在建立Socket的时候,socket函数需要指定是IPv4还是IPv6,分别对应AF_INET和AF_INET6,这是网络层的。其次,还需指定是TCP还是UDP,这是传输层的。TCP是基于数据流的,所以设置为SOCK_STREAM,UDP是基于数据报的,所以设置为SOCK_DGRAM。
基于TCP协议的Socket程序函数调用过程:
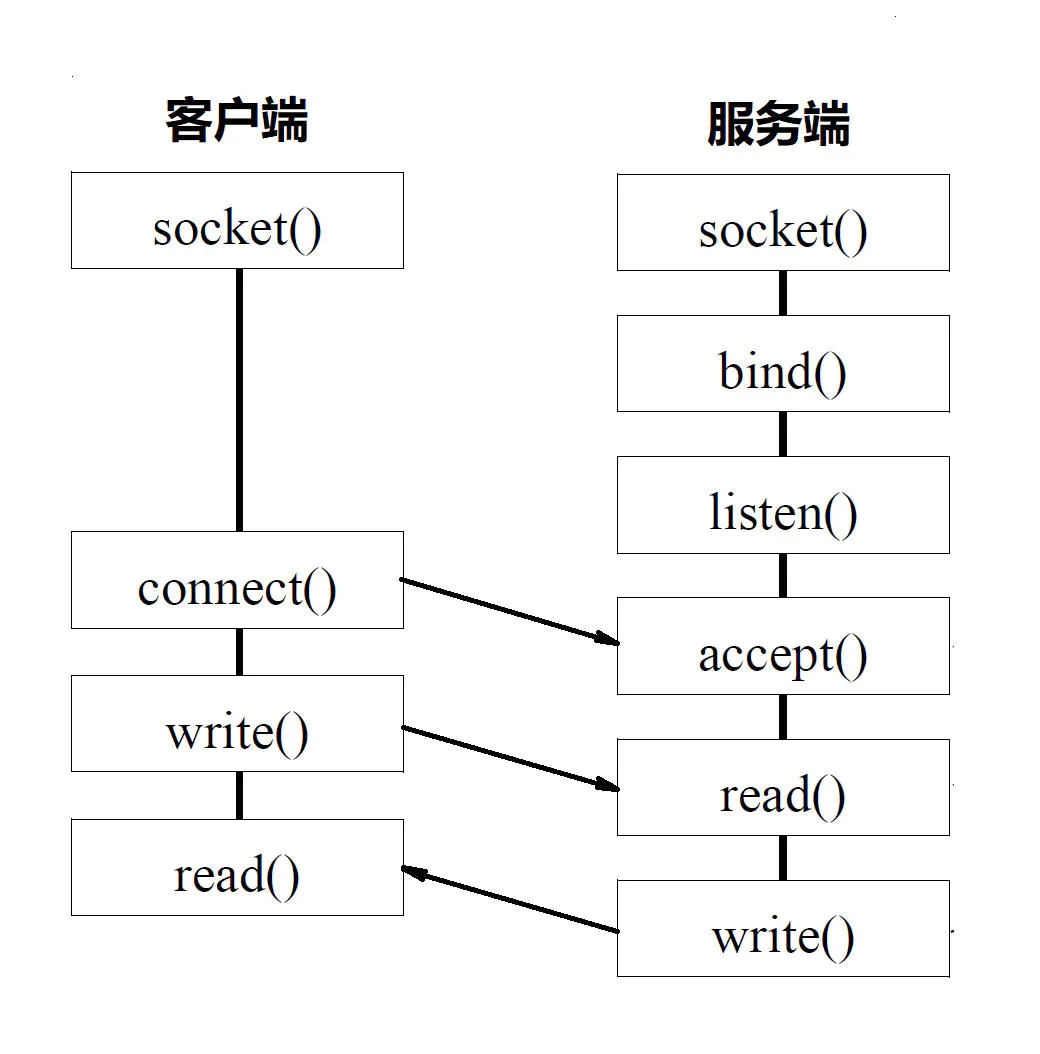
服务端要先监听一个端口,一般是先调用bind函数,给这个Socket赋予一个IP地址和端口。当服务器有了IP和端口,就可以调用listen函数进行监听。此时服务器进入监听状态,客户端可以发起连接。
在Linux内核中,为每个Socket维护两个队列。一个是已经建立了连接的队列,这时候连接三次握手已经完毕,处于established状态;一个是还没有完全建立连接的队列,这个时候三次握手还没完成,处于syn_rcvd的状态。
接下来,服务端调用accept函数,拿出一个已经完成的连接进行处理。如果还没有完成,就要等待。
在服务端等待的时候,客户端可以通过connect函数发起连接。先在参数中指明要连接的IP地址和端口号,然后开始发起三次握手。内核会给客户端分配一个临时的端口。一旦握手成功,服务端的accept就会返回另一个Socket。监听的Socket和真正用来传输数据的Socket是两个,一个叫作监听Socket,一个叫作已连接Socket。
