基础讲多了也不好,懂的人看了烦躁,半懂的人看多了没耐心,我也不能打消了你们学习Python的积极性了,开始爬虫系列基础篇之前,先上一张图,给大脑充充血:

很多人,学习Python,无非两个目的,一个就是纯粹玩(确实好玩),一个就是为了上面这张毛爷爷(确实能换钱),我是二者兼有,至少不清高,也不爱财。
在Python中,有一个模块,叫urllib,专门就是为了读取web页面中的数据,还记得Python的鸭子类型吗,“file-like object”,走起路子只要像鸭子,那么它就可以被当做鸭子。因此,我们可以像读写本地文件那样去读写web数据,只要拿到url,我们就可以拿到我们需要的对象,只要拿到对象,我们就可以赋予鸭子生命,从而享受美味的鸭肉(data)
直接上demo,说再多,不如敲一遍demo,亲自感受一下
getHtml.py
#!/usr/bin/env Python3
# -*- encoding:utf-8 *-*
'''@author = 'Appleyk' '''
'''@time = '2017年9月23日11:42:32' '''
from urllib import request
def getResponse(url):
#url请求对象 Request是一个类
url_request = request.Request(url)
print("这个对象的方法是:",url_request.get_method())
#上下文管理器,HTTPResponse 对象,包含一系列方法
url_response = request.urlopen(url) #打开一个url或者一个Request对象
'''
geturl():返回 full_url地址
info(): 返回页面的元(Html的meta标签)信息
<meta>:可提供有关页面的元信息(meta-information),比如针对搜索引擎和更新频度的描述和关键词。
getcode(): 返回响应的HTTP状态代码
100-199 用于指定客户端应相应的某些动作。
200-299 用于表示请求成功。 ------> 200
300-399 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息。
400-499 用于指出客户端的错误。 ------> 404
500-599 用于支持服务器错误。
read(): 读取网页内容,注意解码方式(避免中文和utf-8之间转化出现乱码)
'''
return url_response #返回这个对象
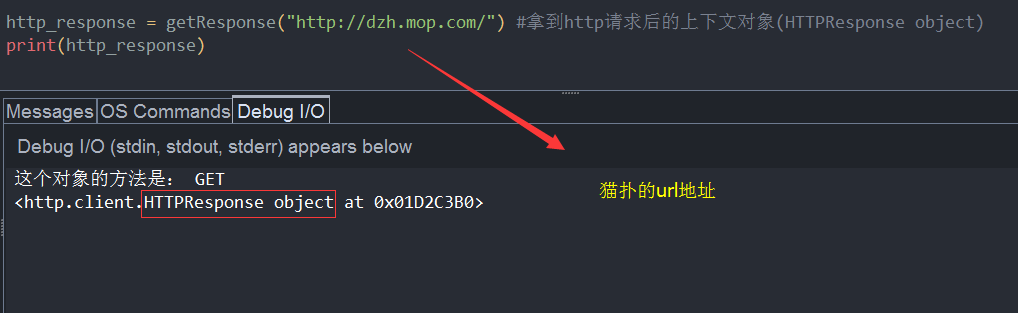
