计算机信息编码规则
按照以下原理将数据写读计算机中
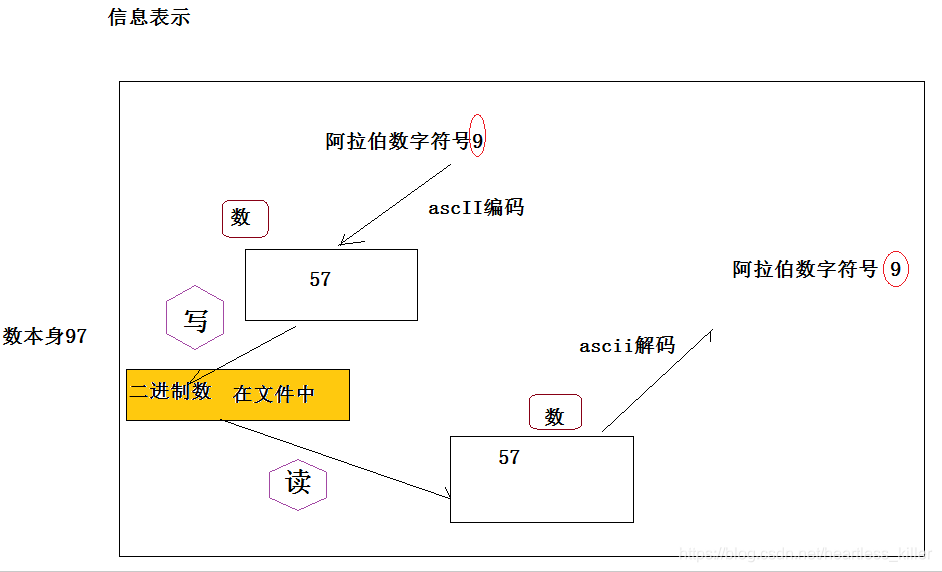 以阿拉伯数字9为例,写入的过程,先将其由asc2码表转化为“数”,再将其转化为二进制数存入文件中,则读取的过程,则为上述过程的逆过程。
以阿拉伯数字9为例,写入的过程,先将其由asc2码表转化为“数”,再将其转化为二进制数存入文件中,则读取的过程,则为上述过程的逆过程。
最常用的字节是八位的字节,即它包含八位的二进制数,即把八个二进制符号称为一个字节
GBK 英文字母1个byte一个汉字两个byte
UTF-8 对全世界大部分语言友好,英文字母1个byte,大部分中文3个byte

一般按照这周机制存储文本及其数据
对文件的操作
创建一个文件夹
File f = new File("f:/xx");
boolean mkdir = f.mkdir(); // 不能创建多级目录
System.out.println(mkdir);
创建一个文件夹
File fs = new File("f:/xx1/yy1");
boolean mkdirs = fs.mkdirs();
System.out.println(mkdirs);
创建文件
File file3 = new File("d:/xx/yy/cls.avi");
boolean createNewFile = file3.createNewFile();
System.out.println(createNewFile);
判断该file是否文件
File file = new File("f:/xx/yy/124.txt");
boolean ifFile = file.isFile();
System.out.println(ifFile); // false
判断该file是否文件夹
boolean directory = f.isDirectory();
System.out.println(directory);
获取文件的绝对路径
String absolutePath = f.getAbsolutePath();
System.out.println(absolutePath);
System.out.println("----------------------------------------");
获取文件的名字
String fName = file.getName();
System.out.println(fName); // false
获取上一级目录的file对象
File parentFile = file.getParentFile();
System.out.println(parentFile.getAbsolutePath());
获取上一级目录的路径字符串
String parent = file.getParent();
System.out.println(parent);
获取文件长度 字节(8个bit-- 二进制位)
long length = file.length();
System.out.println(length);
获取指定目录下的子节点的的字符串
File f2 = new File(c);
String[] listFilesString = f2.list();
for(String f1:listFilesString) {
System.out.println(f1);
}
获取指定目录下的子节点的File描述对象
File[] listFiles = f2.listFiles();
for(File f1:listFiles) {
System.out.println(f1.getAbsolutePath());
创建文件
File file3 = new File("d:/xx/yy/cls.avi");
boolean createNewFile = file3.createNewFile();
System.out.println(createNewFile);
重命名文件:其实可以把路径都给改了
file3.renameTo(new File("d:/xx/yy/bdls.avi"));
删除文件
boolean delete = file3.delete();
System.out.println(delete);
流的概念和作用
流的概念
流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
IO流的分类
根据处理数据类型的不同分为:字符流和字节流
根据数据流向不同分为:输入流和输出流
字符流和字节流
字符流的由来: 因为数据编码的不同,而有了对字符进行高效操作的流对象。本质其实就是基于字节流读取时,去查了指定的码表。字节流和字符流的区别:
(1)读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
(2)处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。
(3)字节流在操作的时候本身是不会用到缓冲区的,是文件本身的直接操作的;而字符流在操作的时候下后是会用到缓冲区的,是通过缓冲区来操作文件,我们将在下面验证这一点。
结论:优先选用字节流。首先因为硬盘上的所有文件都是以字节的形式进行传输或者保存的,包括图片等内容。但是字符只是在内存中才会形成的,所以在开发中,字节流使用广泛。
输入流和输出流
对输入流只能进行读操作,对输出流只能进行写操作,程序中需要根据待传输数据的不同特性而使用不同的流。
这么庞大的体系里面,常用的就那么几个,我们把它们抽取出来,如下图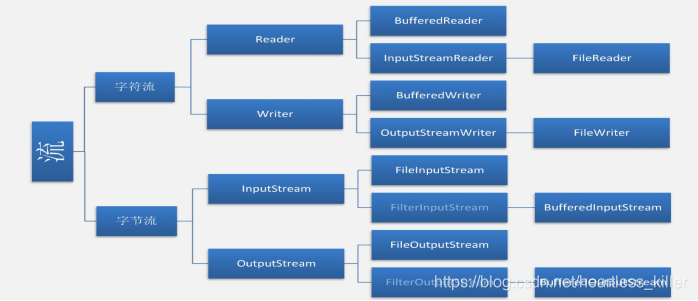
用FileInputStream读写文件
FileInputStream是一个字节流,一个字节一个字节读取
// 先构造一个fileinputstream的对象
FileInputStream fis =new FileInputStream( "f:/a.txt");
// 是一个字节流,一个字节一个字节读取
// 用int声明则表示读出的是编译表中的数字,当读的字节读出的int是-1时,则表示读到文件的末尾
int read=fis.read();
System.out.println(read);
// 若想得到是实际数据,则应该根据编码规则对其进行转码,用char声明,char代表一个英文字符
char read1=(char)fis.read();
System.out.println(read1);
用FileInputStream和FileOutputStream和byte数组读写文件
读
byte[] buf=new byte[9]; //指的是byte数组即字节数组,可以装入6个字节
// fis.read(buf) 一次读取部分长度的数据,并且读到的数据直接填入buf数组中,返回值是真实读到的字节数量
int num =fis.read(buf); //返回值num是真实读到的字节数量,当读到文件末尾时候读到的是-1,可用该性质写while循环,不包括换行和空格
String string =new String(buf,0,num); //将读出的数据转为字符串格式,String(buf,2,4)参数分别为要转为字符串的数组,初始位置,和结束位置
