条件
#1. 比较运算符 x != y x不等于y x is y x和y是同一个对象 x is not y x和y是不同的对象 x in y x是y容器(例如序列)的成员 x not in y x不是y容器(例如序列)的成员 #2. is:同一性运算 #作用:is运算符看起来和==一样,事实上却不同 x = y = [1,2,3] z = [1,2,3] print(x==y==z) #the result : True print(x is y) #the result : True print(x is z) #the result : False #3. in: 成员资格运算符 name = input('what is your name: ') if 's' in name: print('your name contains the letters "s" ') else: print("your name does not contain 's' ")
3、for循环
age = 66 count = 0 for i in range(3): guess_age = int(input('age:')) if guess_age == age: print("right") break elif guess_age < age: print("too small") else: print("too large") else: print("you have tried too many times")
4、while循环
作用:一般来说循环会一直执行到条件为假,或到序列元素用完时,但是有些时候会提前终止一些循环
1) break : 直接跳出循环
2) continue:跳出本次循环进行下一次循环
age = 66 count = 0 while count < 3: guess_age = int(input('age:')) if guess_age == age: print("right") break elif guess_age < age: print("too small") else: print("too large") count += 1 else: print("you have tried too many times")
1.2 读写文件
1、open函数用来打开文件
1. open(name[, mode[, buffering]]) 打开文件可传的参数
1. open函数使用一个文件名作为唯一的强制参数,然后返回一个文件对象。
2. 模式(mode)和缓冲(buffering)参数都是可选的
2. 打开文件的模式有
• r,只读模式(默认)。
• w,只写模式。【不可读;不存在则创建;存在则删除内容;】
• a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
注: "+" 表示可以同时读写某个文件
• w,只写模式。【不可读;不存在则创建;存在则删除内容;】
• w+,写读
• a+,同a
3、with语句
作用:将打开文件写在with中当对文件操作完成后with语句会自动帮关闭文件,避免忘记写f.close()
with open("data1.txt",'r',encoding = 'utf-8') as f: for line in f: print(line)
2、三种读操作比较
1. readline()每次读取一行,当前位置移到下一行
2. readlines()读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素
3. read(size)从文件当前位置起读取size个字节,如果不加size会默认一次性读取整个文件(适用于读取小文件)
#1. read()一次读取所有内容 '''aaa111 bbb222''' f = open(r"data.txt") print(f.read()) f.close() #2. readline(),每次只读取一行,光标下移 ''' 0: aaa111 1: bbb222 ''' f = open(r"data.txt") for i in range(2): print(str(i) + ": " + f.readline(),) #3. 一次读取所有,每行作为列表的一个值 '''['aaa111\n', 'bbb222\n']''' f = open(r"data.txt") print(f.readlines())
3、使用read()读文件
1. read(n)读取指定长度的文件
f = open(r"somefile.txt") print(f.read(7)) # Welcome 先读出 7 个字符 print(f.read(4)) #‘ to ‘ 接着上次读出 4 个字符 f.close()
2. seek(offset[, whence]) 随机访问
作用:从文件指定位置读取或写入
f = open(r"somefile.txt", "w") f.write("01234567890123456789") f.seek(5) f.write("Hello, World!") f.close() f = open(r"somefile.txt") print(f.read()) # 01234Hello, World!89
3. tell 返回当前读取到文件的位置下标
f = open(r"somefile.txt") f.read(1) f.read(2) print(f.tell()) # 3 3就是读取到文件的第三个字符
4、readline()读文件
作用:readline 的用法,速度是fileinput的3倍左右,每秒3-4万行,好处是 一行行读 ,不占内存,适合处理比较大的文件,比如超过内存大小的文件
f1 = open('test02.py','r') f2 = open('test.txt','w') while True: line = f1.readline() if not line: break f2.write(line) f1.close() f2.close()
5、readlines()读文件
作用:readlines会把文件都读入内存,速度大大增加,但是木有这么大内存,那就只能乖乖的用readline
f1=open("readline.txt","r") for line in f1.readlines(): print(line)
6、将data1.txt中内容读取并写入到data2.txt中
f1 = open('data1.txt','r') f2 = open('data2.txt','w') for line in f1: f2.write(line) f1.close() f2.close()
7、使用eval()方法将文件读取成字典
f = open('data1.txt') f1 = (f.read()) data = eval(f1) f.close() print(data) # 运行结果: {'k2': 'v2', 'k3': 'v3', 'k1': 'v1'}
8、将文件内容读取成列表
lock = [] f = open("password.txt") for name in f.readlines(): lock.append(name.strip('\n')) print(lock) 运行结果: ['aaa 111', 'bbb 222', 'ccc 333']
1.3 字符编码
1、几种常用编码
1. ASCII : 不支持中文
2. GBK : 是中国的中文字符,其包含了简体中文和繁体中文的字符
3. Unicode : 万国编码(Unicode 包含GBK)
1) Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码
2) 规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536
3)这里还有个问题:使用的字节增加了,那么造成的直接影响就是使用的空间就直接翻倍了
4. Utf-8 : 可变长码, 是Unicode 的扩展集
1) UTF-8编码:是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类
2)ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
3、python2与python3的几个区别
1. Python2默认 编码方式为ASCII, Python3 默认编码方式为UTF-8(是Unicode 的扩展集)
2. python2中字符串有str和unicode两种类型, python3 中字符串有str和字节(bytes) 两种类型
3. python3中不再支持u中文的语法格式
4、str与字节码(bytes): python3中字符串两种类型
比如定义变量: s = "人生苦短"
1. s是个字符串,python3中字符串本身存储的就是字节码
2. 如果这段代码是在解释器上输入的,那么这个s的格式就是解释器的编码格式,对于windows的cmd而言,就是gbk。
3. 如果将段代码是保存后才执行的,比如存储为utf-8,那么在解释器载入这段程序的时候,就会将s初始化为utf-8编码。
4. bytes是一种比特流,它的存在形式是01010001110这种,但为了在ide环境中让我们相对直观的观察,
它被表现成了b'\xe4\xb8\xad\xe6\x96\x87'这种形式
5、unicode与str : python2中字符串两种类型
1. 我们知道unicode是一种编码标准,具体的实现标准可能是utf-8,utf-16,gbk ......
