创建库
hive中有一个默认的库:
库名: default
库目录:hdfs://hdp20-01:9000/user/hive/warehouse
新建库:
create database databaseName;
库建好后,在hdfs中会生成一个库目录:
hdfs://hdp20-01:9000/user/hive/warehouse/db_order.db
展示所有库的名字:
show databases;
删除库
删除库操作
drop database dbname;
drop database if exists dbname; 如果该库存在就删除
默认情况下,hive 不允许删除包含表的数据库,有两种解决办法:
1、 手动删除库下所有表,然后删除库
2、 使用 cascade 关键字
drop database if exists dbname cascade;
默认情况下就是 restrict drop database if exists myhive ==== drop database if exists myhive restrict
. 建表
基本建表语句
use db_order; --选择该库
create table t_order(id string,create_time string,amount float,uid string);
表建好后,会在所属的库目录中生成一个表目录
/user/hive/warehouse/db_order.db/t_order
只是,这样建表的话,hive会认为表数据文件中的字段分隔符为 ^A
正确的建表语句为:
create table t_order(id string,create_time string,amount float,uid string)
row format delimited
fields terminated by ‘,’; --指定数据份分割的格式
这样就指定了,我们的表数据文件中的字段分隔符为 “,”
删除表
drop table t_order;
删除表的效果是:
hive会从元数据库中清除关于这个表的信息;
hive还会从hdfs中删除这个表的表目录;
内部表与外部表
内部表(MANAGED_TABLE):表目录按照hive的规范来部署,位于hive的仓库目录/user/hive/warehouse中
外部表(EXTERNAL_TABLE):表目录由建表用户自己指定
create external table t_access(ip string,url string,access_time string)
row format delimited
fields terminated by ‘,’
location ‘/access/log’;
外部表和内部表的特性差别:
1、内部表的目录在hive的仓库目录中 VS 外部表的目录由用户指定
2、drop一个内部表时:hive会清除相关元数据,并删除表数据目录
3、drop一个外部表时:hive只会清除相关元数据;
一个hive的数据仓库,最底层的表,一定是来自于外部系统,为了不影响外部系统的工作逻辑,在hive中可建external表来映射这些外部系统产生的数据目录;
然后,后续的etl操作,产生的各种表建议用managed_table
分区表
分区表的实质是:在表目录中为数据文件创建分区子目录,以便于在查询时,MR程序可以针对分区子目录中的数据进行处理,缩减读取数据的范围。
比如,网站每天产生的浏览记录,浏览记录应该建一个表来存放,但是,有时候,我们可能只需要对某一天的浏览记录进行分析
这时,就可以将这个表建为分区表,每天的数据导入其中的一个分区;
当然,每日的分区目录,应该有一个目录名(分区字段)
一个分区字段的实例
示例如下:
1、创建带分区的表
create table t_access(ip string,url string,access_time string)
partitioned by(dt string) --在这里指定分区的属性
row format delimited
fields terminated by ‘,’;
注意:分区字段不能是表定义中的已存在字段
2、向分区中导入数据
load data local inpath ‘/root/access.log.2017-08-04.log’ into table t_access partition(dt=‘20170804’);
load data local inpath ‘/root/access.log.2017-08-05.log’ into table t_access partition(dt=‘20170805’);
3、针对分区数据进行查询
a、统计8月4号的总PV:
select count(*) from t_access where dt=‘20170804’;
实质:就是将分区字段当成表字段来用,就可以使用where子句指定分区了
b、统计表中所有数据总的PV:
select count(*) from t_access;
实质:不指定分区条件即可