http_response = getResponse("http://dzh.mop.com/") #拿到http请求后的上下文对象(HTTPResponse object)
print(http_response) #打印这个对象执行的结果,我们等会再放出来,我们先来介绍一下,urllib模块的request功能。
(1)首先你得去请求一个url地址(网址),拿到Request对象,或者你不拿到Request的对象,直接在第二步中,使用url地址(字符串)也行
(2)其次,你要将这个Reques对象作为request.urlopen函数的参数,以获得请求后的http上下文对象,也就是http response对象,这个对象,还是很有料的,正是我们所需要的,当然,参数也可以直接是一个url字符串。
我们借助Python自带的解析器,利用help函数,参照原形,对(1)和(2)中提到的内容做进一步说明
url_request = request.Request(url)
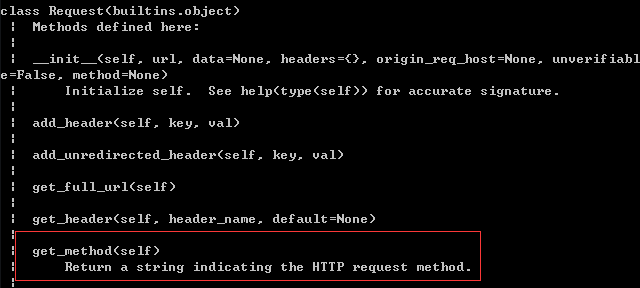
url_response = request.urlopen(url) 或者 url_response = request.urlopen(url_request)

打开一个URL类型的 url,既可以是一个字符串也可以是一个Request对象
函数总是返回一个对象,一个可以工作的上下文管理器,其中具有的方法如下
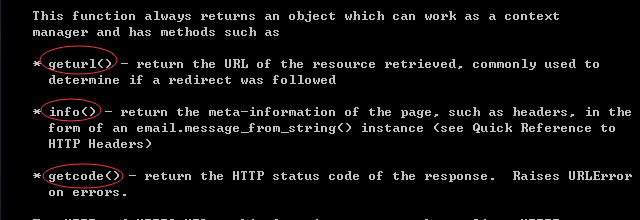
具体说明,看demo里面的注释,下面,我们来打印一下这个response对象
使用HTTPResponse对象的方法
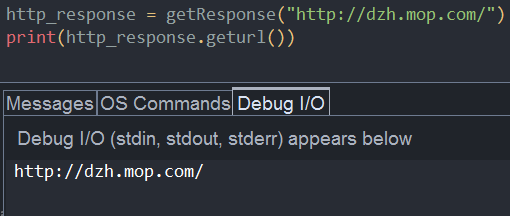
A、geturl()
B、 info()
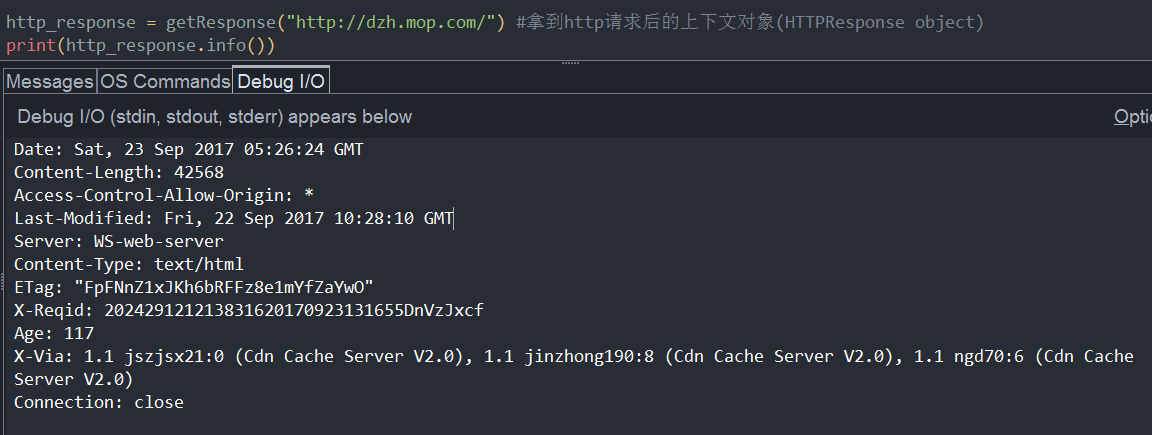
C、getcode()
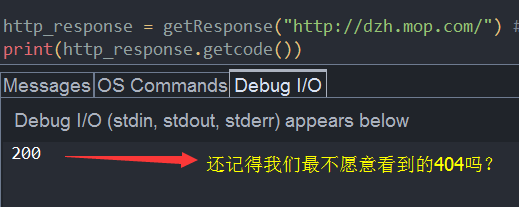
D、read()
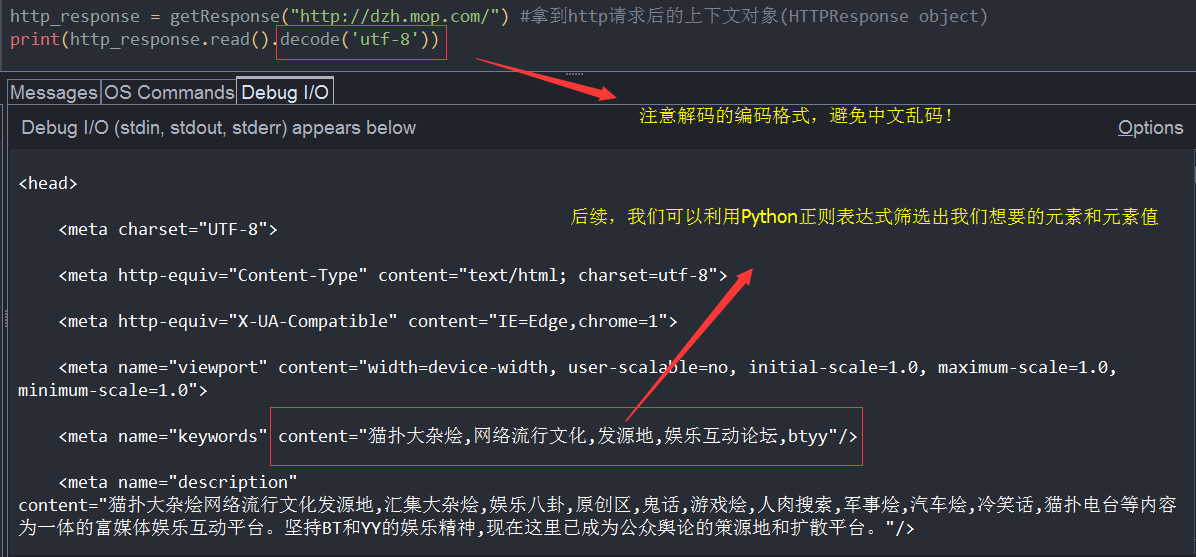
我们拿到了网页内容,我们要干嘛呢? 我们翻一下,这个网页,看能不能找到一些图片的url信息(当然,博主肯定是事先在浏览其中打开了这个url地址,不然,我们怎么能返回200呢!)

还真有,但是有多少个呢,我们引入re模板库,使用正则表达式,列出来这些xxxxxx.jpg有多少个(何必亲自一个个去数呢),demo改进如下:
getHtml.py:
#!/usr/bin/env Python3
# -*- encoding:utf-8 *-*
'''@author = 'Appleyk' '''
'''@time = '2017年9月23日11:42:32' '''