System.out.println(string);
System.out.println(num);
//-------------用byte数组和while反复读取------------------------------------------------
/* byte[] buf=new byte[8];
int num=0;
while( (num=fis.read(buf))!=-1){ //返回值num是真实读到的字节数量,当读到文件末尾时候读到的是-1,可用该性质写while循环,不包括换行和空格
String string =new String(buf,0,num); //打印的东西包括换行和空格
System.out.println(string);
}
fis.close();
写
FileOutputStream fos=new FileOutputStream("f:/a.txt",true); //加个参数true,则覆盖变为追加
String string="a你好";
byte[] bytes=string.getBytes(); //将字符串按指定编码规则--》将信息转化为指定字符串,默认gbk编码
fos.write(bytes);
fos.close();
dataoutputstream和datainputstream的读写文件
DataOutputStream是一个包装流,它可以将各种类型的数据在内部转成byte字节,然后利用
DataInputStream可以从字节流中直接转换出具体的数据类型
写文件
FileOutputStream写入文件中
DataOutputStream dos = new DataOutputStream(new FileOutputStream("d:/o.txt"));
// 写入一个整数 4个字节
int age = 18;
//dos.writeInt(age);
// 写一个long 8个字节
//dos.writeLong(19929);
// 写一个float数据 4个字节
//dos.writeFloat(18.8f);
// 写一个double数据 8个字节
//dos.writeDouble(18.8);
// 写一个boolean值,true其实写入了一个1 ,false其实写入了一个0
//dos.writeBoolean(true);
// writeutf在写真正的数据的同时,会在前面加上2个字节的长度记录
dos.writeUTF("张铁林");
dos.writeInt(48);
dos.close();
读文件
DataInputStream可以从字节流中直接转换出具体的数据类型
DataInputStream dis = new DataInputStream(new FileInputStream(“d:/o.txt”));
//int age = dis.readInt();
//long readLong = dis.readLong();
//float readFloat = dis.readFloat();
//double readDouble = dis.readDouble();
//boolean readBoolean = dis.readBoolean();
//String readUTF = dis.readUTF();
String name = dis.readUTF();
int age = dis.readInt();
System.out.println(name);
System.out.println(age);
Integer.parseInt("1");
用BufferedWriter和BufferedRead读写文件
为了提高字符流读写的效率,引入了缓冲机制,进行字符批量的读写,提高了单个字符读写的效率。BufferedReader用于加快读取字符的速度,BufferedWriter用于加快写入的速度
BufferedWriter
例`
public class BufferedWriterDemo {
public static void main(String[] args) throws Exception {
BufferedWriter bfwWriter=new BufferedWriter(new OutputStreamWriter(new FileOutputStream("f:/c.txt",true)));
//自动识别是不是UTF-8
//加true参数则是追加,不加则是覆盖
bfwWriter.write("66666牛\n呀D!w!!"); //写入字符串
bfwWriter.close(); //操作完毕后记住要将流关闭
}
}
BufferedRead
例
`public class BufferedReadDemo {
public static void main(String[] args) throws Exception {
BufferedReader fls= new BufferedReader(new InputStreamReader(new FileInputStream("f:/a.txt"),"UTF-8")); //如果文本包含中文记得加多个参数UTF-8,否则按默认GBK编码格式
//UTF-8对中英文友好,gbk对中文不友好
//BufferedReader包装了字节流,可以将指定的编码集将字节转成字符
//读取第一行
//String line=fls.readLine(); //将文本信息按行填入文件
//System.out.println(line);
//读取第二行
//line=fls.readLine();
//System.out.println(line);
while (true) { //用循环的方式按行读取文件
String line=fls.readLine();
if (line==null){break;}
System.out.println(line);
}
fls.close(); //将流关闭
}`
做一个单词计数器
package ioProject;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.util.HashMap;
import java.util.Map.Entry;
import java.util.Set;
public class Wordcount {public static void main(String[] args) throws Exception, FileNotFoundException {
BufferedReader fls= new BufferedReader(new InputStreamReader(new FileInputStream("f:/a.txt"),"UTF-8")); //如果文本包含中文记得加多个参数UTF-8,否则按默认GBK编码格式
HashMap<String,Integer> Wordcount=new HashMap<>();
while (true) { //将文本信息按行填入文件,用循环的方式
String line=fls.readLine();
if (line==null){break;}
String[] wordList=line.split(" ");
for (String i:wordList){