CTAS建表语法
1、可以通过已存在表来建表:
create table t_user_2 like t_user;
新建的t_user_2表结构定义与源表t_user一致,但是没有数据
2、在建表的同时插入数据
create table t_access_user
as
select ip,url from t_access;
t_access_user会根据select查询的字段来建表,同时将查询的结果插入新表中
将数据文件导入hive的表
方式1:导入数据的一种方式:
手动用hdfs命令,将文件放入表目录;
方式2:在hive的交互式shell中用hive命令来导入本地数据到表目录
hive>load data local inpath ‘/root/order.data.2’ into table t_order;
方式3:用hive命令导入hdfs中的数据文件到表目录
hive>load data inpath ‘/access.log.2017-08-06.log’ into table t_access partition(dt=‘20170806’);
注意:导本地文件和导HDFS文件的区别:
本地文件导入表:复制
hdfs文件导入表:移动
将hive表中的数据导出到指定路径的文件
1、将hive表中的数据导入HDFS的文件
insert overwrite directory ‘/root/access-data’
row format delimited fields terminated by ‘,’
select * from t_access;
2、将hive表中的数据导入本地磁盘文件
insert overwrite local directory ‘/root/access-data’
row format delimited fields terminated by ‘,’
select * from t_access limit 100000;
hive文件格式
暂时没懂后面再弄懂吧
HIVE支持很多种文件格式: SEQUENCE FILE | TEXT FILE | PARQUET FILE | RC FILE
create table t_pq(movie string,rate int) stored as textfile;
create table t_pq(movie string,rate int) stored as sequencefile;
create table t_pq(movie string,rate int) stored as parquetfile;
演示:
1、先建一个存储文本文件的表
create table t_access_text(ip string,url string,access_time string)
row format delimited fields terminated by ‘,’
stored as textfile;
导入文本数据到表中:
load data local inpath ‘/root/access-data/000000_0’ into table t_access_text;
2、建一个存储sequence file文件的表:
create table t_access_seq(ip string,url string,access_time string)
stored as sequencefile;
从文本表中查询数据插入sequencefile表中,生成数据文件就是sequencefile格式的了:
insert into t_access_seq
select * from t_access_text;
3、建一个存储parquet file文件的表:
create table t_access_parq(ip string,url string,access_time string)
stored as parquetfile;
数据类型
基本数据类型
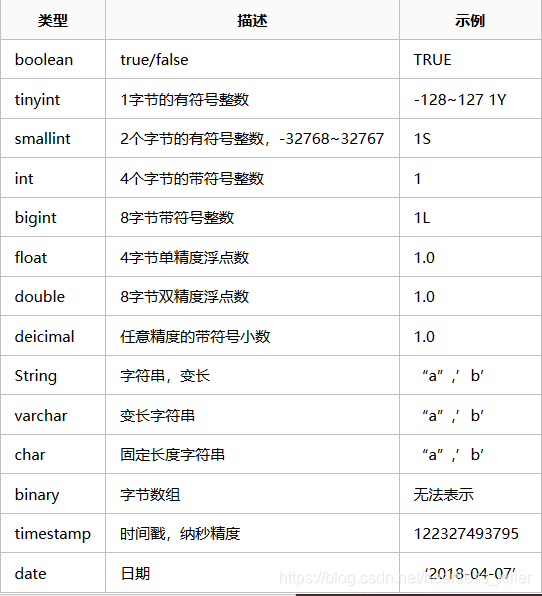 和其他的SQL语言一样,这些都是保留字。需要注意的是所有的这些数据类型都是对Java中接口的实现,因此这些类型的具体行为细节和Java中对应的类型是完全一致的。例如,string类型实现的是Java中的String,float实现的是Java中的float,等等。
和其他的SQL语言一样,这些都是保留字。需要注意的是所有的这些数据类型都是对Java中接口的实现,因此这些类型的具体行为细节和Java中对应的类型是完全一致的。例如,string类型实现的是Java中的String,float实现的是Java中的float,等等。
复合类型

array数组类型
数组内的所有数据必须相同类型
array数组类型 类似Python中的数组
arrays: ARRAY<data_type> (Note: negative values and non-constant expressions are allowed as of Hive 0.14.)