连接建立成功之后,双方开始通过read和write函数来读写数据。说TCP的Socket就是一个文件流,是非常准确的。因为Socket在Linux中就是以文件的形式存在的。除此之外,还存在文件描述符,写入和读出,就是通过文件描述符。
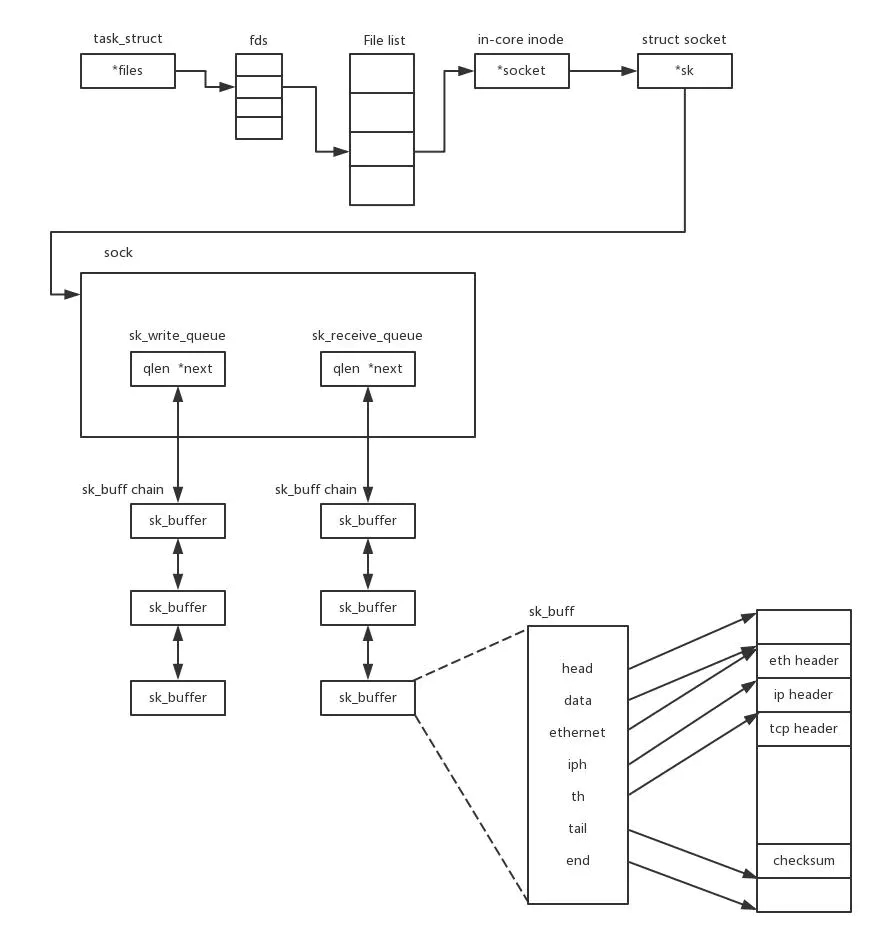
在内核中,Socket是一个文件,那对应就有文件描述符。每一个进程都有一个数据结构task_struct,里面指向一个文件描述符数组,来列出这个进程打开的所有文件的文件描述符。文件描述符是一个整数,是这个数组的下标。
这个数组中的内容是一个指针,指向内核中所有打开的文件的列表。既然是一个文件,就会有一个inode,只不过Socket对应的inode不像真正的文件系统一样,保存在硬盘上,而是在内存中。在这个inode中,指向了Socket在内核中的Socket结构。在这个结构里面,主要的是两个队列,一个是发送队列,一个是接收队列。在这两个队列里面保存的是一个缓存sk_buff。这个缓存里面能够看到完整的包的结构。

 基于UDP协议的Scoket程序函数调用过程:
基于UDP协议的Scoket程序函数调用过程:

对于UDP来说,不需要三次握手,也就不需要调用listen和connect。但是,UDP的交互仍然需要IP和端口号,因此也需要bind。UDP是没有维护连接状态的,因此不需要每对建立一组Socket,而是只要有一个Socket,就能够和多个客户端通信。也正是因为没有连接状态,每次通信的时候,都调用sendto和recvfrom,都可以传入IP地址和端口。