if(Wordcount.containsKey(i)){
Integer count =Wordcount.get(i);
Wordcount.put(i,count+1);}
else{Wordcount.put(i,1);}
}
}
fls.close();
Set<Entry<String,Integer>> entrySet = Wordcount.entrySet();
for (Entry x:entrySet){
System.out.println("key="+x.getKey()+"&&value="+x.getValue());
}
}
}
Java序列化与反序列化
Java序列化是指把Java对象转换为字节序列的过程;而Java反序列化是指把字节序列恢复为Java对象的过程。
import java.io.Serializable;
//implements Serializable 告诉jdk,这个类的对象是可被序列化的
public class User implements Serializable {
String name;
int age;
float salary;
long hairNum;
public User(String name, int age, float salary, long hairNum) {
super();
this.name = name;
this.age = age;
this.salary = salary;
this.hairNum = hairNum;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public float getSalary() {
return salary;
}
public void setSalary(float salary) {
this.salary = salary;
}
public long getHairNum() {
return hairNum;
}
public void setHairNum(long hairNum) {
this.hairNum = hairNum;
}
@Override
public String toString() {
return "[name=" + name + ", age=" + age + ", salary=" + salary + ", hairNum=" + hairNum + "]";
}
}
实现序列化接口的类
若将类实现了Serializable接口,则可以对类的对象进行序列化和反序列化
类似以下操作,implements Serializable 告诉jdk,这个类的对象是可被序列化的
public class User implements Serializable {
private String userName;
private String password;
}
用ObjectInputStream和ObjectOutputStream读写对象、ArrayList、HashMap等复杂的数据类型
读写对象
public class ObjectInputStreamDemo {
public static void main(String[] args) throws FileNotFoundException, IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("d:/u.obj"));
User user1 = new User("慕容复", 38, 2800, 8000);
User user2 = new User("扫地僧", 58, 3800, 0);
// writeObject(user)方法,要求user对象是可序列化的
oos.writeObject(user1);
oos.writeObject(user2);
oos.close();
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("d:/u.obj"));
User readObject1 = (User) ois.readObject(); //声明为User类
User readObject2 = (User) ois.readObject();
System.out.println(readObject1);
System.out.println(readObject2);
ois.close();
}
}
读写ArrayList
public class ArrayListObject {
public static void main(String[] args) throws Exception, IOException {
// 将一个list对象直接写入文件
User user1 = new User("慕容复", 38, 2800, 8000);
User user2 = new User("扫地僧", 58, 3800, 0);
ArrayList<User> users = new ArrayList<>();
users.add(user1);
users.add(user2);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("d:/users.list"));
oos.writeObject(users);
oos.close();
// 从文件中读取一个list对象
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("d:/users.list"));
ArrayList<User> userList = (ArrayList<User>) ois.readObject();
System.out.println(userList);
ois.close();
}
}
读写HashMap
/**
* 直接从文件中读取一个map对象
*/
@Test
public void testReadMap() throws Exception {
//从文件中写入一个对象
HashMap<String, User> users = new HashMap<>();
User user1 = new User("慕容复", 38, 2800, 8000);
User user2 = new User("扫地僧", 58, 3800, 0);
users.put(user1.getName(), user1);
users.put(user2.getName(), user2);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("d:/users.map"));
oos.writeObject(users);
oos.close();
// 从文件中读取一个list对象
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("d:/users.map"));
HashMap<String, User> userMap = (HashMap<String, User>) ois.readObject();
System.out.println(userMap);
}
