1 项目流程介绍:
1.1 读取Hbase中的数据表,提取需要的字段,进行处理(统计每首歌有多少点击量),再次建表,将处理后的数据填充进去
1.2 2 此时的数据不是排序的,将数据排序后上传到HDFS中去
2 结果演示:
1 原始数据
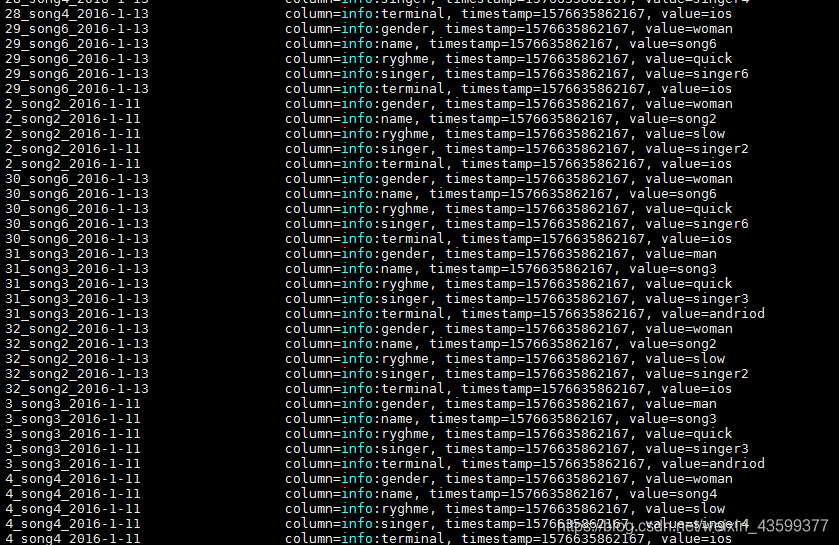
2 第一次处理。提取处理需要统计的结果数据,存放在第三方数据表中:namelist中

3 上传到HDFS中去,是排序后的最终结果
在这里插入代码片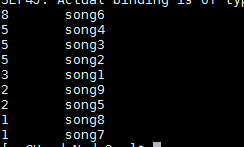
3 代码部分:
整个思路:分成了两个部分(job)
job1:读取Hbase中的原始数据表(music4),提取info列组:name(歌名)
map输出歌名 value 1。存储到namelist中去
job2 :将namelist排序,存储到HDFS中去:
代码如下:
package com.sheng.hbase;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class TopMusic {
//Hbase中的表
static final String TABLE_MUSIC = "music4";
//第三方表
static final String TABLE_NAMELIST = "namelist";
//将最终结果传入HDFS中
static final String OUTPUT_PATH = "topmusic";
/**
* 扫描每一行数据中的列info:name.并且从Hbase的原始表处理完后,加入到Hbase中的第三方表
*/
//只需要输出歌名和歌的点击次数,所以参数如下设置
static class ScanMusicMapper extends TableMapper<Text, IntWritable> {
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context)
throws IOException, InterruptedException {
//集合存储单元格数据
List<Cell> cells = value.listCells();
//循环每一个单元格数据
for (Cell cell : cells) {
//只扫描info列组下的name字段,也就是歌名
if (Bytes.toString(CellUtil.cloneFamily(cell)).equals("info")
&& Bytes.toString(CellUtil.cloneQualifier(cell)).equals("name")) {
//将歌名作为value值输出
context.write(new Text(Bytes.toString(CellUtil.cloneValue(cell))), // 单元格的唯一标识
new IntWritable(1));
/*
* song1 1
* song2 2
* song3 3
*
*/
}
}
}
}
/**
* 汇总每首歌曲播放总次数
*/
static class IntNumReducer extends TableReducer<Text, IntWritable, Text> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
//记录点击次数
int playCount = 0;
//将点击次数进行叠加
for (IntWritable num : values) {
playCount += num.get();
}
// 为Put操作指定行键
Put put = new Put(Bytes.toBytes(key.toString()));
/* 为Put操作指定列和值
*自己制定第三方表中的的列组和列名,因为只需要歌名和统计次数,所以如下
*addColumn:参数设置:1 列组名 2 列名 3 value值
*/
put.addColumn(Bytes.toBytes("details"), Bytes.toBytes("rank"), Bytes.toBytes(playCount));
//换句话话讲:就是将行键和value值进行插入到第三表:namelist
context.write(key, put);
}
}
/**
* 扫描全部歌曲名称并获得每首歌曲被播放次数.输出键/值:播放次数/歌名,输出目的地:HDSF文件
* 将表从Hbase中输出到HDFS中,只需要写mapper即可
*
* 由参数可知,输出的内容形式为:
* 1 song1
* 2 song2
* 3 song3
*/
static class ScanMusicNameMapper extends TableMapper<IntWritable, Text> {
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context)
throws IOException, InterruptedException {
//存储单元格信息
List<Cell> cells = value.listCells();
for (Cell cell : cells) {
//输出:value值 歌名
context.write(new IntWritable(Bytes.toInt(CellUtil.cloneValue(cell))),
new Text(Bytes.toString(key.get())));
}
}
}
/**
* 实现降序
*/
private static class IntWritableDecreaseingComparator extends IntWritable.Comparator {
@Override
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);// 比较结果取负数即可降序
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