from urllib import request
import re #使用正则表达式
def getResponse(url):
#url请求对象 Request是一个类
url_request = request.Request(url)
#print("Request对象的方法是:",url_request.get_method())
#上下文使用的对象,包含一系列方法
#url_response = request.urlopen(url) #打开一个url或者一个Request对象
url_response = request.urlopen(url_request)
'''
geturl():返回 full_url地址
info(): 返回页面的元(Html的meta标签)信息
<meta>:可提供有关页面的元信息(meta-information),比如针对搜索引擎和更新频度的描述和关键词。
getcode(): 返回响应的HTTP状态代码
100-199 用于指定客户端应相应的某些动作。
200-299 用于表示请求成功。 ------> 200
300-399 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息。
400-499 用于指出客户端的错误。 ------> 404
500-599 用于支持服务器错误。
read(): 读取网页内容,注意解码方式(避免中文和utf-8之间转化出现乱码)
'''
return url_response #返回这个对象
def getJpg(data):
jpglist = re.findall(r'src="http.+?.jpg"',data)
return jpglist
http_response = getResponse("http://dzh.mop.com/") #拿到http请求后的上下文对象(HTTPResponse object)
#print(http_response.read().decode('utf-8'))
data = http_response.read().decode('utf-8')
L = getJpg(data)
global n #声明全局变量n
n = 1
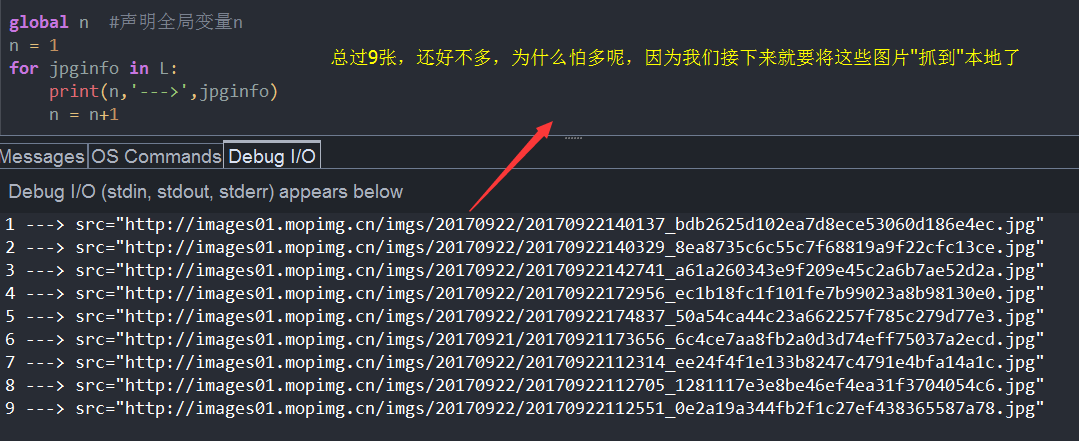
for jpginfo in L:
print(n,'--->',jpginfo)
n = n+1
执行下,看下效果:
怎么下载到本地呢?很简单,urllib模板库,给我们提供的有现成的方法,如下
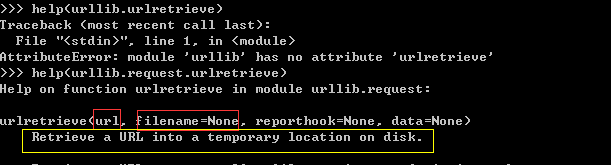