示例:array类型的应用
假如有如下数据需要用hive的表去映射:
战狼2,吴京:吴刚:龙母,2017-08-16
三生三世十里桃花,刘亦菲:痒痒,2017-08-20
设想:如果主演信息用一个数组来映射比较方便
建表:
create table t_movie(moive_name string,actors array < string >,first_show date)
row format delimited fields terminated by ‘,’
collection items terminated by ‘:’; --集合中 的元素按什么切割,指定array中的数据分隔规则
导入数据:
load data local inpath ‘/root/movie.dat’ into table t_movie;
查询:
select * from t_movie;
select moive_name,actors[0] from t_movie; --查array第一个
select moive_name,actors from t_movie where array_contains(actors,‘吴刚’); --查有吴刚的array
select moive_name,size(actors) from t_movie; --查array长度
select moive_name,size(actors) sort_array(Array) --按自然顺序对数组进行排序并返回
map类型
类似Python中的map,键值对这样
maps: MAP<primitive_type, data_type> (Note: negative values and non-constant expressions are allowed as of Hive 0.14.)
- 假如有以下数据:
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28
2,lisi,father:mayun#mother:huangyi#brother:guanyu,22
3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29
4,mayun,father:mayongzhen#mother:angelababy,26
可以用一个map类型来对上述数据中的家庭成员进行描述
-
建表语句:
create table t_person(id int,name string,family_members map<string,string>,age int)
row format delimited fields terminated by ‘,’
collection items terminated by ‘#’ --集合中 的元素按什么切割,,即map中的元素按#切割
map keys terminated by ‘:’; --key,value按什么切割 -
查询
select * from t_person;
取map字段的指定key的值
select id,name,family_members[‘father’] as father from t_person;
取map字段的所有key
select id,name,map_keys(family_members) as relation from t_person;
取map字段的所有value
select id,name,map_values(family_members) from t_person;
select id,name,map_values(family_members)[0] from t_person;
综合:查询有brother的用户信息
select id,name,father
from
(select id,name,family_members[‘brother’] as father from t_person) tmp
where father is not null;
struct类型
字段集合,类型可以不同
1) 假如有如下数据:
1,zhangsan,18:male:beijing
2,lisi,28:female:shanghai
其中的用户信息包含:年龄:整数,性别:字符串,地址:字符串
设想用一个字段来描述整个用户信息,可以采用struct
2) 建表:
create table t_person_struct(id int,name string,info structage:int,sex:string,addr:string)
row format delimited fields terminated by ‘,’
collection items terminated by ‘:’; --集合里的数据按这样分隔,即struct
3) 查询
select * from t_person_struct;
select id,name,info.age from t_person_struct;
hive查询语法
提示:在做小数据量查询测试时,可以让hive将mrjob提交给本地运行器运行,可以在hive会话中设置如下参数:
hive> set hive.exec.mode.local.auto=true;
基本查询示例
select * from t_access;
select count(*) from t_access;
select max(ip) from t_access;
条件查询
select * from t_access where access_time<‘2017-08-06 15:30:20’
select * from t_access where access_time<‘2017-08-06 16:30:20’ and ip>‘192.168.33.3’;
注:where子句不可跟聚合函数
6.3.
join关联查询示例
假如有a.txt文件
a,1
b,2
c,3
d,4
假如有b.txt文件
a,xx
b,yy
d,zz
e,pp
进行各种join查询:
1、inner join(join)
select
a.name as aname,
a.numb as anumb,
b.name as bname,
b.nick as bnick
from t_a a
join t_b b
on a.name=b.name
结果:
±-------±-------±-------±-------±-+
| aname | anumb | bname | bnick |
±-------±-------±-------±-------±-+
| a | 1 | a | xx |
| b | 2 | b | yy |
| d | 4 | d | zz |