/**
* 配置作业:播放统计
*/
static boolean musicCount() throws IOException, ClassNotFoundException, InterruptedException {
//创建提交任务
Job job = Job.getInstance(conf, "music-count");
// MapReduce程序作业基本配置
// job.setJarByClass(TopMusic.class);
job.setJar("E:\\jar\\HbaseMaven.jar");
//Reduce任务数
job.setNumReduceTasks(2);
//创建scan并扫描需要统计的字段
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
// 解决三方jar文件依赖:3)使用TableMapReduceUtil
// TableMapReduceUtil.addDependencyJars(job);// 推荐使用 加入分布缓存中
// 如果TABLE_NAMELIST存在则不做任何操作,如果HBASE表不存在则新建表
//创建配置文件的连接
Connection conn = ConnectionFactory.createConnection(conf);
Admin hAdmin = conn.getAdmin();
//第三方表:namelist
TableName outTN = TableName.valueOf(TABLE_NAMELIST);
//如果没有该表就创建
if (!hAdmin.isTableAvailable(outTN)) {
System.out.println("Table Not Exists! Create Table");
HTableDescriptor hTableDescriptor = new HTableDescriptor(outTN);
hTableDescriptor.addFamily(new HColumnDescriptor("details".getBytes()));
hAdmin.createTable(hTableDescriptor);
} else {
System.out.println("Table Exists! not Create Table");
}
// 使用hbase提供的工具类来设置job
/*
* mapper类 需要输出类型
* reduce类
*
*/
TableMapReduceUtil.initTableMapperJob(TABLE_MUSIC, scan, ScanMusicMapper.class, Text.class, IntWritable.class,
job);
TableMapReduceUtil.initTableReducerJob(TABLE_NAMELIST, IntNumReducer.class, job);
System.out.println(" job1...处理!Hbase-->Hbase");
return job.waitForCompletion(true);
}
///////////////////////////////////////////////////////////////////////
/**
* 配置作业:排序
*/
static boolean sortMusic() throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(conf, "sort-music");
// job.setJarByClass(TopMusic.class);
job.setJar("E:\\jar\\HbaseMaven.jar");
job.setNumReduceTasks(1);
job.setSortComparatorClass(IntWritableDecreaseingComparator.class);
TableMapReduceUtil.initTableMapperJob(TABLE_NAMELIST, new Scan(), ScanMusicNameMapper.class, IntWritable.class,
Text.class, job);
Path output = new Path(OUTPUT_PATH);
if (FileSystem.get(conf).exists(output))
FileSystem.get(conf).delete(output, true);
FileOutputFormat.setOutputPath(job, output);
System.out.println(" job2...处理");
return job.waitForCompletion(true);
}
/**
* 查看输出文件
*/
static void showResult() throws IllegalArgumentException, IOException {
FileSystem fs = FileSystem.get(conf);
InputStream in = null;
try {
in = fs.open(new Path(OUTPUT_PATH + "/part-r-00000"));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
static Configuration conf = HBaseConfiguration.create();
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
conf.set("mapreduce.app-submission.cross-platform", "true");// 允许跨平台
if (musicCount()) {
if (sortMusic()) {
showResult();
}
}
}
}