request的方法urlretrieve,只需要传前两个参数,一个是图片的url地址,一个是图片的本地文件名称
方法说明:............指向本地磁盘,说白了就是下载
注意,我们要的不是
src="http://images01.mopimg.cn/imgs/20170922/20170922112551_0e2a19a344fb2f1c27ef438365587a78.jpg"
而是src的值--->
http://images01.mopimg.cn/imgs/20170922/20170922112551_0e2a19a344fb2f1c27ef438365587a78.jpg
因此,我们需要在上述demo的基础上再定义一个下载方法,给urlretrieve函数传第一个参数的时候,需要再次用到正则表达式,来得到真正意义上的 url 图片 地址!
直接上终极demo,如下
gethtml.py:
#!/usr/bin/env Python3
# -*- encoding:utf-8 *-*
'''@author = 'Appleyk' '''
'''@time = '2017年9月23日11:42:32' '''
from urllib import request
import re #使用正则表达式
def getResponse(url):
#url请求对象 Request是一个类
url_request = request.Request(url)
#print("Request对象的方法是:",url_request.get_method())
#上下文使用的对象,包含一系列方法
#url_response = request.urlopen(url) #打开一个url或者一个Request对象
url_response = request.urlopen(url_request)
'''
geturl():返回 full_url地址
info(): 返回页面的元(Html的meta标签)信息
<meta>:可提供有关页面的元信息(meta-information),比如针对搜索引擎和更新频度的描述和关键词。
getcode(): 返回响应的HTTP状态代码
100-199 用于指定客户端应相应的某些动作。
200-299 用于表示请求成功。 ------> 200
300-399 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息。
400-499 用于指出客户端的错误。 ------> 404
500-599 用于支持服务器错误。
read(): 读取网页内容,注意解码方式(避免中文和utf-8之间转化出现乱码)
'''