±-------±-------±-------±-------±-+
2、left outer join(left join)
select
a.name as aname,
a.numb as anumb,
b.name as bname,
b.nick as bnick
from t_a a
left outer join t_b b
on a.name=b.name
结果:

3、right outer join(right join)
select
a.name as aname,
a.numb as anumb,
b.name as bname,
b.nick as bnick
from t_a a
right outer join t_b b
on a.name=b.name
结果:
4、full outer join(full join)
select
a.name as aname,
a.numb as anumb,
b.name as bname,
b.nick as bnick
from t_a a
full join t_b b
on a.name=b.name;
结果:
group by分组聚合
select dt,count(*),max(ip) as cnt from t_access group by dt;
select dt,count(*),max(ip) as cnt from t_access group by dt having dt>‘20170804’;
select
dt,count(*),max(ip) as cnt
from t_access
where url=‘http://www.edu360.cn/job’
group by dt having dt>‘20170804’;
注意: 一旦有group by子句,那么,在select子句中就不能有 (分组字段,聚合函数) 以外的字段
为什么where必须写在group by的前面,为什么group by后面的条件只能用having
因为,where是用于在真正执行查询逻辑之前过滤数据用的
having是对group by聚合之后的结果进行再过滤;
上述语句的执行逻辑:
1、where过滤不满足条件的数据
2、用聚合函数和group by进行数据运算聚合,得到聚合结果
3、用having条件过滤掉聚合结果中不满足条件的数据
子查询
select id,name,father
from
(select id,name,family_members[‘brother’] as father from t_person) tmp
where father is not null;
常用内置函数
这里不全,这里没有,可以看看这里
类型转换函数
select cast(“5” as int) from dual; --字符串转int
select cast(“2017-08-03” as date) ; --字符串转date
select cast(current_timestamp as date); --时间戳转date
示例:
1 1995-05-05 13:30:59 1200.3
2 1994-04-05 13:30:59 2200
3 1996-06-01 12:20:30 80000.5
create table t_fun(id string,birthday string,salary string)
row format delimited fields terminated by ‘,’;
select id,cast(birthday as date) as bir,cast(salary as float) from t_fun;
数学运算函数
select round(5.4) from dual; ## 5 四舍五入
select round(5.1345,3) from dual; ##5.135 保留几位小数
select ceil(5.4) from dual; // select ceiling(5.4) from dual; ## 6
select floor(5.4) from dual; ## 5 ##取整?
select abs(-5.4) from dual; ## 5.4 ##计算a的绝对值
select greatest(3,5,6) from dual; ## 6 ##至少输入两个参数 #求最大值
select least(3,5,6) from dual; #至少输入两个参数 #求最小值,计算的是输入的几个变量的最小值
rand() ##每行返回一个DOUBLE型随机数seed是随机因子
示例:
有表如下:

select greatest(cast(s1 as double),cast(s2 as double),cast(s3 as double)) from t_fun2;
结果:
±--------±-+
| _c0 |
±--------±-+
| 2000.0 |
| 9800.0 |
±--------±-+
注:与select max(age) from t_person; 聚合函数
select min(age) from t_person; 聚合函数
不同,这是聚合函数
字符串函数
substr(string, int start) ## 对于字符串A,从start位置开始截取字符串并返回
substring(string, int start)
示例:select substr(“abcdefg”,2) from dual;
substr(string, int start, int len) ##对于二进制/字符串A,从start位置开始截取长度为length的字符串并返回
substring(string, int start, int len)
示例:select substr(“abcdefg”,2,3) from dual;
concat(string A, string B…) ## 拼接字符串
concat_ws(string SEP, string A, string B…) ## 拼接字符串而且中间还加一个分割符SEP
示例:select concat(“ab”,“xy”) from dual;
select concat_ws(".",“192”,“168”,“33”,“44”) from dual;
length(string A)
示例:select length(“192.168.33.44”) from dual;
split(string str, string pat)
示例:select split(“192.168.33.44”,".") from dual; 错误的,因为.号是正则语法中的特定字符
select split(“192.168.33.44”,"\.") from dual;
upper(string str) ##转大写
