本文章只用于技术拓展,不得恶意破坏任何网站。
首先当我们拿到一个网站时,必须清楚知道我们需要的是什么数据,
然后带有目的性的去查看源代码的相关信息,直接进去主题。
我们要拿的是在售产品的每一个产品的全部数据(如图所示)

然后点开其中一个产品找到其中的一个产品,我们要拿的就是这里面的全部信息(如图所示)

我们观察发现每个产品的地址都是通过一个固定地址加一个id值构成的,只要拿到这些id值,就可以拿到这里面的数据了。现在需要做的就是拿到这些id。 回到首页,右键点击检查一个产品
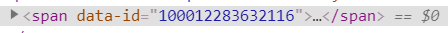
我们是可以看到每一个产品的id的,但通过bs.find_all发现拿到的数据并没有这些id值,很明显这是个动态网站,这些id值是后台传过来的,果然在network的xhr里找到了这些id

然后要做的就是分析headers的url

我们发现这个url是通过一个固定地址+一些参数组成的。在 Query String Parameters 我们找到了这些参数。
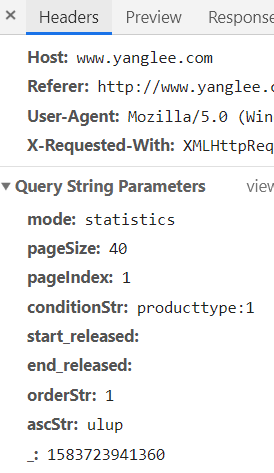
那么这些参数代表什么?分析一下,我们发现
‘mode’: ‘statistics’, (固定参数)
‘start_released’: ‘’,(固定参数)
‘end_released’: ‘’,(固定参数)
‘orderStr’: ‘1’,(固定参数)
‘ascStr’: ‘ulup’(固定参数)
‘pageSize’: ‘40’,(一页多少个产品)
‘pageIndex’: str(3), (显示第几页)
condition = ‘producttype:’+‘1’+’|status:在售’ (产品状态)
最后一个是个随机数,可以不加,影响不大
那么将这些参数和固定网址进行拼接,我们就可以进入第二层网页了
但是这里细心的你们一定会发现,在Request Headers这里多了一个Referer,

这个参数是告诉服务器该网页是从哪个页面链接过来的,服务器因此可以获得一些信息用于处理。那么如果我们从第二层网页直接访问的话,肯定不行,因此我们要在请求头加上这句
“Referer”: “http://www.yanglee.com/Product/Index.aspx”,让服务器以为我们是从第一层网页过来的。
现在来分析第二层网页,我们发现,我们要的数据是以列表的形式储存的。

这里用正则表达式我们就可以拿到要的数据了

这里我只是拿到数据,至于处理数据因人而异,我就不往下写了。
下面是具体代码
import requests
import re
import urllib.parse
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time
# 第一层拼接地址
def url_join(pageindex,pagesize,producttype,status):
# http://www.yanglee.com/Action/ProductAJAX.ashx?mode=statistics&pageSize=40&pageIndex=1&conditionStr=producttype%3A1%7Cstatus%3A%E5%9C%A8%E5%94%AE&start_released=&end_released=&orderStr=1&ascStr=ulup&_=1583631480607
url="http://www.yanglee.com/Action/ProductAJAX.ashx?"
arg={
'mode':'statistics',
'pageSize':pagesize,
'pageIndex':pageindex,
'conditionStr':"producttype:"+producttype+"|status"+status,
'start_released':'',
'end_released':'',
'orderStr':'1',
'ascStr':'ulup'
}
#参数解析
new_url=url+urllib.parse.urlencode(arg)
return new_url
# 数据爬取
def data_req(nurl):
ua = UserAgent()
header = {
"User-Agent": str(ua.random),
# 指向,发源地
"Referer": "http://www.yanglee.com/Product/Index.aspx"
}
myproxies = {
"HTTPS": "115.211.117.8",
"HTTPS": "218.76.253.201",
}
v_response= requests.get(nurl,headers=header,proxies=myproxies)
return v_response.text
# 第一层数据解析 返回第二层地址 (列表形式)
def first_parse(first_data):
second_url_list = []
result=re.findall('"ID":"(.*?)"',first_data)
for i in result:
url="http://www.yanglee.com/Product/Detail.aspx?id="+i
second_url_list.append(url)
return second_url_list
# 第二层数据爬取与解析
def second_req(second_url_list):
for i in second_url_list:
v_response=data_req(i)
bs=BeautifulSoup(v_response,'lxml')
html_bs = bs.find_all("table",{"border":"1"})
# print(html_bs)
# 产品所有标题的结果
tiile_results = re.findall('<td>(.*?)</td>', v_response.text)
title_result=tiile_results[:29]
print(title_result)
# 除了产品名称的结果
content_result=re.findall('<td class="pro-textcolor">(.*?)</td>',v_response.text)
print(content_result)
time.sleep(2)
def main():
nurl=url_join('1','2','1','在售')
first_data=data_req(nurl)
second_url_list=first_parse(first_data)
second_req(second_url_list)
if __name__ =='__main__':
main()
最后啰嗦一句,无论爬什么网站记得加个time.sleep(),友好相处嘛