服务器如何接更多的项目:
系统会用一个四元组来标识一个TCP连接。
{本机IP, 本机端口, 对端IP, 对端端口}
服务器的IP和端口是本能随意改变的,所以能改变的只有客户端的IP和对端端口。因此理论上最大TCP连接数 = 客户端IP数 * 客户端端口数。对IPv4,客户端的IP数最多为2^32,端口数为2^16,也就是服务端单机理论上最大的TCP连接数是2^48。
显然,这只是理论上来说,事实上远远达不到。首先主要是文件描述符限制,Socket都是文件,所以首先要通过ulimit配置文件描述符的数目;另一个限制是内存,按上面的数据结构,每个TCP连接都要占用一定的内存,操作系统是有限的。
所以,我们要在有限的资源下接更多的项目,就必须降低每个项目消耗的资源数量。
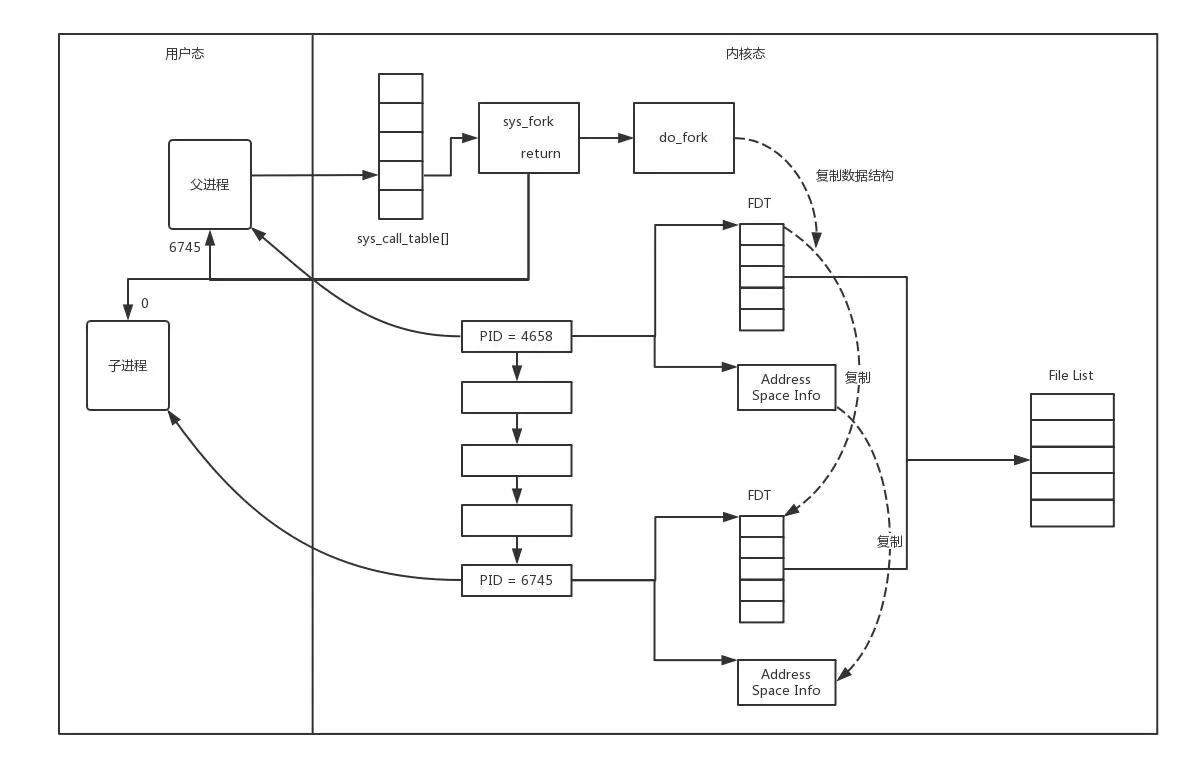
方式一:多进程
一旦建立一个连接,就会有一个已连接Socket,这个时候创建一个子进程,然后将基于已连接Socket的交互交给这个新的子进程来做。
在Linux中,创建子进程使用fork函数。这是在父进程的基础上完全拷贝一个子进程。在Linux内核中,会复制文件描述符的列表,也会复制内存空间,还会复制一条记录当前执行到了哪一行程序的进程。显然,复制的时候在调用fork,复制完毕之后,父进程和子进程都会记录当前刚刚执行完fork。这两个进程刚复制完的时候,几乎一模一样,只是根据fork的返回值来区分到底是父进程还是子进程。如果返回0,则是子进程;如果返回其他整数,就是父进程。