2. python 在内部使用两个字节来存储一个unicode,使用unicode对象而不是str的好处,就是unicode方便于跨平台
6、python2和python3中编码转换
1. 在python3中字符串默认是unicode所以不需要decode(),直接encode成想要转换的编码如gb2312
2. 在python2中默认是ASCII编码,必须先转换成Unicode,Unicode 可以作为各种编码的转换的中转站
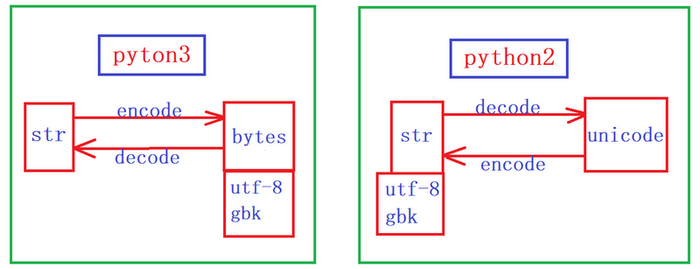
7、python2和python3中字符编码转换举例
1. python2进行字符编码转换
#!/usr/bin/env python #-*- coding:utf8 -*- ss = '北京市' #1、第一步先将utf8的字符串解码成unicode: str ----> Unicode #注:因为上面声明了使用utf8所以这里必须制定用utf8格式才能decode解码成Unicode unicode_type = ss.decode('utf8') # 将utf8的str格式转换成 unicode编码 print type(unicode_type) # type变成:<type 'unicode'> #2、第二步将unicode转换成gbk gbk_type = unicode_type.encode('gbk') # 将'unicode' encode编码成gbk格式的str print gbk_type.decode('gbk') # 只有将gbk格式的str再deode 解码成 unicode才能显示 "北京市" # print type( gbk_type.decode('gbk') ) # 能正常显示的只有:<type 'unicode'> 格式
>>> ss = '北京市' >>> us = ss.decode('gbk') # 将gbk格式的str解码成unicode >>> us2 = us.encode('utf8') # 将unicode变成utf8格式的str >>> us3 = us2.decode('utf8') # 由于cmd中默认是gbk所以要先显示正常汉子,还需要解码成Unicode >>> print us3 北京市 >>> print type(us3) <type 'unicode'>
2. python3进行字符编码转换
import sys print(sys.getdefaultencoding()) #在python3中打印出默认字符编码: utf-8 s = "你好" print(s.encode("gbk")) #将Unicode转换为gbk: b'\xc4\xe3\xba\xc3' print(s.encode("utf-8")) #将Unicode转换为utf-8: b'\xe4\xbd\xa0\xe5\xa5\xbd' print(s.encode("utf-8").decode("utf-8").encode("gb2312").decode("gb2312")) # 1. s.encode("utf-8") #将Unicode编码为utf-8 # 2. s.encode("utf-8").decode("utf-8") #将utf-8解码为Unicode在解码时必须指定现在的字符编码“utf-8” # 3. s.encode("utf-8").decode("utf-8").encode("gb2312") #将Unicode编码为”gb2312” # 4. s.encode("utf-8").decode("utf-8").encode("gb2312").decode("gb2312") #将gb2312解码为unicode # 注1:encode("utf-8") encode作用是将Unicode编码编码为指定编码(这里的utf-8是要编码成什么) # 注2:decode(“utf-8”) decode作用是将其他编码转化为Unicode编码(这里的utf-8是指定现在是什么编码)
8、顶部的:# -*- coding: utf-8 -*-或者# coding: utf-8目前有三个作用
1. 如果代码中有中文注释,就需要此声明。
2. 比较高级的编辑器会根据头部声明,将此作为代码文件的格式。
3. 程序会通过头部声明,解码初始化 u"人生苦短",这样的unicode对象,(所以头部声明和代码的存储格式要一致)。
9、python2 字符编码使用原则
1. decode early: 在输入或者声明字符串的时候,尽早地使用decode方法将字符串转化成unicode编码格式;
2. unicode everywhere: 然后在程序内使用字符串的时候统一使用unicode格式进行处理,比如字符串拼接等操作
3. encode late: 最后,在输出字符串的时候(控制台/网页/文件),通过encode方法将字符串转化为你所想要的编码格式,比如utf-8等
10、UnicodeDecodeError 解决方法
reload(sys)
sys.setdefaultencoding('utf-8')