一.数据类型及解析方式
一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值。内容一般分为两部分,非结构化的数据 和 结构化的数据。
- 非结构化数据:先有数据,再有结构,
- 结构化数据:先有结构、再有数据
- 不同类型的数据,我们需要采用不同的方式来处理。
1.非结构化的数据处理
文本、电话号码、邮箱地址
用:正则表达式
html文件
用:正则表达式 / xpath/css选择器/bs4
2.结构化的数据处理
json文件
用:jsonPath / 转化成Python类型进行操作(json类)
xml文件
用:转化成Python类型(xmltodict) / XPath / CSS选择器 / 正则表达式
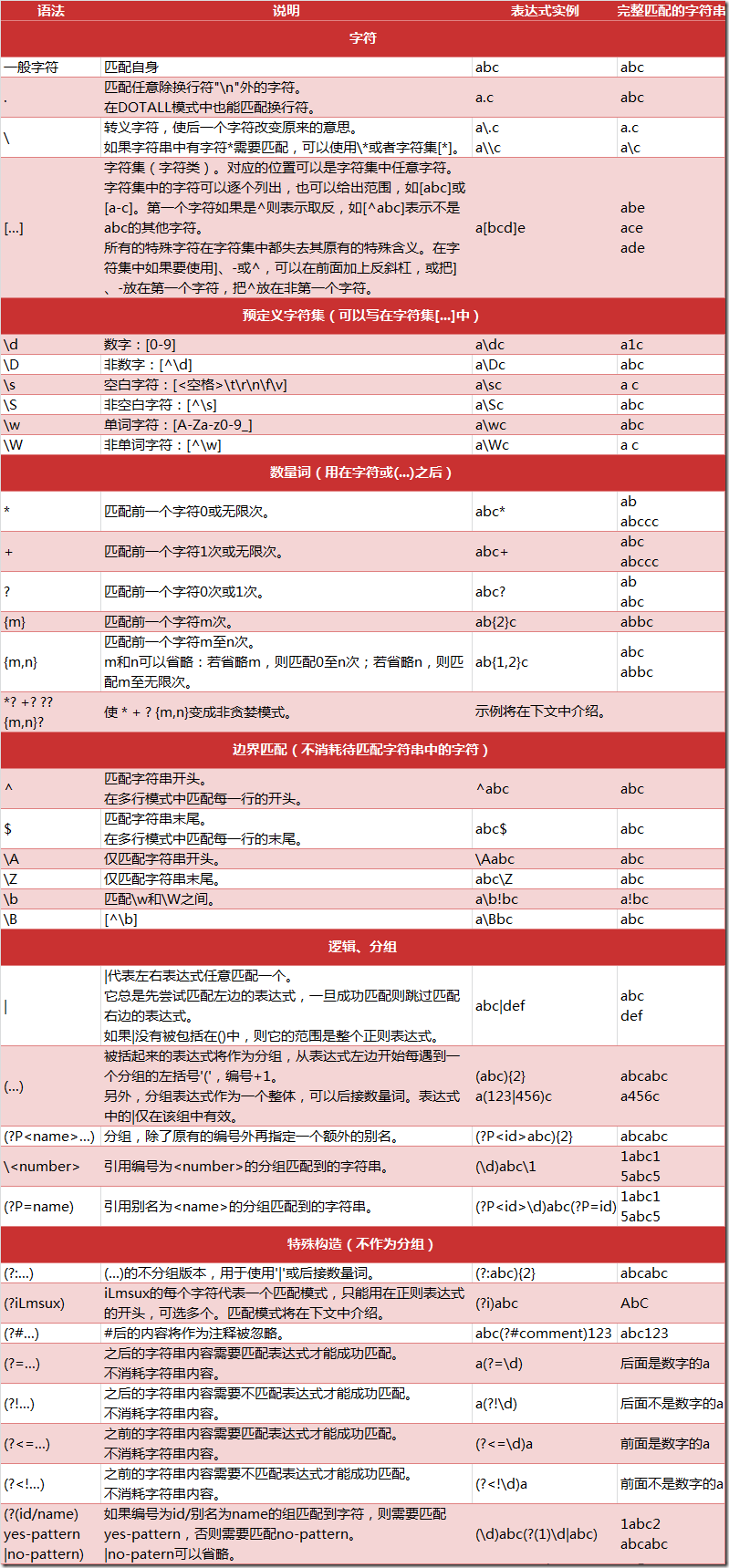
二.正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
正则表达式匹配规则