方式二:多线程
相比于进程,线程要轻量级的多。在Linux下,通过pthread_create创建一个进程,也是调用do_fork。不同的是,虽然新的线程在task列表会新创建一项,但是很多资源,例如文件描述符、进程空间、还是共享的,只不过多了一个引用而已。
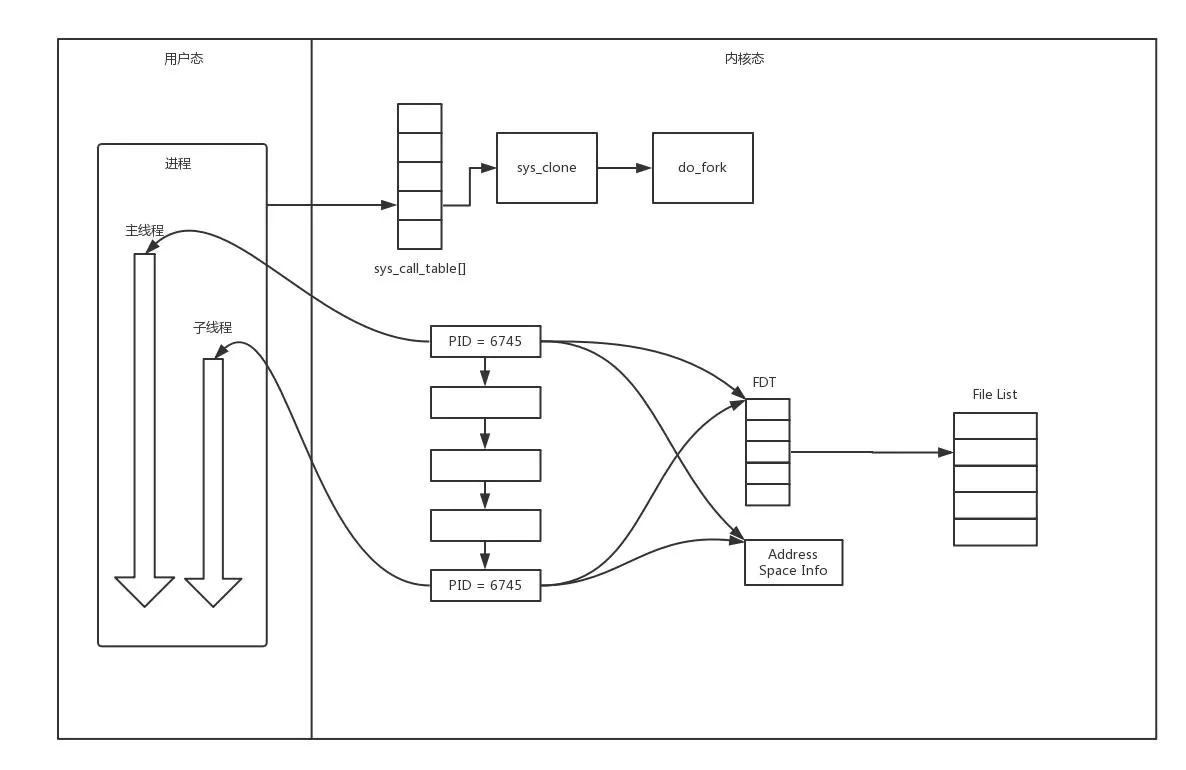
新的进程也可以通过已连接Socket处理请求,从而达到并发处理的目的。
上面基于进程或者线程模型的,其实还是有问题的。新到来一个TCP连接,就需要分配一个进程或线程,一台机器无法创建很多进程和线程。有个C10K,它的意思是一台机器要维护10万个连接,就要创建1万个进程或者线程,那么操作系统是无法承受的。
方式三:IO多路复用,一个线程维护多个Socket
由于Socket是文件描述符,因而某个线程盯的所有的Socket,都放在一个文件描述符集合fd_set中,然后调用select函数来监听文件描述符集合是否有变化。一旦有变化,就会依次查看每个文件描述符。那些发生变化的文件描述符在fd_set对应的位都设为1,表示Socket可读或者可写,从而可以进行读写操作,然后再调用select,接着盯着下一轮的变化。
方式四:IO多路复用,从select到epoll