return url_response #返回这个对象
def getJpg(data):
jpglist = re.findall(r'src="http.+?.jpg"',data)
return jpglist
def downLoad(jpgUrl,n):
#request.urlretrieve(jpg_link, path)
try:
request.urlretrieve(jpgUrl,'%s.jpg' %n)
except Exception as e:
print(e)
finally:
print('图片%s下载操作完成' % n)
http_response = getResponse("http://dzh.mop.com/") #拿到http请求后的上下文对象(HTTPResponse object)
#print(http_response.read().decode('utf-8'))
data = http_response.read().decode('utf-8')
#print(data)
global n
n = 1
L = getJpg(data)
for jpginfo in L:
print(jpginfo)
s = re.findall(r'http.+?.jpg',jpginfo)
downLoad(s[0],n)
n= n +1
没执行demo下载之前,我们看一下我们当前的可执行路径
来,我们执行一下demo,真是满怀期待,有点小忐忑
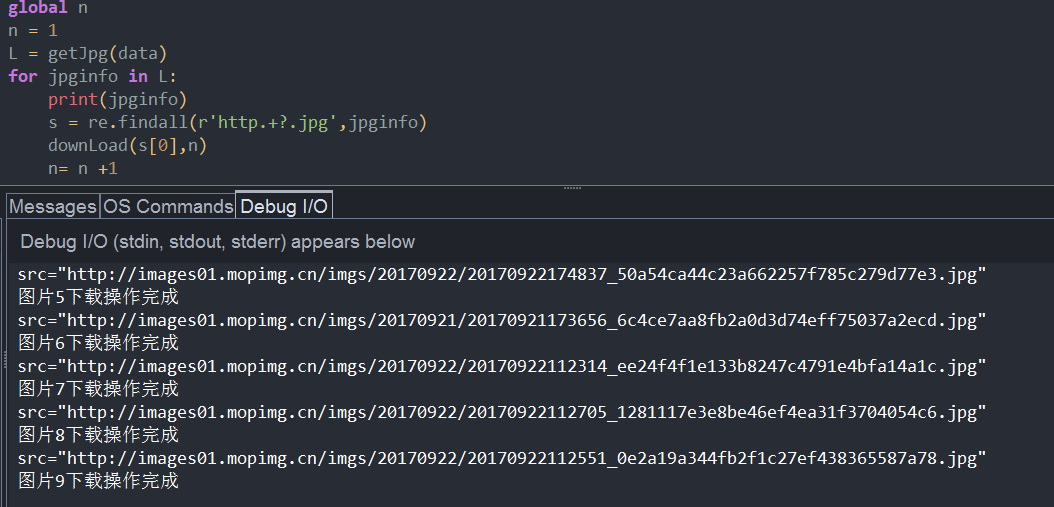
如果,你的网速很快的话,效果就是刷刷刷的,如果你的网速比较慢,这个效果就是一个个蹦出来的,我们检查一下,是不是真的下载下来了(我保证,最开始的url地址里面的图片,我没看过!)
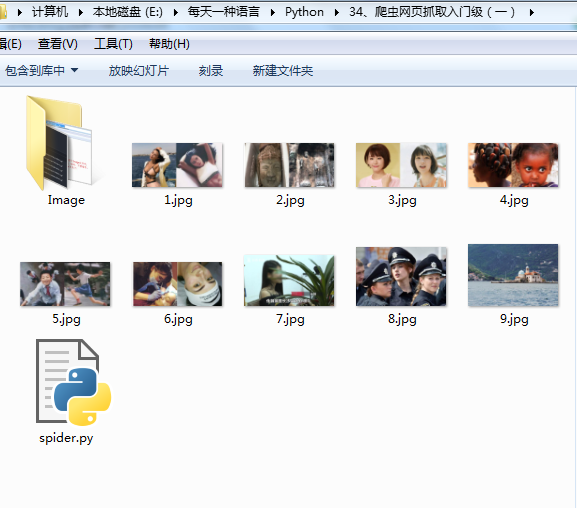
美女警察在哪呢,在这儿呢,我们放大看

本篇作为一个入门级的爬虫案例,意在说明,想要抓取web资源,必须先要进行url请求,然后就是一系列的对象操作,为什么是入门级的呢?
(1)不涉及url循环遍历
(2)不涉及多线程
(3)不涉及复杂正则表达式
(4)不涉及算法
(5)不涉及数据层面的存储
(6)不涉及网络带宽
(7)..................................
等等等等,我们初学Python的时候,一上来就想要搞什么爬虫,你写爬虫,我写蜘蛛,反正都是虫子,我只想说,没有那么简单,如果毛爷爷人人都好挣了,那就没什么技术可言了。 因此,打好基础很重要,入门思想的培养很重要,心里不浮躁也很重要,总之,在没有两把刷子之前,老老实实多看,多写,多敲,多思考,借鉴别人的思想,来发挥自己的长处,有朝一日,你也是虫师!
