tensorflow自建数据集dataset使用
1 Dataset
tensorflow中提供了两个dataset的API,一个是做一个数据源,另一个是做一个管道用来不断提取数据。
tf.data.Dataset:表示一串元素(elements),其中每个元素包含了一或多个Tensor对象。例如:在一个图片pipeline中,一个元素可以是单个训练样本,它们带有一个表示图片数据的tensors和一个label组成的pair。有两种不同的方式创建一个dataset:
创建一个source (例如:Dataset.from_tensor_slices()), 从一或多个tf.Tensor对象中构建一个dataset
应用一个transformation(例如:Dataset.batch()),从一或多个tf.data.Dataset对象上构建一个dataset
tf.data.Iterator:它提供了主要的方式来从一个dataset中抽取元素。通过Iterator.get_next() 返回的该操作会yields出Datasets中的下一个元素,作为输入pipeline和模型间的接口使用。最简单的iterator是一个“one-shot iterator”,它与一个指定的Dataset相关联,通过它来进行迭代。对于更复杂的使用,Iterator.initializer操作可以使用不同的datasets重新初始化(reinitialize)和参数化(parameterize)一个iterator ,例如,在同一个程序中通过training data和validation data迭代多次。
2、tf.data.Dataset
一般我们可以从tensor序列直接导入到Dataset中,如下几个例子,直接是tensor
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random_uniform([4, 10]))
print(dataset1.output_types) # ==> "tf.float32"
print(dataset1.output_shapes) # ==> "(10,)"
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random_uniform([4]),
tf.random_uniform([4, 100], maxval=100, dtype=tf.int32)))
print(dataset2.output_types) # ==> "(tf.float32, tf.int32)"
print(dataset2.output_shapes) # ==> "((), (100,))"
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
print(dataset3.output_types) # ==> (tf.float32, (tf.float32, tf.int32))
print(dataset3.output_shapes) # ==> "(10, ((), (100,)))"
在做图像这方面时,我们可以把图像的path和标签导入,再进行批量处理,dataset有个map函数,对所有的数据执行同一函数,这样我们可以再读取图片,解码图片,resize等等。
def load_and_preprocess_from_path_label(path, label):
image = tf.read_file(path) # 读取图片
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize_image_with_crop_or_pad(image, args.img_height, args.img_width) # 原始图片大小为(266, 320, 3),重设为(192, 192)
# image /= 255.0 # 归一化到[0,1]范围
return image, label
dataset = dataset.map(load_and_preprocess_from_path_label)
3、创建iterator
创建完Dataset API,我们可以利用iterator访问数据,有四种iterator:
one-shot
initializable
reinitializable
feedable
3.1 make_one_shot_iterator()
one-shot iterator是最简单的iterator,它只支持在一个dataset上迭代一次的操作,不需要显式初始化。
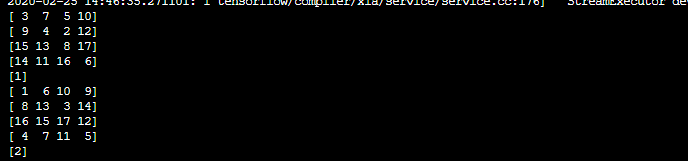
举个例子,我8个数据,就能遍历八次,我搞十次,当第9次就会报错。
import tensorflow as tf
data = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17]
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset = dataset.shuffle(8).batch(4).repeat()##不断重复,这样就可以遍历完数据继续遍历。
it = dataset.make_one_shot_iterator()
next_val = it.get_next()
with tf.Session() as sess:
for i in range(10):
print(sess.run(next_val))
结果:
因为有17个数据,遍历完一次,最后一次不够batch,就打出一个数,我在训练数据时,加了一个shape判断,shape等于batchsize,再feed,不然就再找下一个iterrator即可。
3.2 make_initializable_iterator()
initializable需要显式初始化,他可以对数据加上个参数,feed时候可以给参数。
4、举例
# read datasets
data_path = pathlib.Path(args.traindata_dir)
all_image_paths = list(data_path.glob('*.jpg'))
all_image_paths = [str(path) for path in all_image_paths] # 所有图片路径的列表
## 读取csv文件
all_image_labels = []
with open(args.label_path, 'r') as f:
reader = csv.reader(f)
first = True
for row in reader:
if first == True:
first = False
else:
all_image_labels.append(row[1])
## 打乱数据
random_index = []
for i in range(len(all_image_paths)):
random_index.append(i)
random.shuffle(random_index) # 打散
temp = []
temp2 = []
for i in range(len(random_index)):
temp.append(all_image_paths[random_index[i]])
temp2.append(all_image_labels[random_index[i]])
all_image_paths = temp
all_image_labels = temp2
## 创建dataset
dataset = tf.data.Dataset.from_tensor_slices((all_image_paths, all_image_labels))
def load_and_preprocess_from_path_label(path, label):
image = tf.read_file(path) # 读取图片
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize_image_with_crop_or_pad(image, args.img_height, args.img_width) # 原始图片大小为(266, 320, 3),重设为(192, 192)
# image /= 255.0 # 归一化到[0,1]范围
return image, label
dataset = dataset.map(load_and_preprocess_from_path_label)
dataset = dataset.shuffle(2 * args.train_batch_size).batch(args.train_batch_size).repeat()
iterator = dataset.make_initializable_iterator()
img_next = iterator.get_next()
训练时
sess.run(iterator.initializer)
print('Start training...')
for step in range(args.train_steps):
train_batch_data, train_batch_labels = sess.run(img_next)
if train_batch_data.shape[0] != args.train_batch_size:
train_batch_data, train_batch_labels = sess.run(img_next)
start_time = time.time()