上面的select函数还是有问题的,因为每次Socket所在的文件描述符集合中有Socket发生变化的时候,都需要通过轮询的方式,这会大大影响连接数。因此使用select,需要设置能够同时盯着的文件描述符的数量FD_SETSIZE。
如果改成事件通知的方式,情况会好很多,就不需要轮询文件描述符了。而是当集合发生变化时,主动通知线程,然后线程再做出相应的操作。
能完成这件事情的函数叫epoll,它在内核中的实现不是通过轮询的方式,而是通过注册callback函数的方式,当某个文件描述符发生变化的时候,就会主动通知。
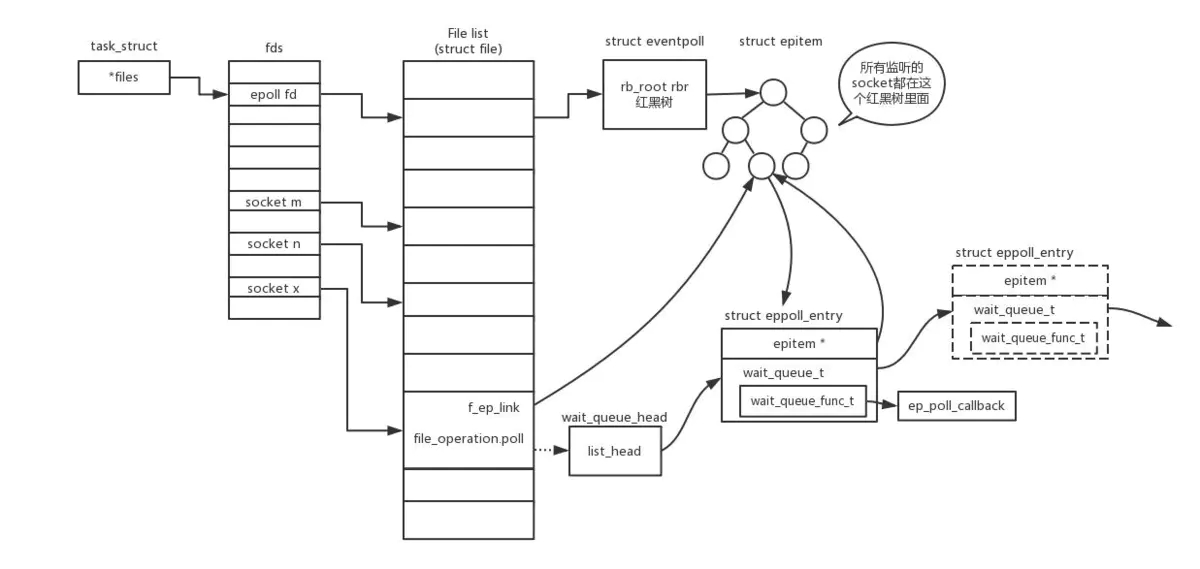
如图所示,假如进程打开了Socket m, n, x等多个文件描述符,现在需要通过epoll来监听是否这些Socket都有事件发生。其中epoll_create创建一个epoll对象,也是一个文件,也对应一个文件描述符,同样也对应着打开文件列表中的一项。在这项里面有一个红黑树,在红黑树里,要保存这个epoll要监听的所有Socket。
当epoll_ctl添加一个Socket的时候,其实是加入这个红黑树,同时红黑树里面的节点指向一个结构,将这个结构挂在被监听的Socket的事件列表中。当一个Socket来了一个事件的时候,可以从这个列表中得到epoll对象,并调用callback通知它。
这种通知方式使得监听的Socket数据增加的时候,效率不会大幅度降低,能够同时监听的Socket的数目也非常多了。上限就为系统定义的、进程打开的最大文件描述符个数。因此,epoll被称为解决C10K