length(string A) ##返回字符串的长度
聚合函数
count(*) ##统计总行数,包括含有NULL值的行,
count(expr) ##统计提供非NULL的expr表达式值的行数
count(DISTINCT expr[, expr…]) ##统计提供非NULL且去重后的expr表达式值的
=================================================
sum(col) ##sum(col),表示求指定列的和
sum(DISTINCT col) ##表示求去重后的列的和
==================================================
avg(col) ##表示求指定列的平均值,
avg(DISTINCT col) ##表示求去重后的列的平均值
================================================
min(col) ##求指定列的最小值
max(col) ##求指定列的最大值
==============================================
行转列函数:
explode()
假如有以下数据:
1,zhangsan,化学:物理:数学:语文
2,lisi,化学:数学:生物:生理:卫生
3,wangwu,化学:语文:英语:体育:生物
映射成一张表:
create table t_stu_subject(id int,name string,subjects array)
row format delimited fields terminated by ‘,’
collection items terminated by ‘:’;
使用explode()对数组字段“炸裂”
然后,我们利用这个explode的结果,来求去重的课程:
select distinct tmp.sub
from
(select explode(subjects) as sub from t_stu_subject) tmp;
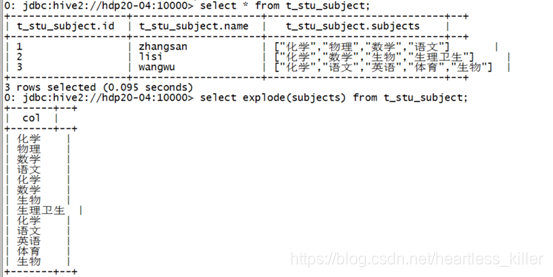 然后,我们利用这个explode的结果,来求去重的课程:
然后,我们利用这个explode的结果,来求去重的课程:
select distinct tmp.sub
from
(select explode(subjects) as sub from t_stu_subject) tmp;
表生成函数 lateral view (不记得了,要重新看看)
select id,name,tmp.sub
from t_stu_subject lateral view explode(subjects) tmp as sub;
理解: lateral view 相当于两个表在join
左表:是原表
右表:是explode(某个集合字段)之后产生的表
而且:这个join只在同一行的数据间进行
那样,可以方便做更多的查询:
比如,查询选修了生物课的同学
select a.id,a.name,a.sub from
(select id,name,tmp.sub as sub from t_stu_subject lateral view explode(subjects) tmp as sub) a
where sub=‘生物’;
json_tuple函数
从一个JSON字符串中获取多个键并作为一个元组返回,与get_json_object不同的是此函数能一次获取多个键值
示例:
select json_tuple(json,‘movie’,‘rate’,‘timeStamp’,‘uid’) as(movie,rate,ts,uid) from t_rating_json;
产生结果:
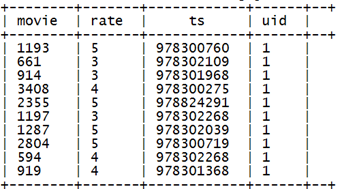
条件控制函数
case when
语法:
CASE [ expression ]
WHEN condition1 THEN result1
WHEN condition2 THEN result2
…
WHEN conditionn THEN resultn
ELSE result
END
示例:
select id,name,
case
when age<28 then ‘youngth’
when age>27 and age<40 then ‘zhongnian’
else ‘old’
end
from t_user;
IF
select id,if(age>25,‘working’,‘worked’) from t_user;
select moive_name,if(array_contains(actors,‘吴刚’),‘好电影’,'rom t_movie;
mg.cn/20191013211006107.png)
分析函数:row_number() over()——分组TOPN
有如下数据:
1,18,a,male
2,19,b,male
3,22,c,female
4,16,d,female
5,30,e,male
6,26,f,female
需要查询出每种性别中年龄最大的2条数据
实现:
使用row_number函数,对表中的数据按照性别分组,按照年龄倒序排序并进行标记
hql代码:
select id,age,name,sex,
row_number() over(partition by sex order by age desc) as rank
from t_rownumber

然后,利用上面的结果,查询出rank<=2的即为最终需求
select id,age,name,sex
from
(select id,age,name,sex,
row_number() over(partition by sex order by age desc) as rank
from t_rownumber) tmp
where rank<=2;
sum over函数
需求:将以下数据做多一行是按时间为顺序,做累计报表
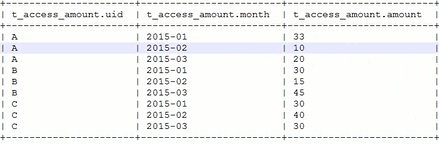
select uid,month,amount,
sum(amount) over (partition by uld order by month rows between unbounded preceding and current row) as accumulate
from t_access_amount --根据uid分组,根据month为顺序来排序,回诉前面所有行加起来
hive实现wordCount
SELECT word,count(1)
FROM(SELECT explode(split(sentence," "))AS word
from t_wc
) tmp
GROUP BY word;
